DnCNN
1.0.0
ข่าว: Drunet
ประสิทธิภาพที่ทันสมัย denoising
สามารถใช้สำหรับการฟื้นฟูภาพแบบปลั๊กแอนด์เพลย์

https://github.com/cszn/dpir/blob/master/main_dpir_denoising.py
I recommend to use the PyTorch code for training and testing. The model parameters of MatConvnet and PyTorch are same.
main_train_dncnn.py
main_test_dncnn.py
main_test_dncnnn3_deblocking.py
import torch
import torch . nn as nn
def merge_bn ( model ):
''' merge all 'Conv+BN' (or 'TConv+BN') into 'Conv' (or 'TConv')
based on https://github.com/pytorch/pytorch/pull/901
by Kai Zhang ([email protected])
https://github.com/cszn/DnCNN
01/01/2019
'''
prev_m = None
for k , m in list ( model . named_children ()):
if ( isinstance ( m , nn . BatchNorm2d ) or isinstance ( m , nn . BatchNorm1d )) and ( isinstance ( prev_m , nn . Conv2d ) or isinstance ( prev_m , nn . Linear ) or isinstance ( prev_m , nn . ConvTranspose2d )):
w = prev_m . weight . data
if prev_m . bias is None :
zeros = torch . Tensor ( prev_m . out_channels ). zero_ (). type ( w . type ())
prev_m . bias = nn . Parameter ( zeros )
b = prev_m . bias . data
invstd = m . running_var . clone (). add_ ( m . eps ). pow_ ( - 0.5 )
if isinstance ( prev_m , nn . ConvTranspose2d ):
w . mul_ ( invstd . view ( 1 , w . size ( 1 ), 1 , 1 ). expand_as ( w ))
else :
w . mul_ ( invstd . view ( w . size ( 0 ), 1 , 1 , 1 ). expand_as ( w ))
b . add_ ( - m . running_mean ). mul_ ( invstd )
if m . affine :
if isinstance ( prev_m , nn . ConvTranspose2d ):
w . mul_ ( m . weight . data . view ( 1 , w . size ( 1 ), 1 , 1 ). expand_as ( w ))
else :
w . mul_ ( m . weight . data . view ( w . size ( 0 ), 1 , 1 , 1 ). expand_as ( w ))
b . mul_ ( m . weight . data ). add_ ( m . bias . data )
