faster rcnn.pytorch
1.0.0
[05/29/2020]이 repo는 약 2 년 전에 다중 GPU 교육을 지원하는 최초의 오픈 소스 객체 감지 코드로 개발되었습니다. 그것은 많은 사람들의 엄청난 노력을 통합하고 있습니다. 그러나 우리는 지난 몇 년 동안 많은 고품질 저장소가 등장하는 것을 보았습니다.
이 시점 에서이 repo는 파이프 라인 및 코딩 스타일 측면에서 데이터가 아닌 것으로 생각하며 적극적으로 유지하지는 않을 것입니다. 이 저장소를 놀이터로 사용할 수는 있지만 West World of Object Detection을 탐구하기 위해 위의 저장소로 이동하는 것이 좋습니다!
이 프로젝트는 더 빠른 R-CNN 객체 감지 모델의 훈련을 가속화하기위한 더 빠른 R-CNN의 Pytorch 구현이 빠릅니다 . 최근에는 여러 가지 좋은 구현이 있습니다.
Pycaffe + Numpy를 기반으로 개발 된 RBGIRSHICK/PY-FASTER-RCNN
longcw/faster_rcnn_pytorch, pytorch + numpy를 기반으로 개발되었습니다
endernewton/tf-faster-rcnn, 텐서 플로우 + numpy를 기반으로 개발되었습니다
Ruotianluo/pytorch-faster-rcnn, pytorch + tensorflow + numpy를 기반으로 개발되었습니다
우리는 구현하는 동안 위의 구현, effecailly longcw/faster_rcnn_pytorch를 언급했습니다. 그러나 우리의 구현에는 위 구현과 비교하여 몇 가지 고유하고 새로운 기능이 있습니다.
순수한 Pytorch 코드입니다 . 우리는 모든 Numpy 구현을 Pytorch로 변환합니다!
다중 이미지 배치 트레이닝을 지원합니다 . 각 미니 배트에서 여러 이미지를 지원하기 위해 Dataloader, RPN, Roi-Pooling 등을 포함한 모든 레이어를 수정합니다.
여러 GPU 교육을 지원합니다 . 우리는 여러 GPU 래퍼 (NN.DataparAllel)를 사용하여 위의 두 기능의 장점으로 하나 이상의 GPU를 유연하게 사용할 수 있도록합니다.
세 가지 풀링 방법을 지원합니다 . ROI Pooing, ROI Align 및 ROI 작물의 세 가지 풀링 방법을 통합합니다. 더 중요한 것은 다중 이미지 배치 훈련을 지원하도록 모든 것을 수정합니다.
메모리 효율적입니다 . 이미지 종횡비와 비슷한 종횡비를 가진 그룹 이미지를 미니 배치로 제한합니다. 따라서 단일 타이탄 X (12GB)에서 Batchsize = 4 (4 개의 이미지)로 RESNET101 및 VGG16을 훈련시킬 수 있습니다. 8 GPU로 훈련 할 때 각 GPU의 최대 배치 크기는 3 (RES101)이며 총 24입니다.
더 빠릅니다 . 위의 수정에 따라 훈련이 훨씬 빠릅니다. 아래 표에서 Nvidia Titan XP의 교육 속도를보고합니다.
기능 피라미드 네트워크 (FPN)
마스크 R-CNN ( 전진 이미 Roytseng-TW에 의해 구현 됨)
그래프 R-CNN (장면 그래프 생성으로 확장)
우리는 두 가지 다른 네트워크 아키텍처의 VGG16 및 RESNET101을 사용하여 Pascal VOC, Coco 및 Visual Genome의 세 가지 데이터 세트에서 코드를 철저히 벤치마킹합니다. 다음은 결과입니다.
1). PASCAL VOC 2007 (기차/테스트 : 07TrainVal/07test, Scale = 600, ROI 정렬)
| 모델 | #gpus | 배치 크기 | LR | lr_decay | max_epoch | 시간/에포크 | mem/gpu | 지도 |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 | 1 | 1E-3 | 5 | 6 | 0.76 시간 | 3265MB | 70.1 |
| VGG-16 | 1 | 4 | 4E-3 | 8 | 9 | 0.50 시간 | 9083MB | 69.6 |
| VGG-16 | 8 | 16 | 1e-2 | 8 | 10 | 0.19 시간 | 5291MB | 69.4 |
| VGG-16 | 8 | 24 | 1e-2 | 10 | 11 | 0.16 시간 | 11303MB | 69.2 |
| RES-101 | 1 | 1 | 1E-3 | 5 | 7 | 0.88 시간 | 3200MB | 75.2 |
| RES-101 | 1 | 4 | 4E-3 | 8 | 10 | 0.60 시간 | 9700 MB | 74.9 |
| RES-101 | 8 | 16 | 1e-2 | 8 | 10 | 0.23 시간 | 8400MB | 75.2 |
| RES-101 | 8 | 24 | 1e-2 | 10 | 12 | 0.17 시간 | 10327MB | 75.1 |
2). Coco (기차/테스트 : Coco_train+Coco_val-Minival/Minival, scale = 800, max_size = 1200, ROI 정렬)
| 모델 | #gpus | 배치 크기 | LR | lr_decay | max_epoch | 시간/에포크 | mem/gpu | 지도 |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 8 | 16 | 1e-2 | 4 | 6 | 4.9 시간 | 7192 MB | 29.2 |
| RES-101 | 8 | 16 | 1e-2 | 4 | 6 | 6.0 시간 | 10956 MB | 36.2 |
| RES-101 | 8 | 16 | 1e-2 | 4 | 10 | 6.0 시간 | 10956 MB | 37.0 |
메모 . 위의 모델은 scale = 800을 사용하므로 테스트 명령 끝에 "--ls"를 추가해야합니다.
