faster rcnn.pytorch
1.0.0
[05/29/2020] تم إنشاء هذا الريبو منذ حوالي عامين ، تم تطويره كأول رمز للكشف عن الكائنات مفتوحة المصدر والذي يدعم التدريب متعدد GPU. لقد تم دمج جهود هائلة من العديد من الناس. ومع ذلك ، فقد شهدنا العديد من عمليات إعادة الجودة عالية الجودة في السنوات الأخيرة ، مثل:
في هذه المرحلة ، أعتقد أن هذا الريبو هو خارج نطاق البيانات من حيث خط الأنابيب وأسلوب الترميز ، ولن يحتفظ بنشاط. على الرغم من أنه لا يزال بإمكانك استخدام هذا الريبو كملعب ، إلا أنني أوصيك بشدة بالانتقال إلى الإعادة المذكورة أعلاه للتغلب على عالم الكشف عن الكائنات الغربية!
هذا المشروع هو تطبيق Pytorch أسرع لـ R-CNN أسرع ، يهدف إلى تسريع تدريب نماذج الكشف عن كائنات R-CNN الأسرع. في الآونة الأخيرة ، هناك عدد من التطبيقات الجيدة:
rbgirshick/py faster-rcnn ، تم تطويره على أساس pycaffe + numpy
longcw/faster_rcnnn_pytorch ، تم تطويره على أساس pytorch + numpy
Endernewton/TFISTER-RCNN ، تم تطويره على أساس TensorFlow + Numpy
Ruotianluo/pytorch-faster-rcnn ، تم تطويره على أساس pytorch + TensorFlow + Numpy
أثناء تنفيذنا ، أشرنا التطبيقات المذكورة أعلاه ، especailly longcw/faster_rcnn_pytorch. ومع ذلك ، فإن تنفيذنا له العديد من الميزات الفريدة والجديدة مقارنة بالتطبيقات المذكورة أعلاه:
إنه رمز Pytorch النقي . نقوم بتحويل جميع تطبيقات Numpy إلى Pytorch!
وهو يدعم التدريب على الدفعة متعددة الصور . نقوم بمراجعة جميع الطبقات ، بما في ذلك Dataloader و RPN و Booling ROI ، وما إلى ذلك ، لدعم صور متعددة في كل صغيرة.
وهو يدعم التدريب متعدد وحدات معالجة الرسومات . نحن نستخدم غلاف GPU متعدد (nn.dataparalled هنا) لجعله مرنًا لاستخدام وحدة معالجة الرسومات أو أكثر ، كأفضل للميزتين أعلاه.
وهو يدعم ثلاث طرق تجميع . نحن ندمج ثلاث طرق تجميع: عائد الاستثمار ، محاذاة العائد على الاستثمار ومحصول العائد على الاستثمار. الأهم من ذلك ، نحن نعدل كل منهم لدعم التدريب على الدفعة متعددة الصور.
إنه فعال الذاكرة . نحن نحد من نسبة العرض إلى ارتفاع الصورة ، والصور الجماعية مع نسب عرضية مماثلة في minibatch. على هذا النحو ، يمكننا تدريب Resnet101 و VGG16 مع BatchSize = 4 (4 صور) على Titan X واحد (12 جيجابايت). عند التدريب مع 8 GPU ، فإن الحد الأقصى لحجم النقود لكل وحدة معالجة الرسومات هو 3 (res101) ، ويبلغ مجموعها 24.
إنه أسرع . بناءً على التعديلات أعلاه ، يكون التدريب أسرع بكثير. نقوم بالإبلاغ عن سرعة التدريب على Nvidia Titan XP في الجداول أدناه.
ميزة شبكة الهرم (FPN)
قناع R-CNN ( مستمر نفذت بالفعل من قبل Roytseng-TW)
الرسم البياني R-CNN (تمديد إلى جيل الرسوم البيانية للمشهد)
نقوم بتقييم رمزنا بدقة على ثلاث مجموعات بيانات: Pascal Voc و Coco و Visual Genome ، باستخدام اثنين من البنية المختلفة للشبكة: VGG16 و Resnet101. فيما يلي النتائج:
1). Pascal Voc 2007 (Train/Test: 07trainval/07test ، Scale = 600 ، ROI ALINS)
| نموذج | #gpus | حجم الدُفعة | LR | LR_DECAY | max_epoch | الوقت/الحقبة | MEM/GPU | رسم خريطة |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 | 1 | 1E-3 | 5 | 6 | 0.76 ساعة | 3265 ميجابايت | 70.1 |
| VGG-16 | 1 | 4 | 4E-3 | 8 | 9 | 0.50 ساعة | 9083 ميجابايت | 69.6 |
| VGG-16 | 8 | 16 | 1E-2 | 8 | 10 | 0.19 ساعة | 5291 ميغابايت | 69.4 |
| VGG-16 | 8 | 24 | 1E-2 | 10 | 11 | 0.16 ساعة | 11303MB | 69.2 |
| RES-101 | 1 | 1 | 1E-3 | 5 | 7 | 0.88 ساعة | 3200 ميغابايت | 75.2 |
| RES-101 | 1 | 4 | 4E-3 | 8 | 10 | 0.60 ساعة | 9700 ميغابايت | 74.9 |
| RES-101 | 8 | 16 | 1E-2 | 8 | 10 | 0.23 ساعة | 8400 ميغابايت | 75.2 |
| RES-101 | 8 | 24 | 1E-2 | 10 | 12 | 0.17 ساعة | 10327 ميجابايت | 75.1 |
2). Coco (Train/Test: Coco_train+coco_val-minival/minival ، مقياس = 800 ، max_size = 1200 ، محاذاة العائد على الاستثمار)
| نموذج | #gpus | حجم الدُفعة | LR | LR_DECAY | max_epoch | الوقت/الحقبة | MEM/GPU | رسم خريطة |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 8 | 16 | 1E-2 | 4 | 6 | 4.9 ساعة | 7192 ميغابايت | 29.2 |
| RES-101 | 8 | 16 | 1E-2 | 4 | 6 | 6.0 ساعة | 10956 ميغابايت | 36.2 |
| RES-101 | 8 | 16 | 1E-2 | 4 | 10 | 6.0 ساعة | 10956 ميغابايت | 37.0 |
ملحوظة . نظرًا لأن النماذج المذكورة أعلاه تستخدم مقياس = 800 ، فأنت بحاجة إلى إضافة "-LS" في نهاية الأمر.
