faster rcnn.pytorch
1.0.0
[29/05/2020] Este repositorio se inició hace unos dos años, desarrollado como el primer código de detección de objetos de origen abierto que admite la capacitación de múltiples GPU. Ha estado integrando enormes esfuerzos de muchas personas. Sin embargo, hemos visto que surgieron muchos repos de alta calidad en los últimos años, como:
En este punto, creo que este repositorio está fuera de los datos en términos de la tubería y el estilo de codificación, y no se mantendrá activamente. Aunque aún puede usar este repositorio como un patio de recreo, le recomiendo que se mude a los reposos anteriores para profundizar en el mundo oeste de la detección de objetos.
Este proyecto es una implementación de Pytorch más rápida de R-CNN más rápida, con el objetivo de acelerar la capacitación de modelos de detección de objetos R-CNN más rápidos. Recientemente, hay una serie de buenas implementaciones:
rbgirshick/py-faster-rcnn, desarrollado basado en Pycaffe + Numpy
Longcw/FASTER_RCNN_PYTORCH, desarrollado basado en Pytorch + Numpy
Endernewton/TF Faster-RCNN, desarrollado basado en TensorFlow + Numpy
Ruotianluo/Pytorch-Faster-Rcnn, desarrollado basado en Pytorch + TensorFlow + Numpy
Durante nuestra implementación, remitimos las implementaciones anteriores, especialmente Longcw/Faster_RCNN_Pytorch. Sin embargo, nuestra implementación tiene varias características únicas y nuevas en comparación con las implementaciones anteriores:
Es un código de pytorch puro . ¡Convertimos todas las implementaciones numpy a Pytorch!
Admite entrenamiento por lotes de imágenes múltiples . Revisamos todas las capas, incluidas Dataloader, RPN, Poi-Pooling, etc., para admitir múltiples imágenes en cada minibatch.
Admite múltiples capacitación en GPU . Utilizamos un envoltorio de GPU múltiple (NN.Dataparallel aquí) para que sea flexible usar una o más GPU, como un mérito de las dos características anteriores.
Admite tres métodos de agrupación . Integramos tres métodos de agrupación: caca de ROI, alineación de ROI y cultivo de ROI. Más importante aún, los modificamos a todos para admitir la capacitación por lotes de múltiples imágenes.
Es de memoria eficiente . Limitamos la relación de aspecto de la imagen y las imágenes grupales con relaciones de aspecto similares en un minibatch. Como tal, podemos entrenar ResNet101 y VGG16 con BatchSize = 4 (4 imágenes) en un solo Titan X (12 GB). Al entrenar con 8 GPU, el lote máximo para cada GPU es 3 (Res101), totalizando 24.
Es más rápido . Basado en las modificaciones anteriores, el entrenamiento es mucho más rápido. Reportamos la velocidad de entrenamiento en Nvidia Titan XP en las tablas a continuación.
Network Pyramid de funciones (FPN)
Máscara R-CNN ( en curso ya implementado por Roytseng-TW)
Gráfico R-CNN (Extensión a la generación de gráficos de escena)
Benchamos nuestro código a fondo en tres conjuntos de datos: Pascal VOC, Coco y Genoma visual, utilizando dos arquitecturas de red diferentes: VGG16 y ResNet101. A continuación se presentan los resultados:
1). Pascal VOC 2007 (Train/Prueba: 07Trainval/07Test, Escala = 600, ROI Align)
| modelo | #GPUS | tamaño por lotes | LR | lr_decay | max_epoch | tiempo/época | MEM/GPU | mapa |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 | 1 | 1e-3 | 5 | 6 | 0.76 horas | 3265MB | 70.1 |
| VGG-16 | 1 | 4 | 4E-3 | 8 | 9 | 0.50 hr | 9083MB | 69.6 |
| VGG-16 | 8 | 16 | 1e-2 | 8 | 10 | 0.19 hr | 5291mb | 69.4 |
| VGG-16 | 8 | 24 | 1e-2 | 10 | 11 | 0.16 hr | 11303MB | 69.2 |
| Res-101 | 1 | 1 | 1e-3 | 5 | 7 | 0.88 hr | 3200 MB | 75.2 |
| Res-101 | 1 | 4 | 4E-3 | 8 | 10 | 0.60 hr | 9700 MB | 74.9 |
| Res-101 | 8 | 16 | 1e-2 | 8 | 10 | 0.23 hr | 8400 MB | 75.2 |
| Res-101 | 8 | 24 | 1e-2 | 10 | 12 | 0.17 hr | 10327mb | 75.1 |
2). Coco (Train/Test: Coco_Train+Coco_Val-Minival/Minival, Scale = 800, Max_Size = 1200, ROI Align)
| modelo | #GPUS | tamaño por lotes | LR | lr_decay | max_epoch | tiempo/época | MEM/GPU | mapa |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 8 | 16 | 1e-2 | 4 | 6 | 4.9 hr | 7192 MB | 29.2 |
| Res-101 | 8 | 16 | 1e-2 | 4 | 6 | 6.0 h. | 10956 MB | 36.2 |
| Res-101 | 8 | 16 | 1e-2 | 4 | 10 | 6.0 h. | 10956 MB | 37.0 |
NOTA . Dado que los modelos anteriores usan escala = 800, necesita agregar "--ls" al final del comando de prueba.
