faster rcnn.pytorch
1.0.0
[05/29/2020] repo นี้เริ่มต้นเมื่อประมาณสองปีที่แล้วพัฒนาเป็นรหัสการตรวจจับวัตถุที่เปิดแหล่งแรกซึ่งรองรับการฝึกอบรมหลาย GPU มันได้รวมความพยายามอย่างมากจากคนจำนวนมาก อย่างไรก็ตามเราได้เห็น repos คุณภาพสูงจำนวนมากเกิดขึ้นในปีที่ผ่านมาเช่น:
ณ จุดนี้ฉันคิดว่า repo นี้เป็นข้อมูลที่ไม่อยู่ในรูปแบบของท่อและการเข้ารหัสและจะไม่รักษาอย่างแข็งขัน แม้ว่าคุณจะยังสามารถใช้ repo นี้เป็นสนามเด็กเล่นได้ แต่ฉันขอแนะนำให้คุณย้ายไปที่ repos ด้านบนเพื่อเจาะลึกลงไปใน West World of Object Detection!
โครงการนี้เป็นการดำเนินการ Pytorch ที่เร็วขึ้น ของ R-CNN ที่เร็วขึ้นโดยมีวัตถุประสงค์เพื่อเร่งการฝึกอบรมแบบจำลองการตรวจจับวัตถุ R-CNN ที่เร็วขึ้น เมื่อเร็ว ๆ นี้มีการใช้งานที่ดีจำนวนมาก:
RBGIRSHICK/PY-Faster-RCNN พัฒนาขึ้นอยู่กับ pycaffe + numpy
longcw/faster_rcnn_pytorch พัฒนาขึ้นอยู่กับ pytorch + numpy
Endernewton/TF-Faster-RCNN พัฒนาขึ้นอยู่กับ TensorFlow + Numpy
Ruotianluo/pytorch-rcnn-rcnn พัฒนาขึ้นอยู่กับ pytorch + tensorflow + numpy
ในระหว่างการดำเนินการของเราเราอ้างถึงการใช้งานข้างต้น Especailly longcw/faster_rcnn_pytorch อย่างไรก็ตามการใช้งานของเรามีคุณสมบัติที่ไม่ซ้ำกันและใหม่หลายอย่างเมื่อเทียบกับการใช้งานข้างต้น:
มันเป็นรหัส pytorch บริสุทธิ์ เราแปลงการใช้งาน numpy ทั้งหมดเป็น pytorch!
รองรับการฝึกอบรมแบทช์หลายภาพ เราแก้ไขเลเยอร์ทั้งหมดรวมถึง Dataloader, RPN, ROI-pooling ฯลฯ เพื่อรองรับภาพหลายภาพในแต่ละ minibatch
รองรับการฝึกอบรม GPU หลายครั้ง เราใช้ wrapper GPU หลายตัว (nn.dataparallel ที่นี่) เพื่อให้มีความยืดหยุ่นในการใช้ GPU หนึ่งตัวหรือมากกว่าเป็นข้อดีของคุณสมบัติสองประการข้างต้น
รองรับวิธีการรวมสามวิธี เรารวมวิธีการรวมสามวิธี: ROI Pooing, ROI Align และ ROI Crop ที่สำคัญกว่านั้นเราปรับเปลี่ยนทั้งหมดเพื่อสนับสนุนการฝึกอบรมแบทช์หลายภาพ
มันเป็นหน่วยความจำที่มีประสิทธิภาพ เรา จำกัด อัตราส่วนภาพและภาพกลุ่มที่มีอัตราส่วนภาพที่คล้ายกันเป็น minibatch ดังนั้นเราสามารถฝึกอบรม RESNET101 และ VGG16 ด้วย batchSize = 4 (4 ภาพ) บน Titan X เดียว (12 GB) เมื่อการฝึกอบรมด้วย 8 GPU ค่า batchsize สูงสุดสำหรับแต่ละ GPU คือ 3 (Res101) รวม 24
มันเร็วกว่า จากการปรับเปลี่ยนข้างต้นการฝึกอบรมนั้นเร็วกว่ามาก เรารายงานความเร็วในการฝึกอบรมเกี่ยวกับ Nvidia Titan XP ในตารางด้านล่าง
คุณสมบัติเครือข่ายพีระมิด (FPN)
หน้ากาก r-cnn ( อย่างต่อเนื่อง ดำเนินการโดย Roytseng-TW) แล้ว