3). Coco (Train/Test: Coco_train+coco_val-minival/minival ، مقياس = 600 ، max_size = 1000 ، محاذاة العائد على الاستثمار)
| نموذج | #gpus | حجم الدُفعة | LR | LR_DECAY | max_epoch | الوقت/الحقبة | MEM/GPU | رسم خريطة |
|---|---|---|---|---|---|---|---|---|
| RES-101 | 8 | 24 | 1E-2 | 4 | 6 | 5.4 ساعة | 10659 ميغابايت | 33.9 |
| RES-101 | 8 | 24 | 1E-2 | 4 | 10 | 5.4 ساعة | 10659 ميغابايت | 34.5 |
4). الجينوم المرئي (القطار/الاختبار: VG_Train/VG_Test ، المقياس = 600 ، MAX_SIZE = 1000 ، محاذاة العائد على الاستثمار ، الفئة = 2500)
| نموذج | #gpus | حجم الدُفعة | LR | LR_DECAY | max_epoch | الوقت/الحقبة | MEM/GPU | رسم خريطة |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 P100 | 4 | 1E-3 | 5 | 20 | 3.7 ساعة | 12707 ميغابايت | 4.4 |
بفضل ريمي لتوفير نموذج الكشف المسبق على الجينوم البصري!
بادئ ذي بدء ، استنساخ الرمز
git clone https://github.com/jwyang/faster-rcnn.pytorch.git
ثم ، قم بإنشاء مجلد:
cd faster-rcnn.pytorch && mkdir data
Pascal_voc 07+12 : يرجى اتباع الإرشادات الموجودة في Rcnn Py Faste لإعداد مجموعات بيانات VOC. في الواقع ، يمكنك الرجوع إلى أي شخص آخر. بعد تنزيل البيانات ، قم بإنشاء softlinks في بيانات المجلد/.
COCO : يرجى أيضًا اتباع الإرشادات الواردة في RCNN FASTER FASTER لإعداد البيانات.
الجينوم المرئي : يرجى اتباع الإرشادات الموجودة في الالتحاق من أسفل إلى أعلى لإعداد مجموعة بيانات الجينوم البصري. تحتاج إلى تنزيل ملفات الصور وشرح الكائنات أولاً ، ثم تنفيذ proprecessing للحصول على المفردات والتطهير التعليقات التوضيحية بناءً على البرامج النصية المنصوص عليها في هذا المستودع.
استخدمنا نموذجين مسبقا في تجاربنا ، VGG و RESNET101. يمكنك تنزيل هذين النموذجين من:
VGG16: Dropbox ، خادم VT
RESNET101: Dropbox ، خادم VT
قم بتنزيلها ووضعها في البيانات/pretrained_model/.
ملحوظة . نقوم بمقارنة النماذج المسبقة من Pytorch و Caffe ، ونجد بشكل مدهش أن نماذج الكافيين المسبقة لها أداء أفضل قليلاً من Pytorch. نقترح استخدام نماذج الكافيين المسبقة من الرابط أعلاه لإعادة إنتاج نتائجنا.
إذا كنت ترغب في استخدام نماذج Pytorch التي تم تدريبها مسبقًا ، فيرجى تذكر تحويل الصور من BGR إلى RGB ، وكذلك استخدام محول البيانات نفسه (ناقص المتوسط والتطبيع) كما هو مستخدم في النموذج المسبق.