3). Coco (Train/Test: Coco_Train+Coco_Val-Minival/Minival, Scale = 600, Max_Size = 1000, ROI Aline)
| modelo | #GPUS | tamaño por lotes | LR | lr_decay | max_epoch | tiempo/época | MEM/GPU | mapa |
|---|---|---|---|---|---|---|---|---|
| Res-101 | 8 | 24 | 1e-2 | 4 | 6 | 5.4 h. | 10659 MB | 33.9 |
| Res-101 | 8 | 24 | 1e-2 | 4 | 10 | 5.4 h. | 10659 MB | 34.5 |
4). Visual Genome (Train/Test: VG_Train/VG_Test, Scale = 600, Max_Size = 1000, ROI Align, Category = 2500)
| modelo | #GPUS | tamaño por lotes | LR | lr_decay | max_epoch | tiempo/época | MEM/GPU | mapa |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 P100 | 4 | 1e-3 | 5 | 20 | 3.7 h. | 12707 MB | 4.4 |
¡Gracias a Remi por proporcionar el modelo de detección previa a la aparición en el genoma visual!
En primer lugar, clona el código
git clone https://github.com/jwyang/faster-rcnn.pytorch.git
Luego, cree una carpeta:
cd faster-rcnn.pytorch && mkdir data
PASCAL_VOC 07+12 : Siga las instrucciones en Py-Faster-RCNN para preparar conjuntos de datos VOC. En realidad, puedes referirte a cualquier otro. Después de descargar los datos, cree SoftLinks en los datos de la carpeta/.
Coco : Siga también las instrucciones en Py Faster-RCNN para preparar los datos.
Genoma visual : siga las instrucciones en la atención de abajo hacia arriba para preparar el conjunto de datos del genoma visual. Primero debe descargar las imágenes y los archivos de anotación de objetos, y luego realizar una protección para obtener el vocabulario y las anotaciones limpias basadas en los scripts proporcionados en este repositorio.
Utilizamos dos modelos previos a la petróleo en nuestros experimentos, VGG y ResNet101. Puede descargar estos dos modelos de:
VGG16: Dropbox, VT Server
Resnet101: dropbox, servidor VT
Descárgalos y póngalos en los datos/Pretherened_Model/.
NOTA . Comparamos los modelos previos a los pytorch y el café, y sorprendentemente encontramos que los modelos previos al caffe tienen un rendimiento ligeramente mejor que el pytorch previado. Sugeriríamos usar modelos de caffe previos al enlace anterior para reproducir nuestros resultados.
Si desea utilizar modelos previamente capacitados de Pytorch, recuerde transponer las imágenes de BGR a RGB, y también use el mismo transformador de datos (menos media y normalización) que se usa en el modelo previo al estado previo.
Como lo señaló Ruotianluo/Pytorch-Faster-Rcnn, elija el -arch correcto en el archivo make.sh , para compilar el código CUDA:
| Modelo GPU | Arquitectura |
|---|---|
| Titanx (Maxwell/Pascal) | SM_52 |
| GTX 960m | SM_50 |
| GTX 1080 (TI) | SM_61 |
| Grid K520 (AWS G2.2xLarge) | SM_30 |
| Tesla K80 (AWS P2.xlarge) | SM_37 |
Se pueden encontrar más detalles sobre la configuración de la arquitectura aquí o aquí
Instale todas las dependencias de Python usando PIP:
pip install -r requirements.txt
Compile las dependencias CUDA utilizando los siguientes comandos simples:
cd lib
sh make.sh
Compilará todos los módulos que necesita, incluidos NMS, Roi_pooing, Roi_align y ROI_CROP. La versión predeterminada se compila con Python 2.7, compile usted mismo si está utilizando una versión de Python diferente.