3). Coco (기차/테스트 : Coco_train+Coco_val-Minival/Minival, Scale = 600, Max_Size = 1000, ROI 정렬)
| 모델 | #gpus | 배치 크기 | LR | lr_decay | max_epoch | 시간/에포크 | mem/gpu | 지도 |
|---|---|---|---|---|---|---|---|---|
| RES-101 | 8 | 24 | 1e-2 | 4 | 6 | 5.4 시간 | 10659 MB | 33.9 |
| RES-101 | 8 | 24 | 1e-2 | 4 | 10 | 5.4 시간 | 10659 MB | 34.5 |
4). Visual Genome (기차/테스트 : VG_TRAIN/VG_TEST, SCALE = 600, MAX_SIZE = 1000, ROI 정렬, 범주 = 2500)
| 모델 | #gpus | 배치 크기 | LR | lr_decay | max_epoch | 시간/에포크 | mem/gpu | 지도 |
|---|---|---|---|---|---|---|---|---|
| VGG-16 | 1 P100 | 4 | 1E-3 | 5 | 20 | 3.7 HR | 12707 MB | 4.4 |
시각적 게놈에서 사전 여지가있는 탐지 모델을 제공 한 Remi에게 감사드립니다!
우선, 코드를 복제하십시오
git clone https://github.com/jwyang/faster-rcnn.pytorch.git
그런 다음 폴더를 만듭니다.
cd faster-rcnn.pytorch && mkdir data
PASCAL_VOC 07+12 : VOC 데이터 세트를 준비하려면 Py-Faster-RCNN의 지침을 따르십시오. 실제로, 당신은 다른 사람을 언급 할 수 있습니다. 데이터를 다운로드 한 후 폴더 데이터/에서 SoftLinks를 만듭니다.
Coco : 데이터를 준비하려면 Py-Faster-RCNN의 지침을 따르십시오.
시각적 게놈 : 시각적 게놈 데이터 세트를 준비하려면 상향식 지침을 따르십시오. 먼저 이미지 및 객체 주석 파일을 다운로드 한 다음이 리포지토리에 제공된 스크립트를 기반으로 어휘 및 정리 된 주석을 얻기 위해 기능을 수행해야합니다.
우리는 실험에서 VGG 및 RESNET101의 두 가지 사전 모델을 사용했습니다. 이 두 모델을 다음에서 다운로드 할 수 있습니다.
VGG16 : Dropbox, VT 서버
RESNET101 : Dropbox, VT 서버
그것들을 다운로드하여 데이터/pretrained_model/에 넣으십시오.
메모 . 우리는 Pytorch와 Caffe의 사전에 사전 된 모델을 비교하고 놀랍게도 Caffe 사교 모델이 Pytorch가 전기 된 것보다 약간 더 나은 성능을 발견했습니다. 위의 링크에서 Caffe 사회수 모델을 사용하여 결과를 재현하는 것이 좋습니다.
Pytorch 미리 훈련 된 모델을 사용하려면 BGR에서 RGB로 이미지를 전환하고 전기 모델에 사용 된 것과 동일한 데이터 변압기 (마이너스 평균 및 정규화)를 사용하십시오.
Ruotianluo/Pytorch-Faster-RCNN이 지적한대로 make.sh 파일에서 -arch 선택하여 CUDA 코드를 컴파일하십시오.
| GPU 모델 | 건축학 |
|---|---|
| Titanx (Maxwell/Pascal) | SM_52 |
| GTX 960m | SM_50 |
| GTX 1080 (TI) | SM_61 |
| 그리드 K520 (AWS G2.2xlarge) | SM_30 |
| Tesla K80 (AWS P2.xlarge) | SM_37 |
아키텍처 설정에 대한 자세한 내용은 여기 또는 여기에서 찾을 수 있습니다.
