DnCNN
1.0.0
新闻: Drunet
最先进的denoising绩效
可用于插件图像修复

https://github.com/cszn/dpir/blob/master/main_dpir_denoising.py
I recommend to use the PyTorch code for training and testing. The model parameters of MatConvnet and PyTorch are same.
main_train_dncnn.py
main_test_dncnn.py
main_test_dncnn3_deblocking.py
import torch
import torch . nn as nn
def merge_bn ( model ):
''' merge all 'Conv+BN' (or 'TConv+BN') into 'Conv' (or 'TConv')
based on https://github.com/pytorch/pytorch/pull/901
by Kai Zhang ([email protected])
https://github.com/cszn/DnCNN
01/01/2019
'''
prev_m = None
for k , m in list ( model . named_children ()):
if ( isinstance ( m , nn . BatchNorm2d ) or isinstance ( m , nn . BatchNorm1d )) and ( isinstance ( prev_m , nn . Conv2d ) or isinstance ( prev_m , nn . Linear ) or isinstance ( prev_m , nn . ConvTranspose2d )):
w = prev_m . weight . data
if prev_m . bias is None :
zeros = torch . Tensor ( prev_m . out_channels ). zero_ (). type ( w . type ())
prev_m . bias = nn . Parameter ( zeros )
b = prev_m . bias . data
invstd = m . running_var . clone (). add_ ( m . eps ). pow_ ( - 0.5 )
if isinstance ( prev_m , nn . ConvTranspose2d ):
w . mul_ ( invstd . view ( 1 , w . size ( 1 ), 1 , 1 ). expand_as ( w ))
else :
w . mul_ ( invstd . view ( w . size ( 0 ), 1 , 1 , 1 ). expand_as ( w ))
b . add_ ( - m . running_mean ). mul_ ( invstd )
if m . affine :
if isinstance ( prev_m , nn . ConvTranspose2d ):