กราฟ R-CNN (ส่วนขยายไปยังการสร้างกราฟฉาก)
เราเปรียบเทียบรหัสของเราอย่างละเอียดในชุดข้อมูลสามชุด: Pascal VOC, Coco และ Visual Genome โดยใช้สถาปัตยกรรมเครือข่ายที่แตกต่างกันสองรายการ: VGG16 และ RESNET101 ด้านล่างคือผลลัพธ์:
1). Pascal VOC 2007 (รถไฟ/ทดสอบ: 07trainval/07test, Scale = 600, จัดเรียง ROI)
| แบบอย่าง | #GPUS | ขนาดแบทช์ | LR | lr_decay | max_epoch | เวลา/ยุค | mem/gpu | แผนที่ |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 | 1 | 1E-3 | 5 | 6 | 0.76 ชม. | 3265MB | 70.1 |
| VGG-16 | 1 | 4 | 4e-3 | 8 | 9 | 0.50 ชม. | 9083MB | 69.6 |
| VGG-16 | 8 | 16 | 1E-2 | 8 | 10 | 0.19 ชม. | 5291MB | 69.4 |
| VGG-16 | 8 | 24 | 1E-2 | 10 | 11 | 0.16 ชม. | 11303MB | 69.2 |
| Res-101 | 1 | 1 | 1E-3 | 5 | 7 | 0.88 ชม. | 3200 MB | 75.2 |
| Res-101 | 1 | 4 | 4e-3 | 8 | 10 | 0.60 ชม. | 9700 MB | 74.9 |
| Res-101 | 8 | 16 | 1E-2 | 8 | 10 | 0.23 ชม. | 8400 MB | 75.2 |
| Res-101 | 8 | 24 | 1E-2 | 10 | 12 | 0.17 ชม. | 10327MB | 75.1 |
2). Coco (รถไฟ/ทดสอบ: COCO_TRAIN+COCO_VAL-MINAVAL/MINIVAL, SCALE = 800, MAX_SIZE = 1200, ROI ALIGN)
| แบบอย่าง | #GPUS | ขนาดแบทช์ | LR | lr_decay | max_epoch | เวลา/ยุค | mem/gpu | แผนที่ |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 8 | 16 | 1E-2 | 4 | 6 | 4.9 ชม. | 7192 MB | 29.2 |
| Res-101 | 8 | 16 | 1E-2 | 4 | 6 | 6.0 ชม. | 10956 MB | 36.2 |
| Res-101 | 8 | 16 | 1E-2 | 4 | 10 | 6.0 ชม. | 10956 MB | 37.0 |
บันทึก . เนื่องจากรุ่นข้างต้นใช้ Scale = 800 คุณต้องเพิ่ม "-LS" ในตอนท้ายของคำสั่งทดสอบ
3). Coco (รถไฟ/การทดสอบ: COCO_TRAIN+COCO_VAL-MINAVAL/MINIVAL, SCALE = 600, MAX_SIZE = 1,000, จัดตำแหน่ง ROI)
| แบบอย่าง | #GPUS | ขนาดแบทช์ | LR | lr_decay | max_epoch | เวลา/ยุค | mem/gpu | แผนที่ |
|---|---|---|---|---|---|---|---|---|
| Res-101 | 8 | 24 | 1E-2 | 4 | 6 | 5.4 ชั่วโมง | 10659 MB | 33.9 |
| Res-101 | 8 | 24 | 1E-2 | 4 | 10 | 5.4 ชั่วโมง | 10659 MB | 34.5 |
4). Visual Genome (รถไฟ/การทดสอบ: VG_Train/VG_Test, Scale = 600, Max_Size = 1000, ROI จัดตำแหน่ง, หมวดหมู่ = 2500)
| แบบอย่าง | #GPUS | ขนาดแบทช์ | LR | lr_decay | max_epoch | เวลา/ยุค | mem/gpu | แผนที่ |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 P100 | 4 | 1E-3 | 5 | 20 | 3.7 ชม. | 12707 MB | 4.4 |
ขอบคุณ Remi ที่ให้รูปแบบการตรวจจับที่ผ่านการฝึกอบรมเกี่ยวกับจีโนมที่มองเห็นได้!