del model . _modules [ k ]
prev_m = m
merge_bn ( m )
def tidy_sequential ( model ):
for k , m in list ( model . named_children ()):
if isinstance ( m , nn . Sequential ):
if m . __len__ () == 1 :
model . _modules [ k ] = m . __getitem__ ( 0 )
tidy_sequential ( m )เวอร์ชัน Simplenn
เวอร์ชัน dagnn
[DEMOS] Demo_test_DnCNN-.m
[รุ่น] รวมถึงโมเดลที่ผ่านการฝึกอบรมสำหรับ Gaussian denoising; รุ่นเดียวสำหรับ Gaussian denoising, ภาพเดี่ยว Super-Resolution (SISR) และการทำลายล้าง
[testsets] BSD68 และ SET10 สำหรับการประเมินผลการ denoising แบบเกาส์ SET5, SET14, BSD100 และ Urban100 ชุดข้อมูลสำหรับการประเมินผล SISR; Classic5 และ Live1 สำหรับการประเมินผลการทำลายภาพ JPEG
ฉันได้รับการฝึกอบรมแบบจำลอง DNCNN (FDNCNN) ที่ยืดหยุ่นใหม่ตาม FFDNET
FDNCNN สามารถจัดการช่วงระดับเสียงของ [0, 75] ผ่านรุ่นเดียว
demo_fdncnn_gray.m
demo_fdncnn_gray_clip.m
demo_fdncnn_color.m
demo_fdncnn_color_clip.m
สถาปัตยกรรมเครือข่าย
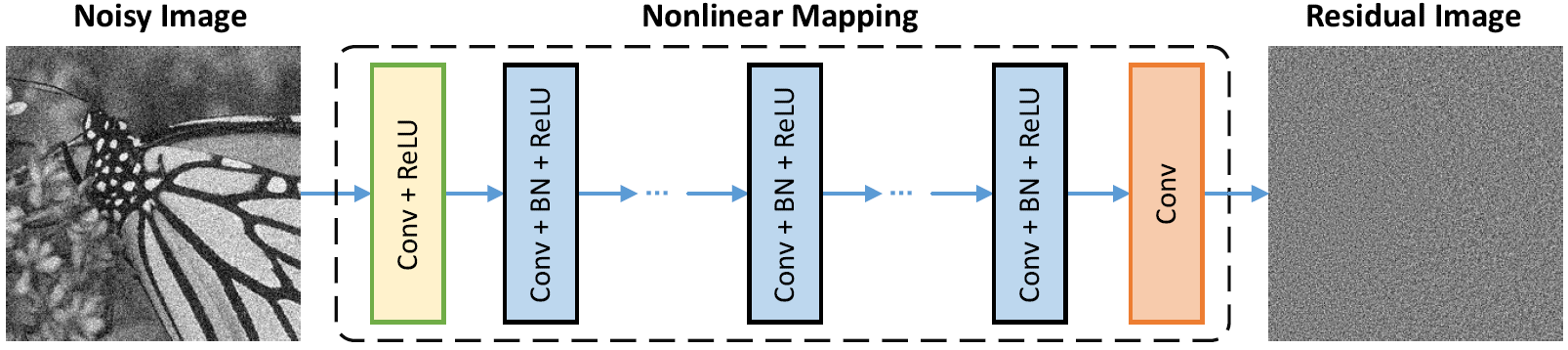
การทำให้เป็นมาตรฐานแบบแบทช์และการเรียนรู้ที่เหลือเป็นประโยชน์ต่อการปฏิเสธแบบเกาส์เซียน (โดยเฉพาะอย่างยิ่งสำหรับระดับเสียงรบกวนเดียว) ส่วนที่เหลือของภาพที่มีเสียงดังเสียหายโดยเสียงรบกวนแบบเกาส์สีขาว (AWGN) ตามการแจกแจงแบบเกาส์เซียนคงที่
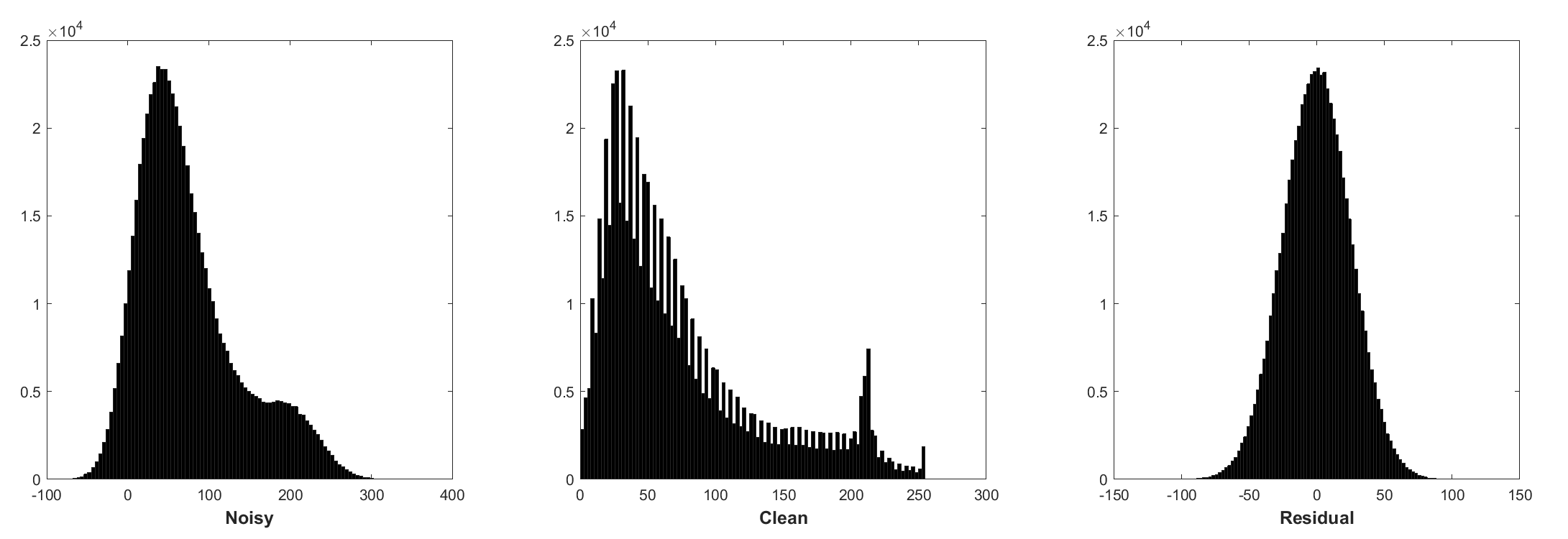
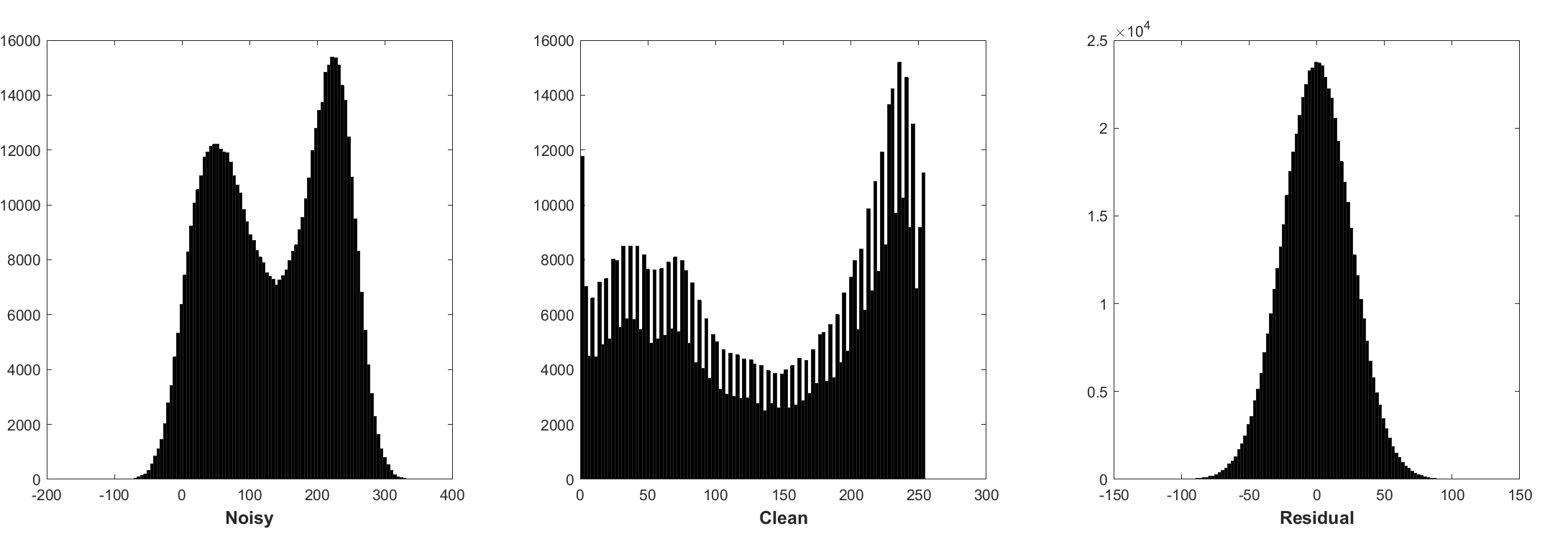
การทำนายการตกค้างสามารถตีความได้ว่าเป็นการดำเนินการตามขั้นตอนการอนุมานการไล่ระดับสีหนึ่งขั้นที่จุดเริ่มต้น (เช่นภาพที่มีเสียงดัง)
พารามิเตอร์ใน DNCNN ส่วนใหญ่เป็นตัวแทนของภาพ priors (ไม่อิสระจากงาน) ดังนั้นจึงเป็นไปได้ที่จะเรียนรู้โมเดลเดียวสำหรับงานที่แตกต่างกันเช่นภาพ denoising ภาพความละเอียดสูงและการทำลายภาพ JPEG
ด้านซ้ายคือภาพอินพุตเสียหายจากการย่อยสลายที่แตกต่างกันทางด้านขวาคือภาพที่ได้รับการบูรณะโดย DNCNN-3