w . mul_ ( m . weight . data . view ( 1 , w . size ( 1 ), 1 , 1 ). expand_as ( w ))
else :
w . mul_ ( m . weight . data . view ( w . size ( 0 ), 1 , 1 , 1 ). expand_as ( w ))
b . mul_ ( m . weight . data ). add_ ( m . bias . data )
del model . _modules [ k ]
prev_m = m
merge_bn ( m )
def tidy_sequential ( model ):
for k , m in list ( model . named_children ()):
if isinstance ( m , nn . Sequential ):
if m . __len__ () == 1 :
model . _modules [ k ] = m . __getitem__ ( 0 )
tidy_sequential ( m )简单版本
DAGNN版本
[demos] Demo_test_DnCNN-.m 。
[模型]包括训练有素的高斯脱诺模型;一个用于高斯denoising,单图像超分辨率(SISR)和去除的单个模型。
[测试集] BSD68和SET10用于高斯denoising评估; SET5,SET14,BSD100和用于SISR评估的数据集; Classic5和Live1用于JPEG图像去阻止评估。
我已经培训了基于FFDNET的新的Flexible DNCNN(FDNCNN)型号。
FDNCNN可以通过单个模型处理[0,75]的噪声水平范围。
demo_fdncnn_gray.m
demo_fdncnn_gray_clip.m
demo_fdncnn_color.m
demo_fdncnn_color_clip.m
网络架构
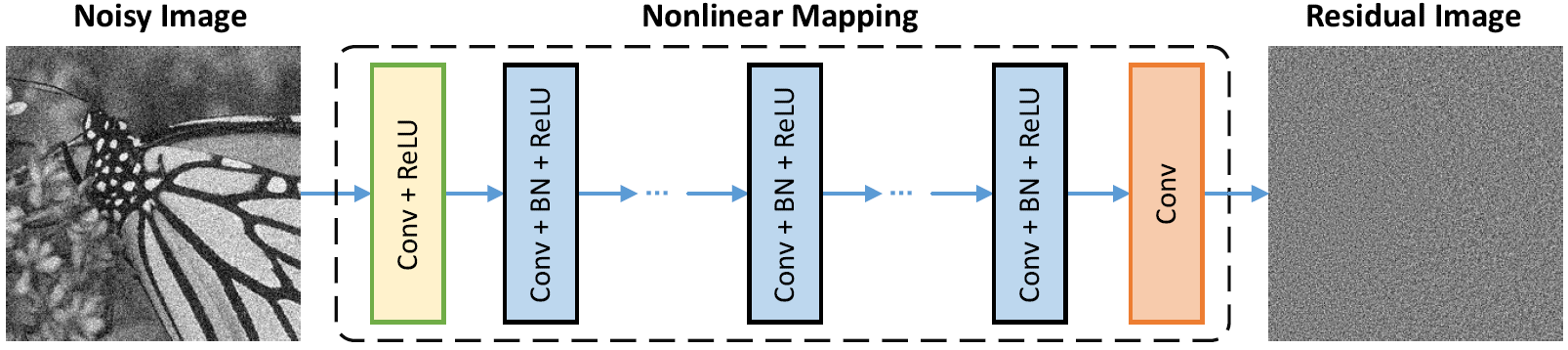
批次归一化和残留学习对高斯denoising有益(尤其是单个噪声水平)。嘈杂的图像的残留物被添加剂白色高斯噪声(AWGN)损坏,遵循恒定的高斯分布,在训练过程中稳定了批准。
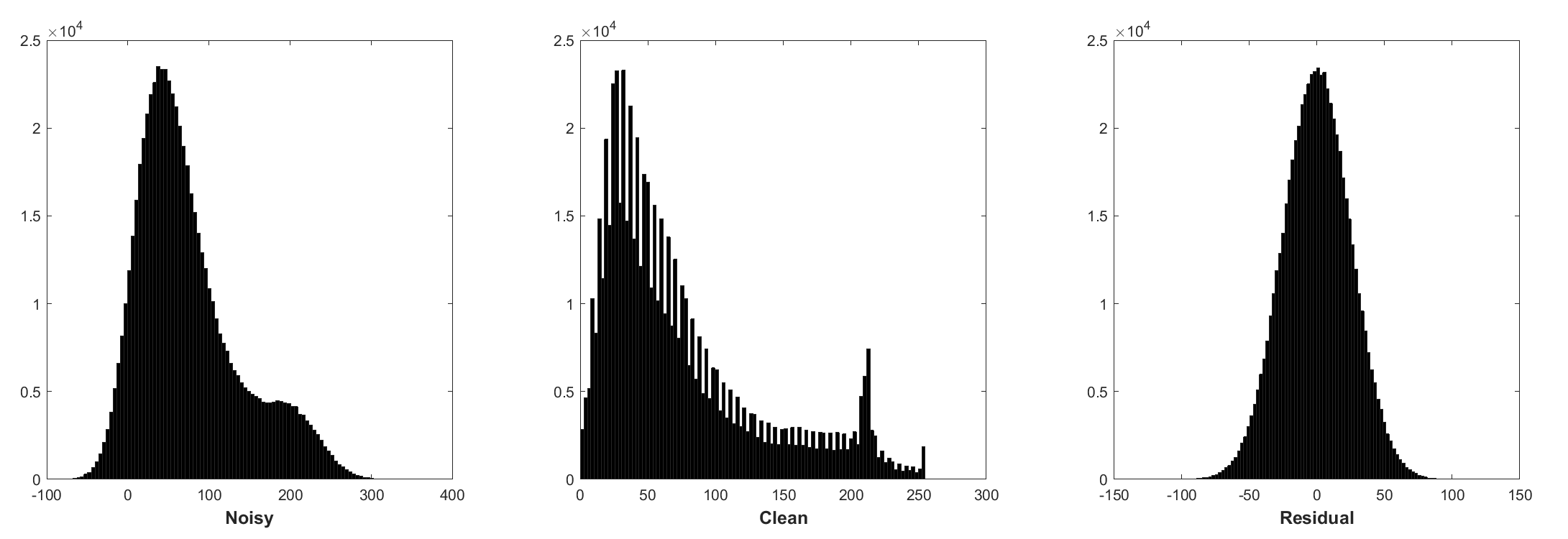
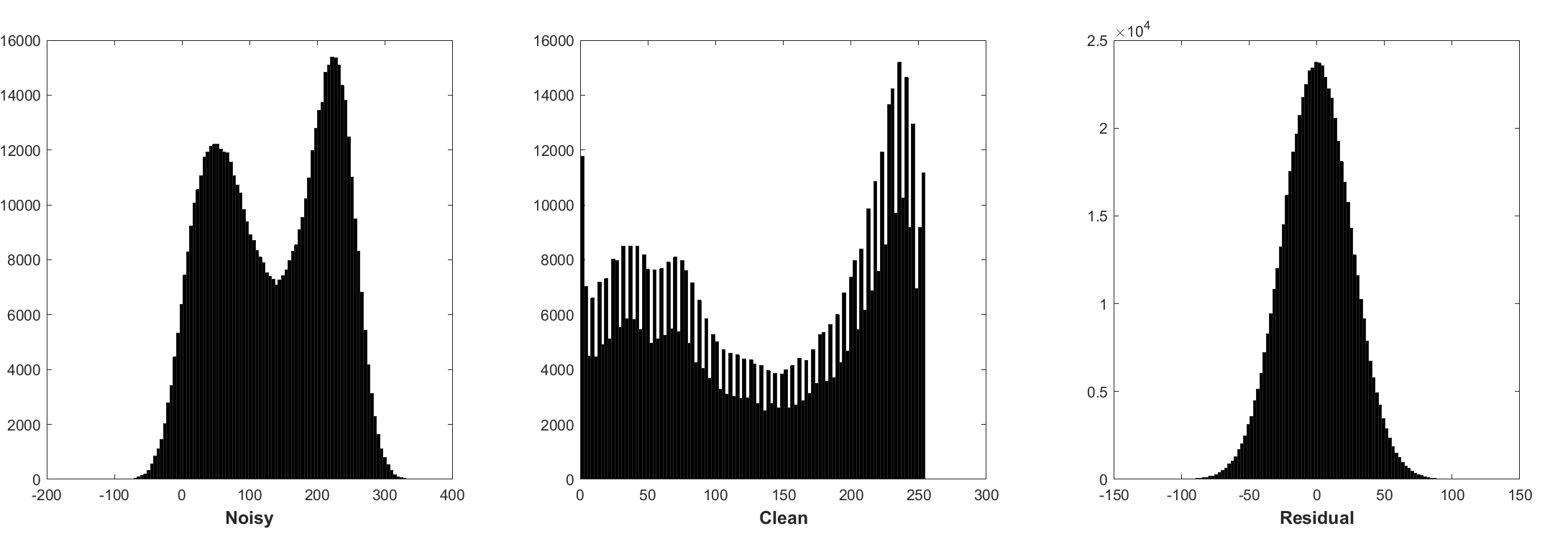
预测残差可以解释为在起点(即嘈杂的图像)上执行一个梯度下降推理步骤。
DNCNN中的参数主要代表图像先验(任务无关),因此可以学习一个用于不同任务的单个模型,例如图像DeNoising,图像超分辨率和JPEG图像脱机。
左侧是因不同降解而损坏的输入映像,右侧是DNCNN-3的恢复图像。


BSD68数据集上不同方法的平均PSNR(DB)结果。
| 噪音水平 | BM3D | wnnm | epll | MLP | CSF | tnrd | dncnn | dncnn-b | fdncnn | Drunet |
|---|---|---|---|---|---|---|---|---|---|---|
| 15 | 31.07 | 31.37 | 31.21 | - | 31.24 | 31.42 | 31.73 | 31.61 | 31.69 | 31.91 |