Como se señaló en este tema, si encuentra algún error durante la compilación, puede perderse exportar las rutas CUDA a su entorno.
Antes del entrenamiento, configure el directorio correcto para guardar y cargar los modelos entrenados. Cambie los argumentos "Save_dir" y "Load_dir" en Trainval_net.py y test_net.py para adaptarse a su entorno.
Para entrenar un modelo R-CNN más rápido con VGG16 en PASCAL_VOC, simplemente ejecute:
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net vgg16
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
donde 'bs' es el tamaño de lote con el valor predeterminado 1. Alternativamente, para entrenar con resnet101 en PASCAL_VOC, Simple Run:
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net res101
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
Arriba, Batch_Size y Worker_Number se pueden configurar adaptivamente de acuerdo con el tamaño de la memoria de su GPU. En Titan XP con memoria 12G, puede ser de hasta 4 .
Si tiene múltiples (digamos 8) GPU de Titan XP, ¡simplemente úselas todas! Intentar:
python trainval_net.py --dataset pascal_voc --net vgg16
--bs 24 --nw 8
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda --mGPUs
Cambie el conjunto de datos a "Coco" o 'VG' si desea entrenar en Coco o Genoma visual.
Si desea evaluar el rendimiento de detección de un modelo VGG16 previamente entrenado en el conjunto de pruebas PASCAL_VOC, simplemente ejecute
python test_net.py --dataset pascal_voc --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda
Especifique la sesión de modelo específica, Checkepoch y Checkpoint, EG, Session = 1, Epoch = 6, CheckPoint = 416.
Si desea ejecutar la detección en sus propias imágenes con un modelo previamente capacitado, descargue el modelo previamente en la lista en las tablas anteriores o entrene sus propios modelos al principio, luego agregue imágenes a la carpeta $ root/imágenes y luego ejecute
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
Luego encontrará los resultados de detección en la carpeta $ root/imágenes.
Tenga en cuenta la demostración predeterminada de las categorías PASCAL_VOC. Debe cambiar la línea para adaptar su propio modelo.
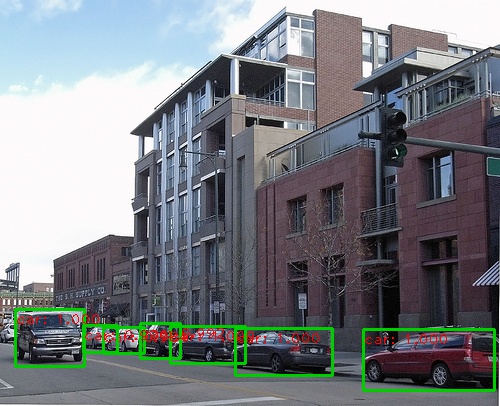
A continuación se presentan algunos resultados de detección:

Puede usar una cámara web en una demostración en tiempo real ejecutando
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
--webcam $WEBCAM_ID
La demostración se detiene haciendo clic en la ventana de la imagen y luego presionando la tecla 'Q'.
Este proyecto es igualmente contribuido por Jianwei Yang y Jiasen Lu, y muchos otros (¡gracias a ellos!).
@article{jjfaster2rcnn,
Author = {Jianwei Yang and Jiasen Lu and Dhruv Batra and Devi Parikh},
Title = {A Faster Pytorch Implementation of Faster R-CNN},
Journal = {https://github.com/jwyang/faster-rcnn.pytorch},
Year = {2017}
}
@inproceedings{renNIPS15fasterrcnn,
Author = {Shaoqing Ren and Kaiming He and Ross Girshick and Jian Sun},
Title = {Faster {R-CNN}: Towards Real-Time Object Detection
with Region Proposal Networks},
Booktitle = {Advances in Neural Information Processing Systems ({NIPS})},
Year = {2015}
}