ก่อนอื่นให้โคลนรหัส
git clone https://github.com/jwyang/faster-rcnn.pytorch.git
จากนั้นสร้างโฟลเดอร์:
cd faster-rcnn.pytorch && mkdir data
PASCAL_VOC 07+12 : โปรดทำตามคำแนะนำใน PY-Faster-RCNN เพื่อเตรียมชุดข้อมูล VOC จริงๆแล้วคุณสามารถอ้างถึงคนอื่น ๆ หลังจากดาวน์โหลดข้อมูลแล้วให้สร้าง SoftLinks ในข้อมูลโฟลเดอร์/
COCO : โปรดทำตามคำแนะนำใน PY-Faster-RCNN เพื่อเตรียมข้อมูล
Visual Genome : โปรดทำตามคำแนะนำในความสนใจจากล่างขึ้นบนเพื่อเตรียมชุดข้อมูลจีโนมที่มองเห็นได้ คุณต้องดาวน์โหลดรูปภาพและไฟล์คำอธิบายประกอบวัตถุก่อนจากนั้นดำเนินการตามคำแนะนำเพื่อให้ได้คำศัพท์และคำอธิบายประกอบที่ทำความสะอาดตามสคริปต์ที่ให้ไว้ในที่เก็บนี้
เราใช้แบบจำลองสองแบบในการทดลอง VGG และ RESNET101 คุณสามารถดาวน์โหลดสองรุ่นนี้ได้จาก:
VGG16: Dropbox, VT Server
Resnet101: Dropbox, VT Server
ดาวน์โหลดและใส่ลงในข้อมูล/pretrained_model/
บันทึก . เราเปรียบเทียบโมเดลที่ผ่านการฝึกอบรมจาก Pytorch และ Caffe และพบว่าแบบจำลองที่ผ่านการฝึกฝนของคาเฟอีนมีประสิทธิภาพที่ดีกว่า Pytorch เล็กน้อย เราขอแนะนำให้ใช้โมเดลที่ได้รับการฝึกฝนคาเฟอีนจากลิงค์ด้านบนเพื่อทำซ้ำผลลัพธ์ของเรา
หากคุณต้องการใช้โมเดล Pytorch ที่ผ่านการฝึกอบรมมาก่อนโปรดอย่าลืมเปลี่ยนภาพจาก BGR เป็น RGB และใช้หม้อแปลงข้อมูลเดียวกัน (ลบค่าเฉลี่ยและทำให้เป็นปกติ) ตามที่ใช้ในแบบจำลองก่อนหน้า
ตามที่ชี้ให้เห็นโดย ruotianluo/pytorch-rcnn-rcnn เลือกที่ถูกต้อง -arch ในไฟล์ make.sh เพื่อรวบรวมรหัส cuda:
| รุ่น GPU | สถาปัตยกรรม |
|---|---|
| Titanx (Maxwell/Pascal) | sm_52 |
| GTX 960m | SM_50 |
| GTX 1080 (TI) | sm_61 |
| Grid K520 (AWS G2.2xlarge) | sm_30 |
| Tesla K80 (AWS P2.xlarge) | sm_37 |
รายละเอียดเพิ่มเติมเกี่ยวกับการตั้งค่าสถาปัตยกรรมสามารถพบได้ที่นี่หรือที่นี่
ติดตั้งการพึ่งพา Python ทั้งหมดโดยใช้ PIP:
pip install -r requirements.txt
รวบรวมการพึ่งพา CUDA โดยใช้คำสั่งง่ายๆต่อไปนี้:
cd lib
sh make.sh
มันจะรวบรวมโมดูลทั้งหมดที่คุณต้องการรวมถึง NMS, ROI_POOING, ROI_ALIGN และ ROI_CROP เวอร์ชันเริ่มต้นถูกรวบรวมด้วย Python 2.7 โปรดรวบรวมด้วยตัวเองหากคุณใช้เวอร์ชัน Python อื่น
ดังที่ชี้ให้เห็นในปัญหานี้หากคุณพบข้อผิดพลาดบางอย่างระหว่างการรวบรวมคุณอาจพลาดที่จะส่งออกเส้นทาง CUDA ไปยังสภาพแวดล้อมของคุณ
ก่อนการฝึกอบรมให้ตั้งค่าไดเรกทอรีที่เหมาะสมเพื่อบันทึกและโหลดโมเดลที่ผ่านการฝึกอบรม เปลี่ยนอาร์กิวเมนต์ "save_dir" และ "load_dir" ใน trainval_net.py และ test_net.py เพื่อปรับให้เข้ากับสภาพแวดล้อมของคุณ
ในการฝึกอบรมรุ่น R-CNN ที่เร็วขึ้นด้วย VGG16 บน PASCAL_VOC เพียงแค่เรียกใช้:
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net vgg16
