faster rcnn.pytorch
1.0.0
[05/29/2020]このレポは、約2年前にイニシアチルされ、マルチGPUトレーニングをサポートする最初のオープンソースのオブジェクト検出コードとして開発されました。それは多くの人々からの多大な努力を統合してきました。しかし、私たちは次のような過去数年間に多くの高品質のリポジトリが出現したのを見てきました。
この時点で、このレポはパイプラインとコーディングスタイルの観点からは外れていないと思いますが、積極的に維持されないと思います。このレポはまだ遊び場として使用できますが、上記のレポに移動してオブジェクト検出の西の世界を掘り下げることを強くお勧めします。
このプロジェクトは、より高速なR-CNNオブジェクト検出モデルのトレーニングを加速することを目的とした、より高速なR-CNNのPytorch実装が高速です。最近、多くの優れた実装があります。
pycaffe + numpyに基づいて開発されたrbgirshick/py-faster-rcnn
longcw/faster_rcnn_pytorch、pytorch + numpyに基づいて開発されました
Tensorflow + numpyに基づいて開発されたEndernewton/TF-Faster-RCNN
ruotianluo/pytorch-faster-rcnnは、pytorch + tensorflow + numpyに基づいて開発されました
実装中に、上記の実装、特にlongcw/faster_rcnn_pytorchを参照しました。ただし、私たちの実装には、上記の実装と比較して、いくつかのユニークな新機能があります。
純粋なPytorchコードです。すべてのnumpy実装をPytorchに変換します!
マルチイメージバッチトレーニングをサポートします。各ミニバッチで複数の画像をサポートするために、データローダー、RPN、ROIプーリングなどを含むすべてのレイヤーを修正します。
複数のGPUトレーニングをサポートします。上記の2つの機能のメリットとして、複数のGPUラッパー(ここではNN.Datapar Allecl)を使用して、1つ以上のGPUを使用できるようにします。
3つのプーリング方法をサポートします。 ROI POOING、ROI Align、ROI Cropの3つのプーリング方法を統合します。さらに重要なことは、それらすべてを変更して、マルチイメージバッチトレーニングをサポートすることです。
メモリ効率が高くなります。画像アスペクト比を制限し、同様のアスペクト比を持つグループ画像をミニバッチに制限します。そのため、単一のタイタンX(12 GB)でbatchsize = 4(4画像)でresnet101とvgg16をトレーニングできます。 8 GPUでトレーニングする場合、各GPUの最大バッチサイズは3(RES101)で、合計24です。
それはより速いです。上記の変更に基づいて、トレーニングははるかに高速です。以下のテーブルで、Nvidia Titan XPのトレーニング速度を報告します。
フィーチャーピラミッドネットワーク(FPN)
マスクr-cnn(進行中roytseng-twによってすでに実装されています)
グラフr-CNN(シーングラフ生成の拡張)
2つの異なるネットワークアーキテクチャを使用して、Pascal VOC、COCO、およびVisual Genomeの3つのデータセットでコードを徹底的にベンチマークします。VGG16とResNet101。以下は結果です:
1)。 Pascal Voc 2007(トレイン/テスト:07trainval/07test、scale = 600、roi align)
| モデル | #gpus | バッチサイズ | LR | LR_DECAY | max_epoch | 時間/時代 | MEM/GPU | 地図 |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 | 1 | 1E-3 | 5 | 6 | 0.76時間 | 3265MB | 70.1 |
| VGG-16 | 1 | 4 | 4E-3 | 8 | 9 | 0.50時間 | 9083MB | 69.6 |
| VGG-16 | 8 | 16 | 1E-2 | 8 | 10 | 0.19時間 | 5291MB | 69.4 |
| VGG-16 | 8 | 24 | 1E-2 | 10 | 11 | 0.16時間 | 11303MB | 69.2 |
| RES-101 | 1 | 1 | 1E-3 | 5 | 7 | 0.88時間 | 3200 MB | 75.2 |
| RES-101 | 1 | 4 | 4E-3 | 8 | 10 | 0.60時間 | 9700 MB | 74.9 |
| RES-101 | 8 | 16 | 1E-2 | 8 | 10 | 0.23時間 | 8400 MB | 75.2 |
| RES-101 | 8 | 24 | 1E-2 | 10 | 12 | 0.17時間 | 10327MB | 75.1 |
2)。 coco(トレイン/テスト:coco_train+coco_val-minival/minival、scale = 800、max_size = 1200、roi align)