| 25 | 28.57 | 28.83 | 28.68 | 28.96 | 28.74 | 28.92 | 29.23 | 29.16 | 29.22 | 29.48 |
| 50 | 25.62 | 25.87 | 25.67 | 26.03 | - | 25.97 | 26.23 | 26.23 | 26.27 | 26.59 |
视觉结果
左侧是AWGN损坏的嘈杂图像,中间是DNCNN的DeNoized图像,右边是地面真相。









在BSD68数据集上使用噪声15、25和50的高斯denosing方法的平均PSNR(DB)/SSIM结果,set5,set14,bsd100和urban100数据集,jpeg图像deplocking,jpeg Image DETAS,jpeg factor fimest 5、25和40上的单图像超级分辨率,jpeg firces firples filess filess filess firce active firces firce firces classial 10,20,30和30和经典5和经典5和经典5和经典5和40。
| 数据集 | 噪音水平 | BM3D | tnrd | DNCNN-3 |
|---|---|---|---|---|
| 15 | 31.08 / 0.8722 | 31.42 / 0.8826 | 31.46 / 0.8826 | |
| BSD68 | 25 | 28.57 / 0.8017 | 28.92 / 0.8157 | 29.02 / 0.8190 |
| 50 | 25.62 / 0.6869 | 25.97 / 0.7029 | 26.10 / 0.7076 |
| 数据集 | 升级因素 | tnrd | VDSR | DNCNN-3 |
|---|---|---|---|---|
| 2 | 36.86 / 0.9556 | 37.56 / 0.9591 | 37.58 / 0.9590 | |
| set5 | 3 | 33.18 / 0.9152 | 33.67 / 0.9220 | 33.75 / 0.9222 |
| 4 | 30.85 / 0.8732 | 31.35 / 0.8845 | 31.40 / 0.8845 | |
| 2 | 32.51 / 0.9069 | 33.02 / 0.9128 | 33.03 / 0.9128 | |
| set14 | 3 | 29.43 / 0.8232 | 29.77 / 0.8318 | 29.81 / 0.8321 |
| 4 | 27.66 / 0.7563 | 27.99 / 0.7659 | 28.04 / 0.7672 | |
| 2 | 31.40 / 0.8878 | 31.89 / 0.8961 | 31.90 / 0.8961 | |
| BSD100 | 3 | 28.50 / 0.7881 | 28.82 / 0.7980 | 28.85 / 0.7981 |
| 4 | 27.00 / 0.7140 | 27.28 / 0.7256 | 27.29 / 0.7253 | |
| 2 | 29.70 / 0.8994 | 30.76 / 0.9143 | 30.74 / 0.9139 | |
| Urban100 | 3 | 26.42 / 0.8076 | 27.13 / 0.8283 | 27.15 / 0.8276 |