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
โดยที่ 'BS' เป็นขนาดแบทช์ที่มีค่าเริ่มต้น 1. อีกวิธีหนึ่งในการฝึกอบรมด้วย RESNET101 บน PASCAL_VOC, Simple Run:
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net res101
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
ด้านบน Batch_size และ Worker_number สามารถตั้งค่าได้ตามขนาดหน่วยความจำ GPU ของคุณ บน Titan XP ที่มีหน่วยความจำ 12G สามารถสูงสุด 4
หากคุณมีหลาย (พูด 8) Titan XP GPU ให้ใช้ทั้งหมด! พยายาม:
python trainval_net.py --dataset pascal_voc --net vgg16
--bs 24 --nw 8
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda --mGPUs
เปลี่ยนชุดข้อมูลเป็น "Coco" หรือ 'VG' หากคุณต้องการฝึกอบรมเกี่ยวกับ Coco หรือ Visual Genome
หากคุณต้องการประเมินประสิทธิภาพการตรวจจับของโมเดล VGG16 ที่ผ่านการฝึกอบรมมาก่อนในชุดทดสอบ PASCAL_VOC เพียงแค่เรียกใช้
python test_net.py --dataset pascal_voc --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda
ระบุเซสชันโมเดลเฉพาะ, CheckePoch และจุดตรวจสอบ, เช่นเซสชัน = 1, EPOCH = 6, จุดตรวจ = 416
หากคุณต้องการเรียกใช้การตรวจจับในภาพของคุณเองด้วยรุ่นที่ผ่านการฝึกอบรมมาก่อนให้ดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมที่ระบุไว้ในตารางด้านบนหรือฝึกอบรมโมเดลของคุณเองในตอนแรกจากนั้นเพิ่มรูปภาพลงในโฟลเดอร์ $ root/images จากนั้นเรียกใช้
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
จากนั้นคุณจะพบผลลัพธ์การตรวจจับในโฟลเดอร์ $ root/images
หมายเหตุค่าเริ่มต้น demo.py เพียงสนับสนุนหมวดหมู่ pascal_voc คุณต้องเปลี่ยนบรรทัดเพื่อปรับโมเดลของคุณเอง
ด้านล่างนี้เป็นผลการตรวจจับบางอย่าง:
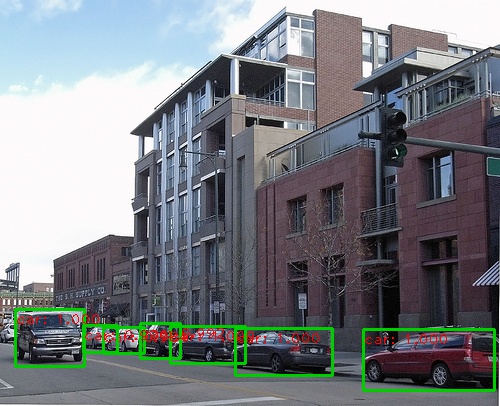

คุณสามารถใช้เว็บแคมในการสาธิตแบบเรียลไทม์โดยการรัน
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
--webcam $WEBCAM_ID
การสาธิตจะหยุดโดยคลิกที่หน้าต่างภาพจากนั้นกดปุ่ม 'Q'
โครงการนี้มีส่วนร่วมอย่างเท่าเทียมกันโดย Jianwei Yang และ Jiasen Lu และอื่น ๆ อีกมากมาย (ขอบคุณพวกเขา!)
@article{jjfaster2rcnn,
Author = {Jianwei Yang and Jiasen Lu and Dhruv Batra and Devi Parikh},
Title = {A Faster Pytorch Implementation of Faster R-CNN},
Journal = {https://github.com/jwyang/faster-rcnn.pytorch},
Year = {2017}
}
@inproceedings{renNIPS15fasterrcnn,
Author = {Shaoqing Ren and Kaiming He and Ross Girshick and Jian Sun},
Title = {Faster {R-CNN}: Towards Real-Time Object Detection
with Region Proposal Networks},
Booktitle = {Advances in Neural Information Processing Systems ({NIPS})},
Year = {2015}
}