| モデル | #gpus | バッチサイズ | LR | LR_DECAY | max_epoch | 時間/時代 | MEM/GPU | 地図 |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 8 | 16 | 1E-2 | 4 | 6 | 4.9時間 | 7192 MB | 29.2 |
| RES-101 | 8 | 16 | 1E-2 | 4 | 6 | 6.0時間 | 10956 MB | 36.2 |
| RES-101 | 8 | 16 | 1E-2 | 4 | 10 | 6.0時間 | 10956 MB | 37.0 |
注記。上記のモデルはスケール= 800を使用するため、テストコマンドの最後に「-ls」を追加する必要があります。
3)。 coco(トレイン/テスト:coco_train+coco_val-minival/minival、scale = 600、max_size = 1000、roi align)
| モデル | #gpus | バッチサイズ | LR | LR_DECAY | max_epoch | 時間/時代 | MEM/GPU | 地図 |
|---|---|---|---|---|---|---|---|---|
| RES-101 | 8 | 24 | 1E-2 | 4 | 6 | 5.4時間 | 10659 MB | 33.9 |
| RES-101 | 8 | 24 | 1E-2 | 4 | 10 | 5.4時間 | 10659 MB | 34.5 |
4)。ビジュアルゲノム(トレイン/テスト:VG_TRAIN/VG_TEST、SCALE = 600、MAX_SIZE = 1000、ROI Align、Category = 2500)
| モデル | #gpus | バッチサイズ | LR | LR_DECAY | max_epoch | 時間/時代 | MEM/GPU | 地図 |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 P100 | 4 | 1E-3 | 5 | 20 | 3.7時間 | 12707 MB | 4.4 |
Visual Genomeで前提条件の検出モデルを提供してくれたReMiに感謝します!
まず、コードをクローンします
git clone https://github.com/jwyang/faster-rcnn.pytorch.git
次に、フォルダーを作成します。
cd faster-rcnn.pytorch && mkdir data
pascal_voc 07+12 :VOCデータセットを準備するために、py-faster-rcnnの指示に従ってください。実際、他のものを参照できます。データをダウンロードした後、フォルダーデータ/にソフトリンクを作成します。
COCO :Py-Faster-RCNNの指示に従って、データを準備してください。
ビジュアルゲノム:ボトムアップアテンションの指示に従って、視覚的なゲノムデータセットを準備してください。最初に画像とオブジェクトアノテーションファイルをダウンロードし、次にこのリポジトリで提供されているスクリプトに基づいて語彙とクレンジングされた注釈を取得する必要があることを実行する必要があります。
実験では、VGGとRESNET101の2つの事前に保護されたモデルを使用しました。次の2つのモデルをダウンロードできます。
VGG16:Dropbox、VT Server
ResNet101:Dropbox、VT Server
それらをダウンロードして、データ/pretrained_model/に入れます。
注記。 PytorchとCaffeの前提条件のモデルを比較し、驚くべきことに、Caffe Tretrained ModelsはPytorchが前処理されたよりもわずかに優れたパフォーマンスを持っていることがわかります。上記のリンクからCaffe事前に処理されたモデルを使用して、結果を再現することをお勧めします。
Pytorchの事前訓練モデルを使用したい場合は、BGRからRGBに画像を転置し、前処理モデルで使用しているのと同じデータトランス(平均と正規化)を使用することを忘れないでください。
ruotianluo/pytorch-faster-rcnnが指摘したように、cudaコードをコンパイルするには、 make.shファイルで正しい-archを選択してください。
| GPUモデル | 建築 |
|---|---|
| Titanx(Maxwell/Pascal) | SM_52 |
| GTX 960M | SM_50 |
| GTX 1080(TI) | SM_61 |
| グリッドK520(AWS G2.2XLARGE) | SM_30 |
| テスラK80(AWS P2.XLARGE) | SM_37 |
アーキテクチャの設定の詳細については、こちらまたはこちらをご覧ください。
PIPを使用してすべてのPython依存関係をインストールします。
pip install -r requirements.txt
次の簡単なコマンドを使用して、CUDA依存関係をコンパイルします。
cd lib
sh make.sh
