DnCNN
1.0.0
뉴스 : Drunet
최첨단 비난 성과
플러그 앤 플레이 이미지 복원에 사용할 수 있습니다

https://github.com/cszn/dpir/blob/master/main_dpir_denoing.py
I recommend to use the PyTorch code for training and testing. The model parameters of MatConvnet and PyTorch are same.
main_train_dncnn.py
main_test_dncnn.py
main_test_dncnn3_deblocking.py
import torch
import torch . nn as nn
def merge_bn ( model ):
''' merge all 'Conv+BN' (or 'TConv+BN') into 'Conv' (or 'TConv')
based on https://github.com/pytorch/pytorch/pull/901
by Kai Zhang ([email protected])
https://github.com/cszn/DnCNN
01/01/2019
'''
prev_m = None
for k , m in list ( model . named_children ()):
if ( isinstance ( m , nn . BatchNorm2d ) or isinstance ( m , nn . BatchNorm1d )) and ( isinstance ( prev_m , nn . Conv2d ) or isinstance ( prev_m , nn . Linear ) or isinstance ( prev_m , nn . ConvTranspose2d )):
w = prev_m . weight . data
if prev_m . bias is None :
zeros = torch . Tensor ( prev_m . out_channels ). zero_ (). type ( w . type ())
prev_m . bias = nn . Parameter ( zeros )
b = prev_m . bias . data
invstd = m . running_var . clone (). add_ ( m . eps ). pow_ ( - 0.5 )
if isinstance ( prev_m , nn . ConvTranspose2d ):
w . mul_ ( invstd . view ( 1 , w . size ( 1 ), 1 , 1 ). expand_as ( w ))
else :
w . mul_ ( invstd . view ( w . size ( 0 ), 1 , 1 , 1 ). expand_as ( w ))
b . add_ ( - m . running_mean ). mul_ ( invstd )
if m . affine :
if isinstance ( prev_m , nn . ConvTranspose2d ):
w . mul_ ( m . weight . data . view ( 1 , w . size ( 1 ), 1 , 1 ). expand_as ( w ))
else :
w . mul_ ( m . weight . data . view ( w . size ( 0 ), 1 , 1 , 1 ). expand_as ( w ))
b . mul_ ( m . weight . data ). add_ ( m . bias . data )
del model . _modules [ k ]
prev_m = m
merge_bn ( m )
def tidy_sequential ( model ):
for k , m in list ( model . named_children ()):
if isinstance ( m , nn . Sequential ):
if m . __len__ () == 1 :
model . _modules [ k ] = m . __getitem__ ( 0 )
tidy_sequential ( m )단순한 버전
DAGNN 버전
[데모] Demo_test_DnCNN-.m .
[모델] 가우스 거부를위한 훈련 된 모델을 포함한 [모델]; 가우스 노이즈, 단일 이미지 슈퍼 레벨 (SISR) 및 탈 블로킹을위한 단일 모델.
가우시안 비난 평가를위한 [테스트 세트] BSD68 및 SET10; SISR 평가를위한 SET5, SET14, BSD100 및 URBAN100 데이터 세트; JPEG 이미지 디 블로킹 평가를위한 Classic5 및 Live1.
FFDNet을 기반으로 새로운 Flexible DNCNN (FDNCNN) 모델을 교육했습니다.
FDNCNN은 단일 모델을 통해 [0, 75]의 노이즈 레벨 범위를 처리 할 수 있습니다.