ผลลัพธ์ PSNR เฉลี่ย (dB) ของวิธีการต่าง ๆ ในชุดข้อมูล BSD68
| ระดับเสียงรบกวน | BM3D | wnnm | เครื่องปั่นไฟ | MLP | น้ำไขสันหลัง | tnrd | dncnn | dncnn-b | fdncnn | คนขี้เกียจ |
|---|---|---|---|---|---|---|---|---|---|---|
| 15 | 31.07 | 31.37 | 31.21 | - | 31.24 | 31.42 | 31.73 | 31.61 | 31.69 | 31.91 |
| 25 | 28.57 | 28.83 | 28.68 | 28.96 | 28.74 | 28.92 | 29.23 | 29.16 | 29.22 | 29.48 |
| 50 | 25.62 | 25.87 | 25.67 | 26.03 | - | 25.97 | 26.23 | 26.23 | 26.27 | 26.59 |
ผลการมองเห็น
ด้านซ้ายคือภาพที่มีเสียงดังเสียหายโดย AWGN ตรงกลางเป็นภาพที่ถูก denoised โดย DNCNN ทางด้านขวาคือความจริงพื้นดิน









ค่าเฉลี่ย PSNR (dB)/SSIM ของวิธีการที่แตกต่างกันสำหรับ gaussian denoising ด้วยเสียงรบกวนระดับ 15, 25 และ 50 ในชุดข้อมูล BSD68, ภาพเดี่ยวภาพซุปเปอร์ความละเอียดสูงพร้อมปัจจัยการลดขนาด 2, 3 และ 40 ใน SET5, SET14, BSD100 และ URBAN100 DATASETS
| ชุดข้อมูล | ระดับเสียงรบกวน | BM3D | tnrd | dncnn-3 |
|---|---|---|---|---|
| 15 | 31.08 / 0.8722 | 31.42 / 0.8826 | 31.46 / 0.8826 | |
| BSD68 | 25 | 28.57 / 0.8017 | 28.92 / 0.8157 | 29.02 / 0.8190 |
| 50 | 25.62 / 0.6869 | 25.97 / 0.7029 | 26.10 / 0.7076 |
| ชุดข้อมูล | ปัจจัยการลดขนาด | tnrd | VDSR | dncnn-3 |
|---|---|---|---|---|
| 2 | 36.86 / 0.9556 | 37.56 / 0.9591 | 37.58 / 0.9590 | |
| set5 | 3 | 33.18 / 0.9152 | 33.67 / 0.9220 | 33.75 / 0.9222 |
| 4 | 30.85 / 0.8732 | 31.35 / 0.8845 | 31.40 / 0.8845 | |
| 2 | 32.51 / 0.9069 | 33.02 / 0.9128 | 33.03 / 0.9128 | |
| set14 | 3 | 29.43 / 0.8232 | 29.77 / 0.8318 | 29.81 / 0.8321 |
| 4 | 27.66 / 0.7563 | 27.99 / 0.7659 | 28.04 / 0.7672 | |
| 2 | 31.40 / 0.8878 | 31.89 / 0.8961 | 31.90 / 0.8961 | |
| BSD100 | 3 | 28.50 / 0.7881 | 28.82 / 0.7980 | 28.85 / 0.7981 |
| 4 | 27.00 / 0.7140 | 27.28 / 0.7256 | 27.29 / 0.7253 | |