NMS、ROI_POOING、ROI_ALIGN、ROI_CROPなど、必要なすべてのモジュールをコンパイルします。デフォルトバージョンはPython 2.7でコンパイルされています。別のPythonバージョンを使用している場合は、自分でコンパイルしてください。
この号で指摘されているように、コンピレーション中に何らかのエラーが発生した場合、環境へのCUDAパスをエクスポートするのを見逃す可能性があります。
トレーニング前に、訓練されたモデルを保存およびロードするために適切なディレクトリを設定します。 Trainval_net.pyおよびtest_net.pyの引数「Save_dir」と「load_dir」を変更して、環境に適応します。
PASCAL_VOCでVGG16を使用してより高速なR-CNNモデルをトレーニングするには、単に実行するだけです。
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net vgg16
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
ここで、「BS」はデフォルト1のバッチサイズです。あるいは、PASCAL_VOCでRESNET101でトレーニングするには、単純な実行:
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net res101
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
上記では、batch_sizeとworker_numberは、GPUメモリサイズに応じて適応的に設定できます。 12gメモリを備えたTitan XPでは、最大4になる可能性があります。
複数の(たとえば8)Titan XP GPUがある場合は、それらをすべて使用してください!試す:
python trainval_net.py --dataset pascal_voc --net vgg16
--bs 24 --nw 8
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda --mGPUs
ココまたは視覚ゲノムでトレーニングしたい場合は、データセットを「ココ」または「VG」に変更します。
pascal_vocテストセットで事前に訓練されたVGG16モデルの検出パフォーマンスを評価したい場合は、単に実行する
python test_net.py --dataset pascal_voc --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda
特定のモデルセッション、CheckePochおよびCheckpoint、Eg、Session = 1、Epoch = 6、CheckPoint = 416を指定します。
事前に訓練されたモデルを使用して独自の画像で検出を実行する場合は、上記のテーブルにリストされている前提型モデルをダウンロードするか、最初に独自のモデルをトレーニングしてから、フォルダー$ root/画像に画像を追加して、実行してください
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
次に、Folder $ root/Imagesで検出結果が見つかります。
注意するデフォルトのdemo.pyは、単にpascal_vocカテゴリをサポートするだけです。独自のモデルを適応させるには、ラインを変更する必要があります。
以下はいくつかの検出結果です。
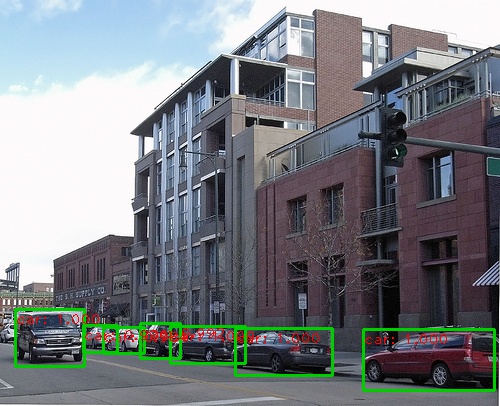

実行して、リアルタイムデモでウェブカメラを使用できます
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
--webcam $WEBCAM_ID
画像ウィンドウをクリックして、「Q」キーを押すことでデモが停止します。
このプロジェクトは、Jianwei YangとJiasen Lu、その他多くのプロジェクトも同様に寄付されています(彼らのおかげです!)。
@article{jjfaster2rcnn,
Author = {Jianwei Yang and Jiasen Lu and Dhruv Batra and Devi Parikh},
Title = {A Faster Pytorch Implementation of Faster R-CNN},
Journal = {https://github.com/jwyang/faster-rcnn.pytorch},
Year = {2017}
}
@inproceedings{renNIPS15fasterrcnn,
Author = {Shaoqing Ren and Kaiming He and Ross Girshick and Jian Sun},
Title = {Faster {R-CNN}: Towards Real-Time Object Detection
with Region Proposal Networks},
Booktitle = {Advances in Neural Information Processing Systems ({NIPS})},
Year = {2015}
}


