faster rcnn.pytorch
1.0.0
[29.05.2020] Dieses Repo wurde vor etwa zwei Jahren als erster Open-Sourced-Objekterkennungscode entwickelt, der das Multi-GPU-Training unterstützt. Es hat enorme Anstrengungen von vielen Menschen integriert. Wir haben jedoch in den letzten Jahren viele hochwertige Repos aufgetaucht, wie z. B.:
Zu diesem Zeitpunkt denke ich, dass dieses Repo in Bezug auf die Pipeline und den Codierungsstil außerhalb der Daten ist und nicht aktiv beibehalten wird. Obwohl Sie dieses Repo immer noch als Spielplatz verwenden können, empfehle ich Ihnen dringend, zu den oben genannten Repos zu wechseln, um in die West World of Object Detection zu wechseln!
Dieses Projekt ist eine schnellere Pytorch-Implementierung von schnellerem R-CNN, das darauf abzielt, das Training schnellerer R-CNN-Objekterkennungsmodelle zu beschleunigen. Vor kurzem gibt es eine Reihe guter Implementierungen:
rbgirshick/py-fager-rcnn, entwickelt auf Pycaffe + Numpy
longcw/faster_rcnn_pytorch, entwickelt basierend auf Pytorch + Numpy
Endernewton/TF-Faster-RCNN, entwickelt auf TensorFlow + Numpy
ruotianluo/pytorch-faster-rcnn, entwickelt auf Pytorch + Tensorflow + Numpy
Während unserer Implementierung haben wir die oben genannten Implementierungen, insbesondere Longcw/faster_rcnn_pytorch, verwiesen. Unsere Implementierung hat jedoch im Vergleich zu den oben genannten Implementierungen mehrere einzigartige und neue Funktionen:
Es ist reiner Pytorch -Code . Wir konvertieren alle Numpy -Implementierungen in Pytorch!
Es unterstützt das Multi-Image-Batch-Training . Wir überarbeiten alle Ebenen, einschließlich Dataloader, RPN, ROI-Pooling usw., um mehrere Bilder in jeder Minibatch zu unterstützen.
Es unterstützt mehrere GPU -Schulungen . Wir verwenden einen mehrfachen GPU -Wrapper (nn.dataparallel hier), um es flexibel zu machen, einen oder mehrere GPUs als Verdienst der beiden oben genannten Funktionen zu verwenden.
Es unterstützt drei Pooling -Methoden . Wir integrieren drei Pooling -Methoden: ROI Pooing, ROI -Ausrichtung und ROI -Ernte. Noch wichtiger ist, dass wir sie alle ändern, um das Multi-Image-Batch-Training zu unterstützen.
Es ist maßstabsöffizient . Wir begrenzen das Bild -Seitenverhältnis und Gruppenbilder mit ähnlichen Seitenverhältnissen in eine Minibatch. Daher können wir ResNet101 und VGG16 mit batchsize = 4 (4 Bilder) auf einem einzelnen Titan X (12 GB) trainieren. Beim Training mit 8 GPU beträgt die maximale Batchsize für jede GPU 3 (Res101) von 24.
Es ist schneller . Basierend auf den obigen Änderungen ist das Training viel schneller. Wir berichten über die Trainingsgeschwindigkeit für Nvidia Titan XP in den folgenden Tabellen.
Feature Pyramid Network (FPN)
Mask R-cnn ( laufend Bereits von Roytsg-TW implementiert)
Graph R-CNN (Erweiterung der Szenengrafikgenerierung)
Wir bewerten unseren Code gründlich auf drei Datensätzen: Pascal VOC, Coco und Visual Genom unter Verwendung von zwei verschiedenen Netzwerkarchitekturen: VGG16 und ResNet101. Nachfolgend finden Sie die Ergebnisse:
1). Pascal VOC 2007 (Zug/Test: 07Trainval/07Test, Skala = 600, ROI -Align)
| Modell | #Gpus | Chargengröße | lr | LR_DECAY | max_epoch | Zeit/Epoche | mem/gpu | Karte |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 | 1 | 1e-3 | 5 | 6 | 0,76 Std | 3265MB | 70.1 |
| VGG-16 | 1 | 4 | 4e-3 | 8 | 9 | 0,50 h | 9083MB | 69.6 |
| VGG-16 | 8 | 16 | 1e-2 | 8 | 10 | 0,19 h | 5291MB | 69.4 |
| VGG-16 | 8 | 24 | 1e-2 | 10 | 11 | 0,16 Std | 11303MB | 69.2 |
| Res-101 | 1 | 1 | 1e-3 | 5 | 7 | 0,88 Stunden | 3200 MB | 75,2 |
| Res-101 | 1 | 4 | 4e-3 | 8 | 10 | 0,60 Std | 9700 MB | 74,9 |
| Res-101 | 8 | 16 | 1e-2 | 8 | 10 | 0,23 Std | 8400 MB | 75,2 |
| Res-101 | 8 | 24 | 1e-2 | 10 | 12 | 0,17 h | 10327MB | 75.1 |
2). Coco (Zug/Test: CoCO_TRAIN+COCO_VAL-MINIVAL/MINIVAL, SCALE = 800, MAX_SIZE = 1200, ROI Align)
| Modell | #Gpus | Chargengröße | lr | LR_DECAY | max_epoch | Zeit/Epoche | mem/gpu | Karte |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 8 | 16 | 1e-2 | 4 | 6 | 4,9 h | 7192 MB | 29.2 |
| Res-101 | 8 | 16 | 1e-2 | 4 | 6 | 6,0 h | 10956 MB | 36.2 |
| Res-101 | 8 | 16 | 1e-2 | 4 | 10 | 6,0 h | 10956 MB | 37.0 |
NOTIZ . Da die obigen Modelle am Ende des Testbefehls "--ls" addieren müssen.
