faster rcnn.pytorch
1.0.0
[29/05/2020] Ce dépôt a été initié il y a environ deux ans, développé comme le premier code de détection d'objets open-open qui prend en charge la formation multi-GPU. Il a intégré d'énormes efforts de la part de nombreuses personnes. Cependant, nous avons vu de nombreux reposs de haute qualité émerger au cours des dernières années, tels que:
À ce stade, je pense que ce repo est hors de données en termes de pipeline et de style de codage, et ne maintiendra pas activement. Bien que vous puissiez toujours utiliser ce référentiel comme aire de jeux, je vous recommande fortement de vous déplacer vers les références ci-dessus pour plonger dans le monde ouest de la détection d'objets!
Ce projet est une implémentation Pytorch plus rapide de R-CNN plus rapide, visant à accélérer la formation de modèles de détection d'objets R-CNN plus rapides. Récemment, il existe un certain nombre de bonnes implémentations:
rbgirshick / py-faster-rcnn, développé basé sur pycaffe + numpy
Longcw / Faster_RCNN_PYTORCH, développé basé sur Pytorch + Numpy
Enchenewton / TF-Faster-RCNN, développé basé sur TensorFlow + Numpy
Ruotianluo / Pytorch-Faster-RCNN, développé basé sur Pytorch + Tensorflow + Numpy
Au cours de notre implémentation, nous avons référé les implémentations ci-dessus, en particulier LongCW / Faster_RCNN_PYTORCH. Cependant, notre implémentation a plusieurs fonctionnalités uniques et nouvelles par rapport aux implémentations ci-dessus:
C'est un code pytorch pur . Nous convertissons toutes les implémentations Numpy en Pytorch!
Il prend en charge la formation par lots multi-images . Nous révisons toutes les couches, y compris DatalOader, RPN, ROI-poooling, etc., pour prendre en charge plusieurs images dans chaque minibatch.
Il prend en charge plusieurs GPUS de formation . Nous utilisons un emballage GPU multiple (NN.Dataparalleal ici) pour le rendre flexible pour utiliser un ou plusieurs GPU, comme mérite des deux fonctionnalités ci-dessus.
Il prend en charge trois méthodes de mise en commun . Nous intégrons trois méthodes de mise en commun: le caca ROI, le ROI Align et le ROI Crop. Plus important encore, nous les modifions tous pour prendre en charge la formation par lots multi-images.
Il est efficace de la mémoire . Nous limitons le rapport d'aspect de l'image et les images de groupe avec des rapports d'aspect similaires dans un minibatch. En tant que tel, nous pouvons former Resnet101 et VGG16 avec BatchSize = 4 (4 images) sur un seul Titan X (12 Go). Lors de l'entraînement avec 8 GPU, le lot maximum pour chaque GPU est de 3 (RES101), totalisant 24.
C'est plus rapide . Sur la base des modifications ci-dessus, la formation est beaucoup plus rapide. Nous rapportons la vitesse d'entraînement sur Nvidia Titan XP dans les tableaux ci-dessous.
Caractéristique Pyramid Network (FPN)
Masque r-cnn ( en cours Déjà implémenté par RoytEng-TW)
Graphique R-CNN (extension de la génération de graphiques de scène)
Nous comptons soigneusement notre code sur trois ensembles de données: Pascal VOC, Coco et Visual Genome, en utilisant deux architectures de réseau différentes: VGG16 et RESNET101. Voici les résultats:
1). Pascal COV 2007 (train / test: 07Trainval / 07test, échelle = 600, ROI Align)
| modèle | #Gpus | taille de lot | LR | LR_DECAY | max_epoch | Temps / époque | MEM / GPU | carte |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 | 1 | 1E-3 | 5 | 6 | 0,76 h | 3265 Mo | 70.1 |
| VGG-16 | 1 | 4 | 4E-3 | 8 | 9 | 0,50 h | 9083 Mo | 69.6 |
| VGG-16 | 8 | 16 | 1E-2 | 8 | 10 | 0,19 h | 5291 Mo | 69.4 |
| VGG-16 | 8 | 24 | 1E-2 | 10 | 11 | 0,16 h | 11303 Mo | 69.2 |
| RES-101 | 1 | 1 | 1E-3 | 5 | 7 | 0,88 h | 3200 MB | 75.2 |
| RES-101 | 1 | 4 | 4E-3 | 8 | 10 | 0,60 h | 9700 MB | 74.9 |
| RES-101 | 8 | 16 | 1E-2 | 8 | 10 | 0,23 h | 8400 MB | 75.2 |
| RES-101 | 8 | 24 | 1E-2 | 10 | 12 | 0,17 h | 10327 Mo | 75.1 |
2). Coco (train / test: coco_train + coco_val-minival / minival, échelle = 800, max_size = 1200, roi align)
| modèle | #Gpus | taille de lot | LR | LR_DECAY | max_epoch | Temps / époque | MEM / GPU | carte |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 8 | 16 | 1E-2 | 4 | 6 | 4.9 HR | 7192 MB | 29.2 |
| RES-101 | 8 | 16 | 1E-2 | 4 | 6 | 6,0 h | 10956 MB | 36.2 |
| RES-101 | 8 | 16 | 1E-2 | 4 | 10 | 6,0 h | 10956 MB | 37.0 |
NOTE . Étant donné que les modèles ci-dessus utilisent l'échelle = 800, vous avez besoin d'ajouter "- ls" à la fin de la commande de test.