| 2 | 29.70 / 0.8994 | 30.76 / 0.9143 | 30.74 / 0.9139 | |
| Urban100 | 3 | 26.42 / 0.8076 | 27.13 / 0.8283 | 27.15 / 0.8276 |
| 4 | 24.61 / 0.7291 | 25.17 / 0.7528 | 25.20 / 0.7521 |
| ชุดข้อมูล | ปัจจัยคุณภาพ | ar-cnn | tnrd | dncnn-3 |
|---|---|---|---|---|
| คลาสสิก 5 | 10 | 29.03 / 0.7929 | 29.28 / 0.7992 | 29.40 / 0.8026 |
| 20 | 31.15 / 0.8517 | 31.47 / 0.8576 | 31.63 / 0.8610 | |
| 30 | 32.51 / 0.8806 | 32.78 / 0.8837 | 32.91 / 0.8861 | |
| 40 | 33.34 / 0.8953 | - | 33.77 / 0.9003 | |
| Live1 | 10 | 28.96 / 0.8076 | 29.15 / 0.8111 | 29.19 / 0.8123 |
| 20 | 31.29 / 0.8733 | 31.46 / 0.8769 | 31.59 / 0.8802 | |
| 30 | 32.67 / 0.9043 | 32.84 / 0.9059 | 32.98 / 0.9090 | |
| 40 | 33.63 / 0.9198 | - | 33.96 / 0.9247 |
หรือเพียงแค่ MATLAB R2015B เพื่อทดสอบโมเดล
dncnn/demo_test_dncnn.m
บรรทัด 64 ถึง 65 ใน 4A4B5B8
@article { zhang2017beyond ,
title = { Beyond a {Gaussian} denoiser: Residual learning of deep {CNN} for image denoising } ,
author = { Zhang, Kai and Zuo, Wangmeng and Chen, Yunjin and Meng, Deyu and Zhang, Lei } ,
journal = { IEEE Transactions on Image Processing } ,
year = { 2017 } ,
volume = { 26 } ,
number = { 7 } ,
pages = { 3142-3155 } ,
}
@article { zhang2020plug ,
title = { Plug-and-Play Image Restoration with Deep Denoiser Prior } ,
author = { Zhang, Kai and Li, Yawei and Zuo, Wangmeng and Zhang, Lei and Van Gool, Luc and Timofte, Radu } ,
journal = { arXiv preprint } ,
year = { 2020 }
}-
@Inbook{zuo2018convolutional,
author={Zuo, Wangmeng and Zhang, Kai and Zhang, Lei},
editor={Bertalm{'i}o, Marcelo},
title={Convolutional Neural Networks for Image Denoising and Restoration},
bookTitle={Denoising of Photographic Images and Video: Fundamentals, Open Challenges and New Trends},