3). Coco (Zug/Test: CoCO_TRAIN+COCO_VAL-MINIVAL/MINIVAL, SCALE = 600, MAX_SIZE = 1000, ROI Align)
| Modell | #Gpus | Chargengröße | lr | LR_DECAY | max_epoch | Zeit/Epoche | mem/gpu | Karte |
|---|---|---|---|---|---|---|---|---|
| Res-101 | 8 | 24 | 1e-2 | 4 | 6 | 5.4 Std | 10659 MB | 33.9 |
| Res-101 | 8 | 24 | 1e-2 | 4 | 10 | 5.4 Std | 10659 MB | 34.5 |
4). Visuelles Genom (Zug/Test: vg_train/vg_test, scale = 600, max_size = 1000, ROI -Align, Kategorie = 2500)
| Modell | #Gpus | Chargengröße | lr | LR_DECAY | max_epoch | Zeit/Epoche | mem/gpu | Karte |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 P100 | 4 | 1e-3 | 5 | 20 | 3,7 h | 12707 MB | 4.4 |
Vielen Dank an Remi für die Bereitstellung des vorbereiteten Nachweismodells auf visuellem Genom!
Klonen Sie zunächst den Code
git clone https://github.com/jwyang/faster-rcnn.pytorch.git
Erstellen Sie dann einen Ordner:
cd faster-rcnn.pytorch && mkdir data
PASCAL_VOC 07+12 : Befolgen Sie die Anweisungen in Py-Faste-RCNN, um VOC-Datensätze vorzubereiten. Eigentlich können Sie sich auf andere beziehen. Erstellen Sie nach dem Herunterladen der Daten Softlinks in den Ordnerdaten/.
COCO : Bitte befolgen Sie auch die Anweisungen in Py-Fe-Taste-RCNN, um die Daten vorzubereiten.
Visuelles Genom : Befolgen Sie die Anweisungen in Bottom-up-Beachtung, um den Datensatz des visuellen Genoms vorzubereiten. Sie müssen zuerst die Bilder und Anmerkungsdateien von Bildern und Objektanmerkungen herunterladen und anschließend die Propregung durchführen, um den Vokabular und die gereinigten Annotationen basierend auf den in diesem Repository bereitgestellten Skripten zu erhalten.
Wir haben zwei vorbereitete Modelle in unseren Experimenten, VGG und ResNet101, verwendet. Sie können diese beiden Modelle herunterladen:
VGG16: Dropbox, VT Server
Resnet101: Dropbox, VT Server
Laden Sie sie herunter und setzen Sie sie in die Daten/vorab/model/.
NOTIZ . Wir vergleichen die vorbereiteten Modelle von Pytorch und Caffe und haben überraschenderweise festgestellt, dass Caffe -Vorbereitungsmodelle eine etwas bessere Leistung haben als Pytorch -Presented. Wir würden empfehlen, Caffe -Vorbilder aus dem obigen Link zu verwenden, um unsere Ergebnisse zu reproduzieren.
Wenn Sie Pytorch-Modelle verwenden möchten, denken Sie bitte daran, Bilder von BGR auf RGB zu transponieren und denselben Datentransformator (minus Mittelwert und Normalisierung) wie im vorbereiteten Modell verwendet.