PIP를 사용하여 모든 파이썬 종속성을 설치하십시오.
pip install -r requirements.txt
다음 간단한 명령을 사용하여 CUDA 의존성을 컴파일하십시오.
cd lib
sh make.sh
NMS, Roi_Pooing, Roi_align 및 Roi_crop을 포함하여 필요한 모든 모듈을 컴파일합니다. 기본 버전은 Python 2.7로 컴파일됩니다. 다른 Python 버전을 사용하는 경우 직접 컴파일하십시오.
이 문제에서 지적한 바와 같이, 편집 중에 약간의 오류가 발생하면 CUDA 경로를 환경으로 내보내는 것을 놓칠 수 있습니다.
훈련하기 전에 훈련 된 모델을 저장하고로드하기 위해 올바른 디렉토리를 설정하십시오. 환경에 적응하려면 Trainval_net.py 및 test_net.py에서 "save_dir"및 "load_dir"인수를 변경하십시오.
pascal_voc에서 vgg16을 사용하여 더 빠른 R-CNN 모델을 훈련 시키려면 간단히 실행하십시오.
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net vgg16
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
여기서 'bs'는 기본 1의 배치 크기입니다. 또는 Pascal_voc에서 Resnet101로 훈련하십시오.
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py
--dataset pascal_voc --net res101
--bs $BATCH_SIZE --nw $WORKER_NUMBER
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda
위의 Batch_size 및 Worker_number는 GPU 메모리 크기에 따라 적응 적으로 설정할 수 있습니다. 12g 메모리가있는 타이탄 XP에서는 최대 4 일 수 있습니다 .
여러 (예 : 8) Titan XP GPU가 있다면 모두 사용하십시오! 노력하다:
python trainval_net.py --dataset pascal_voc --net vgg16
--bs 24 --nw 8
--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP
--cuda --mGPUs
코코 또는 시각적 게놈으로 훈련하려면 데이터 세트를 "코코"또는 'VG'로 변경하십시오.
PASCAL_VOC 테스트 세트에서 미리 훈련 된 VGG16 모델의 감지 성능을 평가하려면 간단히 실행하십시오.
python test_net.py --dataset pascal_voc --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda
특정 모델 세션, Checkepoch 및 Checkpoint (예 : 세션 = 1, epoch = 6, Checkpoint = 416을 지정하십시오.
미리 훈련 된 모델로 자신의 이미지에서 탐지를 실행하려면 위의 테이블에 나열된 전기 모델을 다운로드하거나 처음에는 모델을 훈련시킨 다음 폴더 $ Root/Images에 이미지를 추가 한 다음 실행하십시오.
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
그런 다음 폴더 $ root/images에서 감지 결과를 찾을 수 있습니다.
기본 Demo.py는 Pascal_Voc 범주를 지원합니다. 자신의 모델을 조정하려면 선을 변경해야합니다.
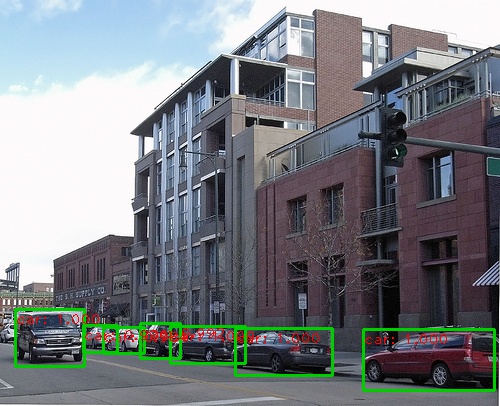
다음은 몇 가지 탐지 결과입니다.

실행하여 실시간 데모에서 웹캠을 사용할 수 있습니다.
python demo.py --net vgg16
--checksession $SESSION --checkepoch $EPOCH --checkpoint $CHECKPOINT
--cuda --load_dir path/to/model/directoy
--webcam $WEBCAM_ID
이미지 창을 클릭 한 다음 'Q'키를 누르면 데모가 중지됩니다.
이 프로젝트는 Jianwei Yang과 Jiasen Lu와 다른 많은 사람들이 똑같이 기여합니다 (감사합니다!).
@article{jjfaster2rcnn,
Author = {Jianwei Yang and Jiasen Lu and Dhruv Batra and Devi Parikh},
Title = {A Faster Pytorch Implementation of Faster R-CNN},
Journal = {https://github.com/jwyang/faster-rcnn.pytorch},
Year = {2017}
}
@inproceedings{renNIPS15fasterrcnn,
Author = {Shaoqing Ren and Kaiming He and Ross Girshick and Jian Sun},
Title = {Faster {R-CNN}: Towards Real-Time Object Detection
with Region Proposal Networks},
Booktitle = {Advances in Neural Information Processing Systems ({NIPS})},
Year = {2015}
}