| 4 | 24.61 / 0.7291 | 25.17 / 0.7528 | 25.20 / 0.7521 |
| 数据集 | 质量因素 | AR-CNN | tnrd | DNCNN-3 |
|---|---|---|---|---|
| 经典5 | 10 | 29.03 / 0.7929 | 29.28 / 0.7992 | 29.40 / 0.8026 |
| 20 | 31.15 / 0.8517 | 31.47 / 0.8576 | 31.63 / 0.8610 | |
| 30 | 32.51 / 0.8806 | 32.78 / 0.8837 | 32.91 / 0.8861 | |
| 40 | 33.34 / 0.8953 | - | 33.77 / 0.9003 | |
| Live1 | 10 | 28.96 / 0.8076 | 29.15 / 0.8111 | 29.19 / 0.8123 |
| 20 | 31.29 / 0.8733 | 31.46 / 0.8769 | 31.59 / 0.8802 | |
| 30 | 32.67 / 0.9043 | 32.84 / 0.9059 | 32.98 / 0.9090 | |
| 40 | 33.63 / 0.9198 | - | 33.96 / 0.9247 |
或者只是MATLAB R2015B来测试模型。
dncnn/demo_test_dncnn.m
4A4B5B8中的第64至65行
@article { zhang2017beyond ,
title = { Beyond a {Gaussian} denoiser: Residual learning of deep {CNN} for image denoising } ,
author = { Zhang, Kai and Zuo, Wangmeng and Chen, Yunjin and Meng, Deyu and Zhang, Lei } ,
journal = { IEEE Transactions on Image Processing } ,
year = { 2017 } ,
volume = { 26 } ,
number = { 7 } ,
pages = { 3142-3155 } ,
}
@article { zhang2020plug ,
title = { Plug-and-Play Image Restoration with Deep Denoiser Prior } ,
author = { Zhang, Kai and Li, Yawei and Zuo, Wangmeng and Zhang, Lei and Van Gool, Luc and Timofte, Radu } ,
journal = { arXiv preprint } ,
year = { 2020 }
}=================================================================
@Inbook{zuo2018convolutional,
author={Zuo, Wangmeng and Zhang, Kai and Zhang, Lei},
editor={Bertalm{'i}o, Marcelo},