3). Coco (train / test: coco_train + coco_val-minival / minival, échelle = 600, max_size = 1000, roi align)
| modèle | #Gpus | taille de lot | LR | LR_DECAY | max_epoch | Temps / époque | MEM / GPU | carte |
|---|---|---|---|---|---|---|---|---|
| RES-101 | 8 | 24 | 1E-2 | 4 | 6 | 5.4 HR | 10659 MB | 33.9 |
| RES-101 | 8 | 24 | 1E-2 | 4 | 10 | 5.4 HR | 10659 MB | 34.5 |
4). Génome visuel (train / test: vg_train / vg_test, échelle = 600, max_size = 1000, roi align, catégorie = 2500)
| modèle | #Gpus | taille de lot | LR | LR_DECAY | max_epoch | Temps / époque | MEM / GPU | carte |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 P100 | 4 | 1E-3 | 5 | 20 | 3,7 h | 12707 MB | 4.4 |
Merci à Remi d'avoir fourni le modèle de détection pré-entraîné sur le génome visuel!
Tout d'abord, clonez le code
git clone https://github.com/jwyang/faster-rcnn.pytorch.git
Ensuite, créez un dossier:
cd faster-rcnn.pytorch && mkdir data
PASCAL_VOC 07 + 12 : Veuillez suivre les instructions dans PY-Faster-RCNN pour préparer des ensembles de données COV. En fait, vous pouvez vous référer à d'autres. Après avoir téléchargé les données, créez des links Soft dans les données du dossier /.
Coco : Veuillez également suivre les instructions dans PY-Faster-RCNN pour préparer les données.
Génome visuel : veuillez suivre les instructions de l'attention ascendante pour préparer l'ensemble de données du génome visuel. Vous devez d'abord télécharger les images et les fichiers d'annotation d'objets, puis effectuer la propriété pour obtenir le vocabulaire et les annotations nettoyées en fonction des scripts fournis dans ce référentiel.
Nous avons utilisé deux modèles pré-entraînés dans nos expériences, VGG et RESNET101. Vous pouvez télécharger ces deux modèles à partir de:
VGG16: Dropbox, VT Server
Resnet101: Dropbox, VT Server
Téléchargez-les et mettez-les dans les données / prétrained_model /.
NOTE . Nous comparons les modèles pré-entraînés de Pytorch et de la Caffe, et trouvons étonnamment les modèles de CAFE pré-TRAPED ont des performances légèrement meilleures que Pytorch pré-entraîné. Nous suggérons d'utiliser des modèles de CAFE pré-entraînés à partir du lien ci-dessus pour reproduire nos résultats.
Si vous souhaitez utiliser des modèles pré-formés Pytorch, n'oubliez pas de transposer des images de BGR à RVB, et utilisez également le même transformateur de données (moins la moyenne et la normalisation) comme utilisé dans le modèle pré-entraîné.
Comme indiqué par Ruotianluo / Pytorch-Faster-RCNN, choisissez le bon -arch dans le fichier make.sh , pour compiler le code CUDA:
| Modèle GPU | Architecture |
|---|---|
| Titanx (Maxwell / Pascal) | SM_52 |
| GTX 960m | SM_50 |
| GTX 1080 (TI) | SM_61 |
| Grid K520 (AWS G2.2xlarge) | SM_30 |
| Tesla K80 (AWS P2.xlarge) | SM_37 |
Plus de détails sur la définition de l'architecture peuvent être trouvés ici ou ici
Installez toutes les dépendances Python à l'aide de PIP:
pip install -r requirements.txt
Compilez les dépendances CUDA en utilisant les commandes simples suivantes:
cd lib
sh make.sh
Il compilera tous les modules dont vous avez besoin, y compris NMS, ROI_POOING, ROI_ALIGN et ROI_CROP. La version par défaut est compilée avec Python 2.7, veuillez compiler par vous-même si vous utilisez une version Python différente.