year={2018},
publisher={Springer International Publishing},
address={Cham},
pages={93--123},
isbn={978-3-319-96029-6},
doi={10.1007/978-3-319-96029-6_4},
url={https://doi.org/10.1007/978-3-319-96029-6_4}
}
ในขณะที่ภาพ denoising สำหรับการกำจัด AWGN นั้นได้รับการศึกษาอย่างดี แต่ก็มีการทำงานเล็ก ๆ น้อย ๆ เกี่ยวกับภาพที่แท้จริง ความยากลำบากหลักเกิดขึ้นจากความจริงที่ว่าเสียงจริงนั้นซับซ้อนกว่า AWGN มากและไม่ใช่เรื่องง่ายที่จะประเมินประสิทธิภาพของ denoiser อย่างละเอียด รูปที่ 4.15 แสดงเสียงรบกวนทั่วไปสี่ประเภทในโลกแห่งความเป็นจริง จะเห็นได้ว่าลักษณะของเสียงเหล่านั้นแตกต่างกันมากและระดับเสียงรบกวนเดียวอาจไม่เพียงพอที่จะกำหนดพารามิเตอร์ประเภทเสียงเหล่านั้น ในกรณีส่วนใหญ่ denoiser สามารถทำงานได้ดีภายใต้รูปแบบเสียงที่แน่นอน ตัวอย่างเช่นรูปแบบ denoising ที่ได้รับการฝึกฝนสำหรับการกำจัด AWGN นั้นไม่มีประสิทธิภาพสำหรับการกำจัดเสียงรบกวนแบบเกาส์และปัวซอง สิ่งนี้มีเหตุผลอย่างสังหรณ์ใจเนื่องจากวิธีการที่ใช้ CNN สามารถถือว่าเป็นกรณีทั่วไปของ Eq (4.3) และคำศัพท์ความเที่ยงตรงของข้อมูลที่สำคัญสอดคล้องกับกระบวนการย่อยสลาย ทั้งๆที่สิ่งนี้ภาพ denoising สำหรับการกำจัด AWGN นั้นมีค่าเนื่องจากเหตุผลดังต่อไปนี้ ประการแรกมันเป็นเตียงทดสอบที่เหมาะสำหรับการประเมินประสิทธิภาพของวิธีการ denoising ที่ใช้ CNN ที่แตกต่างกัน ประการที่สองในการอนุมานที่ไม่ได้ควบคุมผ่านเทคนิคการแยกตัวแปรปัญหาการฟื้นฟูภาพจำนวนมากสามารถแก้ไขได้โดยการแก้ปัญหาย่อยของ Gaussian denoising subproblems ซึ่งจะขยายขอบเขตแอปพลิเคชันให้กว้างขึ้น