title={Convolutional Neural Networks for Image Denoising and Restoration},
bookTitle={Denoising of Photographic Images and Video: Fundamentals, Open Challenges and New Trends},
year={2018},
publisher={Springer International Publishing},
address={Cham},
pages={93--123},
isbn={978-3-319-96029-6},
doi={10.1007/978-3-319-96029-6_4},
url={https://doi.org/10.1007/978-3-319-96029-6_4}
}
尽管已进行了充分研究的图像,但对真实图像降级的工作很少。主要的困难源于以下事实:真实的噪声比AWGN复杂得多,并且彻底评估Denoiser的性能并不是一件容易的事。图4.15显示了现实世界中的四种典型噪声类型。可以看出,这些声音的特征非常不同,单个噪声水平可能不足以参数化这些噪声类型。在大多数情况下,Denoiser只能在某个噪声模型下正常工作。例如,训练AWGN去除的Denoising模型对于混合高斯和泊松噪声无效。这在直觉上是合理的,因为基于CNN的方法可以视为等式的一般情况。 (4.3)和重要的数据保真度术语对应于退化过程。尽管如此,由于以下原因,驱除AWGN的图像是有价值的。首先,它是评估不同基于CNN的denoising方法的有效性的理想测试床。其次,在通过可变分割技术的展开推理中,可以通过依次求解一系列高斯denoising子问题来解决许多图像恢复问题,从而进一步拓宽了应用领域。

为了提高CNN Denoiser的实用性,也许最直接的方法是捕获足够数量的真正嘈杂清洁的训练对进行培训,以便可以涵盖真正的退化空间。该解决方案的优势是不需要知道复杂的降解过程。但是,由于需要仔细的后处理步骤,例如空间比对和照明校正,因此得出嘈杂的相应图像并不是一项琐碎的任务。另外,可以模拟真正的退化过程,以合成清洁图像的嘈杂图像。但是,准确地对复杂的降解过程进行建模并不容易。特别是,在不同的相机中,噪声模型可能不同。然而,实际上,最好将某种噪声类型大致建模以进行训练,然后将学习的CNN模型用于特定于类型的denoisising。
除了培训数据外,强大的体系结构和强大的培训还起着至关重要的作用,为CNN Denoiser的成功而言。对于强大的体系结构,设计一个深度尺度的CNN,涉及粗到精细的过程是一个有希望的方向。这种网络有望继承多尺度的优点:(i)噪声水平在较大的尺度下降低; (ii)多尺度程序可以缓解普遍存在的低频噪声; (iii)在降解之前对图像进行缩减采样可以有效地扩大所提交的接受。为了进行强大的训练,通过生成对抗网络(GAN)进行真实图像Denoing的DeNoiser的有效性仍然是进一步的研究。基于GAN的DeNoising的主要思想是引入对抗性损失,以提高DeNocied Image的感知质量。此外,GAN的独特优势是它可以进行无监督的学习。更具体地说,没有地面真相的嘈杂形象可以在培训中使用。到目前为止,我们提供了几种可能的解决方案来改善CNN Denoiser的可实用性。我们应该注意,这些解决方案可以合并以进一步提高性能。