Comme indiqué dans ce numéro, si vous rencontrez une erreur pendant la compilation, vous pourriez manquer d'exporter les chemins CUDA vers votre environnement.
Avant l'entraînement, définissez le bon répertoire pour enregistrer et charger les modèles formés. Modifiez les arguments "Save_Dir" et "Load_Dir" dans Trainval_net.py et test_net.py pour s'adapter à votre environnement.
Pour entraîner un modèle R-CNN plus rapide avec VGG16 sur Pascal_Voc, exécutez simplement:
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net vgg16
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
où 'bs' est la taille du lot avec la valeur par défaut 1. Alternativement, pour s'entraîner avec RESNET101 sur Pascal_Voc, Run simple:
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net res101
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
Ci-dessus, Batch_Size et Worker_Number peuvent être définis de manière adaptative en fonction de la taille de la mémoire GPU. Sur Titan XP avec mémoire 12G, il peut être jusqu'à 4 .
Si vous avez plusieurs GPU Titan XP (Say 8), alors utilisez-les tous! Essayer:
python trainval_net.py --dataset pascal_voc --net vgg16
--bs 24 --nw 8
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda --mGPUs
Changer un ensemble de données en "CoCo" ou 'VG' si vous souhaitez vous entraîner sur Coco ou Visual Genome.
Si vous souhaitez évaluer les performances de détection d'un modèle VGG16 pré-formé sur l'ensemble de tests PASCAL_VOC, exécutez simplement
python test_net.py --dataset pascal_voc --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda
Spécifiez la session de modèle spécifique, CheckEpoch et Checkpoint, par exemple, session = 1, Epoch = 6, Checkpoint = 416.
Si vous souhaitez exécuter la détection sur vos propres images avec un modèle pré-formé, téléchargez le modèle pré-entraîné répertorié dans les tables ci-dessus ou entraînez vos propres modèles au début, puis ajoutez des images au dossier $ root / images, puis exécutez
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
Ensuite, vous trouverez les résultats de détection dans le dossier $ root / images.
Remarquez le Demo.py par défaut, il suffit de prendre en charge les catégories PASCAL_VOC. Vous devez changer la ligne pour adapter votre propre modèle.
Vous trouverez ci-dessous quelques résultats de détection:
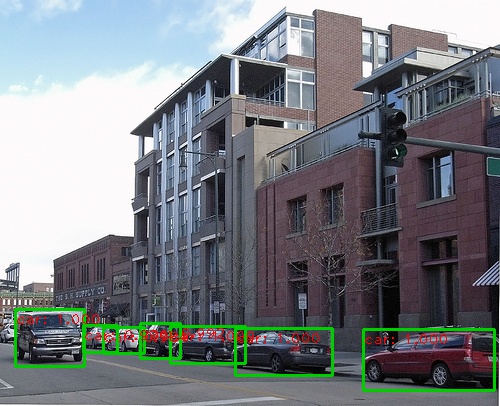

Vous pouvez utiliser une webcam dans une démo en temps réel en exécutant
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
--webcam $WEBCAM_ID
La démo est arrêtée en cliquant sur la fenêtre de l'image puis en appuyant sur la touche «Q».
Ce projet est également apporté par Jianwei Yang et Jiasen Lu, et bien d'autres (grâce à eux!).
@article{jjfaster2rcnn,
Author = {Jianwei Yang and Jiasen Lu and Dhruv Batra and Devi Parikh},
Title = {A Faster Pytorch Implementation of Faster R-CNN},
Journal = {https://github.com/jwyang/faster-rcnn.pytorch},
Year = {2017}
}
@inproceedings{renNIPS15fasterrcnn,
Author = {Shaoqing Ren and Kaiming He and Ross Girshick and Jian Sun},
Title = {Faster {R-CNN}: Towards Real-Time Object Detection
with Region Proposal Networks},
Booktitle = {Advances in Neural Information Processing Systems ({NIPS})},
Year = {2015}
}