كما أشار بواسطة Ruotianluo/Pytorch-Fire-Rcnn ، اختر -arch في ملف make.sh ، لتجميع رمز CUDA:
| نموذج GPU | بنيان |
|---|---|
| تيتانكس (ماكسويل/باسكال) | SM_52 |
| GTX 960M | SM_50 |
| GTX 1080 (TI) | SM_61 |
| الشبكة K520 (AWS G2.2xlarge) | SM_30 |
| Tesla K80 (AWS P2.xlarge) | SM_37 |
يمكن العثور على مزيد من التفاصيل حول ضبط الهندسة المعمارية هنا أو هنا
تثبيت جميع تبعيات Python باستخدام PIP:
pip install -r requirements.txt
تجميع تبعيات CUDA باستخدام أوامر بسيطة التالية:
cd lib
sh make.sh
ستجمع جميع الوحدات التي تحتاجها ، بما في ذلك NMS و ROI_POOING و ROI_ALIGN و ROI_CROP. يتم تجميع الإصدار الافتراضي باستخدام Python 2.7 ، يرجى ترجمة بنفسك إذا كنت تستخدم إصدار Python مختلف.
كما هو موضح في هذه المشكلة ، إذا واجهت بعض الأخطاء أثناء التجميع ، فقد تفوت تصدير مسارات CUDA إلى بيئتك.
قبل التدريب ، اضبط الدليل الصحيح لحفظ وتحميل النماذج المدربة. قم بتغيير الوسائط "Save_Dir" و "load_dir" في Trainval_net.py و test_net.py للتكيف مع بيئتك.
لتدريب نموذج R-CNN أسرع مع VGG16 على PASCAL_VOC ، ما عليك سوى تشغيل:
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net vgg16
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
حيث يكون "BS" هو حجم الدُفعة مع الافتراضي 1. بدلاً من ذلك ، للتدريب مع RESNET101 على Pascal_VOC ، تشغيل بسيط:
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net res101
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
أعلاه ، يمكن ضبط Batch_size و Worker_number بشكل تكيفي وفقًا لحجم ذاكرة GPU الخاص بك. على Titan XP مع ذاكرة 12G ، يمكن أن يصل إلى 4 .
إذا كان لديك متعددة (Say 8) Titan XP وحدات معالجة الرسومات ، فما عليك سوى استخدامها جميعًا! يحاول:
python trainval_net.py --dataset pascal_voc --net vgg16
--bs 24 --nw 8
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda --mGPUs
قم بتغيير مجموعة البيانات إلى "Coco" أو "VG" إذا كنت ترغب في التدريب على كوكو أو جينوم بصري.
إذا كنت ترغب في تقييم أداء الكشف عن نموذج VGG16 الذي تم تدريبه مسبقًا على مجموعة اختبار Pascal_Voc ، ما عليك سوى التشغيل
python test_net.py --dataset pascal_voc --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda
حدد جلسة النموذج المحددة ، checkepoch و checkpoint ، على سبيل المثال ، الجلسة = 1 ، epoch = 6 ، نقطة التفتيش = 416.
إذا كنت ترغب في تشغيل الكشف على صورك الخاصة باستخدام طراز تدريب مسبقًا ، فقم بتنزيل الطراز المسبق المدرج في الجداول أعلاه أو تدريب النماذج الخاصة بك في البداية ، ثم أضف الصور إلى المجلد $ root/images ، ثم قم بتشغيلها
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
ثم ستجد نتائج الكشف في المجلد $ root/الصور.
لاحظ Demo.py الافتراضي فقط دعم فئات PASCAL_VOC. تحتاج إلى تغيير الخط لتكييف النموذج الخاص بك.
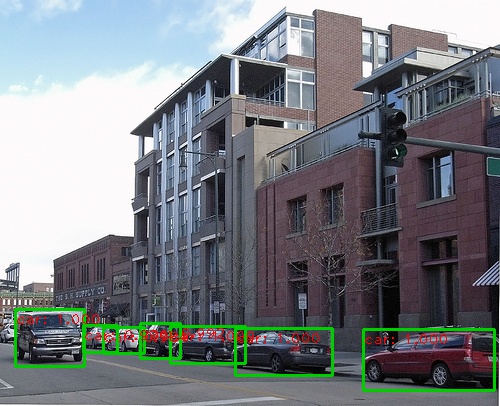
فيما يلي بعض نتائج الكشف:

يمكنك استخدام كاميرا ويب في العرض التوضيحي في الوقت الفعلي عن طريق التشغيل
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
--webcam $WEBCAM_ID
يتم إيقاف العرض التوضيحي عن طريق النقر على نافذة الصورة ثم الضغط على مفتاح "Q".
يساهم هذا المشروع بنفس القدر من قبل Jianwei Yang و Jiasen Lu ، والعديد من الآخرين (بفضلهم!).
@article{jjfaster2rcnn,
Author = {Jianwei Yang and Jiasen Lu and Dhruv Batra and Devi Parikh},
Title = {A Faster Pytorch Implementation of Faster R-CNN},
Journal = {https://github.com/jwyang/faster-rcnn.pytorch},
Year = {2017}
}
@inproceedings{renNIPS15fasterrcnn,
Author = {Shaoqing Ren and Kaiming He and Ross Girshick and Jian Sun},
Title = {Faster {R-CNN}: Towards Real-Time Object Detection
with Region Proposal Networks},
Booktitle = {Advances in Neural Information Processing Systems ({NIPS})},
Year = {2015}
}