Wählen Sie den richtigen -arch -Code aus, wie von Ruotianluo/Pytorch-Fasters-RCNN in der Datei make.sh Datei ausgewählt:
| GPU -Modell | Architektur |
|---|---|
| Titanx (Maxwell/Pascal) | sm_52 |
| GTX 960 m | sm_50 |
| GTX 1080 (TI) | sm_61 |
| Grid K520 (AWS G2.2xLarge) | sm_30 |
| Tesla K80 (AWS p2.xlarge) | sm_37 |
Weitere Details zum Festlegen der Architektur finden Sie hier oder hier
Installieren Sie alle Python -Abhängigkeiten mit PIP:
pip install -r requirements.txt
Kompilieren Sie die CUDA -Abhängigkeiten mit den folgenden einfachen Befehlen:
cd lib
sh make.sh
Es wird alle Module kompilieren, die Sie benötigen, einschließlich NMS, ROI_POOING, ROI_ALIGN und ROI_CROP. Die Standardversion wird mit Python 2.7 zusammengestellt. Bitte kompilieren Sie selbst, wenn Sie eine andere Python -Version verwenden.
Wie in diesem Problem hervorgehoben, können Sie, wenn Sie während der Zusammenstellung auf einen Fehler stoßen, möglicherweise den Exportieren der CUDA -Pfade in Ihre Umgebung vermissen.
Stellen Sie vor dem Training das richtige Verzeichnis ein, um die geschulten Modelle zu speichern und zu laden. Ändern Sie die Argumente "Save_dir" und "Load_dir" in trainval_net.py und test_net.py, um sich an Ihre Umgebung anzupassen.
Um ein schnelleres R-CNN-Modell mit VGG16 auf pascal_voc zu trainieren, rennen Sie einfach:
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net vgg16
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
wobei 'BS' die Chargengröße mit Standard 1 ist.
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net res101
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
Oben können Batch_Size und Worker_Number nach Ihrer GPU -Speichergröße adaptiv eingestellt werden. Auf Titan XP mit 12G -Speicher kann es bis zu 4 sein .
Wenn Sie mehrere Titan XP -GPUs (z. B. 8) haben, verwenden Sie sie einfach alle! Versuchen:
python trainval_net.py --dataset pascal_voc --net vgg16
--bs 24 --nw 8
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda --mGPUs
Ändern Sie den Datensatz in "Coco" oder "VG", wenn Sie auf Coco oder Visual Genom trainieren möchten.
Wenn Sie die Erkennungsleistung eines vorgebildeten VGG16-Modells am PASCAL_VOC-Testsatz bewerten möchten, leiten Sie einfach aus
python test_net.py --dataset pascal_voc --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda
Geben Sie die spezifische Modellsitzung, Scheckkepoch und Checkpoint, z. B. Session = 1, EPOCH = 6, Checkpoint = 416 an.
Wenn Sie die Erkennung auf Ihren eigenen Bildern mit einem vorgeborenen Modell ausführen möchten, laden Sie das in den obigen Tabellen aufgeführte Modell herunter oder trainieren Sie zunächst Ihre eigenen Modelle
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
Anschließend finden Sie die Erkennungsergebnisse im Ordner $ root/bilder.
Beachten Sie die Standard -Demo.py unterstützen lediglich die Kategorien Pascal_voc. Sie müssen die Linie ändern, um Ihr eigenes Modell anzupassen.
Im Folgenden finden Sie einige Erkennungsergebnisse:
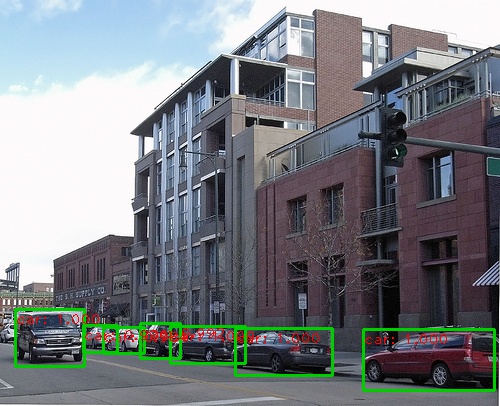

Sie können eine Webcam in einer Echtzeit-Demo durch Laufen verwenden
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
--webcam $WEBCAM_ID
Die Demo wird gestoppt, indem Sie auf das Bildfenster klicken und dann auf die Taste "Q" gedrückt werden.
Dieses Projekt wird gleichermaßen von Jianwei Yang und Jiasen Lu und vielen anderen beigetragen (dank ihnen!).
@article{jjfaster2rcnn,
Author = {Jianwei Yang and Jiasen Lu and Dhruv Batra and Devi Parikh},
Title = {A Faster Pytorch Implementation of Faster R-CNN},
Journal = {https://github.com/jwyang/faster-rcnn.pytorch},
Year = {2017}
}
@inproceedings{renNIPS15fasterrcnn,
Author = {Shaoqing Ren and Kaiming He and Ross Girshick and Jian Sun},
Title = {Faster {R-CNN}: Towards Real-Time Object Detection
with Region Proposal Networks},
Booktitle = {Advances in Neural Information Processing Systems ({NIPS})},
Year = {2015}
}