เพื่อปรับปรุงความสามารถในการปฏิบัติของ CNN denoiser บางทีวิธีที่ตรงไปตรงมาที่สุดคือการจับคู่การฝึกอบรมที่มีเสียงดังจริง ๆ สำหรับการฝึกอบรมเพื่อให้พื้นที่การเสื่อมสภาพที่แท้จริงสามารถครอบคลุมได้ โซลูชันนี้มีข้อได้เปรียบที่ไม่จำเป็นต้องรู้กระบวนการย่อยสลายที่ซับซ้อน อย่างไรก็ตามการได้รับภาพที่สะอาดที่สอดคล้องกันของภาพที่มีเสียงดังไม่ใช่งานเล็กน้อยเนื่องจากความต้องการขั้นตอนหลังการประมวลผลอย่างระมัดระวังเช่นการจัดตำแหน่งเชิงพื้นที่และการแก้ไขการส่องสว่าง อีกทางเลือกหนึ่งสามารถจำลองกระบวนการย่อยสลายที่แท้จริงเพื่อสังเคราะห์ภาพที่มีเสียงดังสำหรับภาพที่สะอาด อย่างไรก็ตามมันไม่ใช่เรื่องง่ายที่จะจำลองกระบวนการย่อยสลายที่ซับซ้อนอย่างแม่นยำ โดยเฉพาะอย่างยิ่งโมเดลเสียงอาจแตกต่างกันในกล้องที่แตกต่างกัน อย่างไรก็ตามมันเป็นสิ่งที่ดีกว่าที่จะสร้างแบบจำลองประเภทเสียงที่แน่นอนสำหรับการฝึกอบรมจากนั้นใช้โมเดล CNN ที่เรียนรู้สำหรับ denoising เฉพาะประเภท
นอกเหนือจากข้อมูลการฝึกอบรมสถาปัตยกรรมที่แข็งแกร่งและการฝึกอบรมที่แข็งแกร่งยังมีบทบาทสำคัญสำหรับความสำเร็จของ CNN denoiser สำหรับสถาปัตยกรรมที่มีประสิทธิภาพการออกแบบ CNN แบบหลายระดับลึกซึ่งเกี่ยวข้องกับขั้นตอนที่หยาบถึงขั้นตอนเป็นทิศทางที่มีแนวโน้ม เครือข่ายดังกล่าวคาดว่าจะสืบทอดข้อดีของ multiscale: (i) ระดับเสียงลดลงในระดับที่ใหญ่ขึ้น (ii) เสียงความถี่ต่ำที่แพร่หลายสามารถบรรเทาได้โดยขั้นตอน multiscale; และ (iii) downsampling ภาพก่อน denoising สามารถขยายการยื่นแบบเปิดกว้างได้อย่างมีประสิทธิภาพ สำหรับการฝึกอบรมที่มีประสิทธิภาพประสิทธิภาพของ Denoiser ที่ได้รับการฝึกฝนด้วยเครือข่ายฝ่ายตรงข้าม (GAN) สำหรับภาพลักษณ์จริงยังคงยังคงมีการสอบสวนต่อไป แนวคิดหลักของ denoising ที่ใช้ GAN คือการแนะนำการสูญเสียที่เป็นปฏิปักษ์เพื่อปรับปรุงคุณภาพการรับรู้ของภาพ denoised นอกจากนี้ข้อได้เปรียบที่โดดเด่นของ GAN ก็คือมันสามารถเรียนรู้ได้โดยไม่ได้รับการดูแล โดยเฉพาะอย่างยิ่งภาพที่มีเสียงดังที่ไม่มีความจริงพื้นดินสามารถใช้ในการฝึกอบรม จนถึงตอนนี้เราได้จัดหาวิธีแก้ปัญหาที่เป็นไปได้หลายประการเพื่อปรับปรุงความสามารถในการปฏิบัติของ CNN denoiser เราควรทราบว่าสามารถรวมโซลูชันเหล่านั้นเพื่อปรับปรุงประสิทธิภาพเพิ่มเติม