demo_fdncnn_gray.m
demo_fdncnn_gray_clip.m
demo_fdncnn_color.m
demo_fdncnn_color_clip.m
네트워크 아키텍처
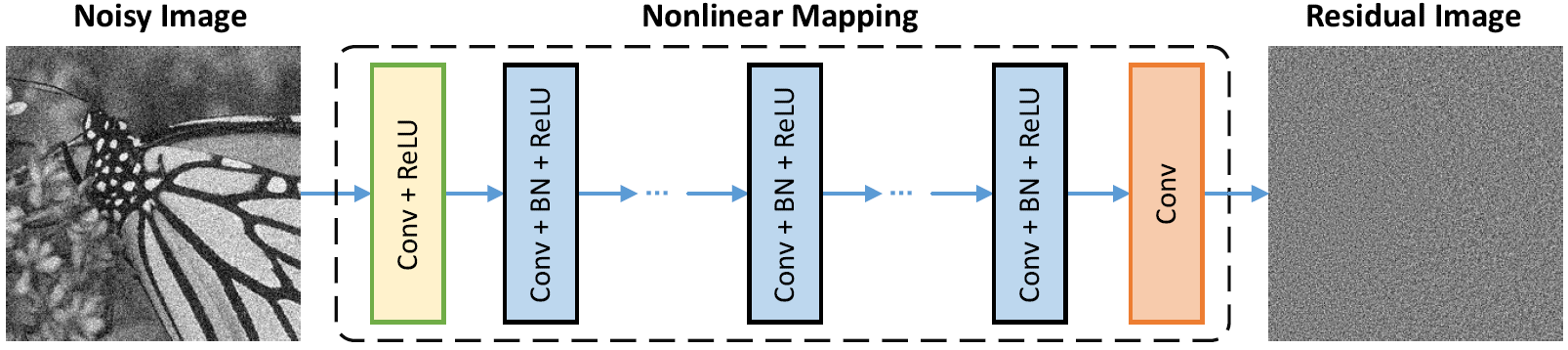
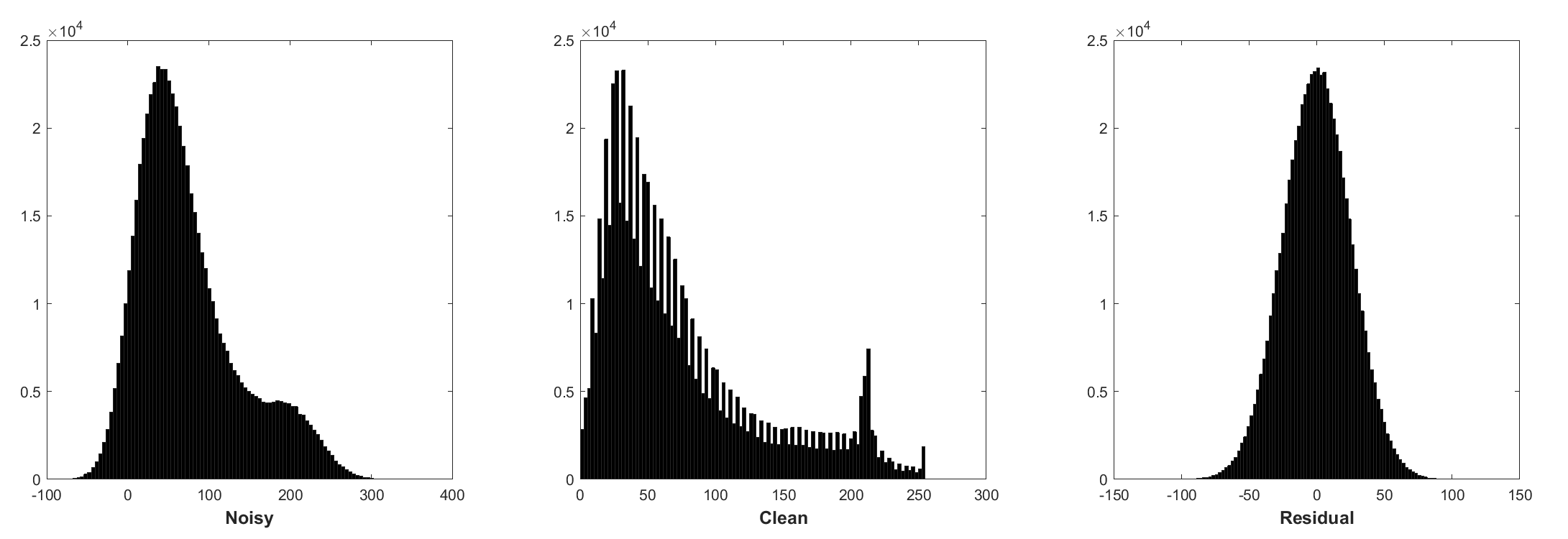
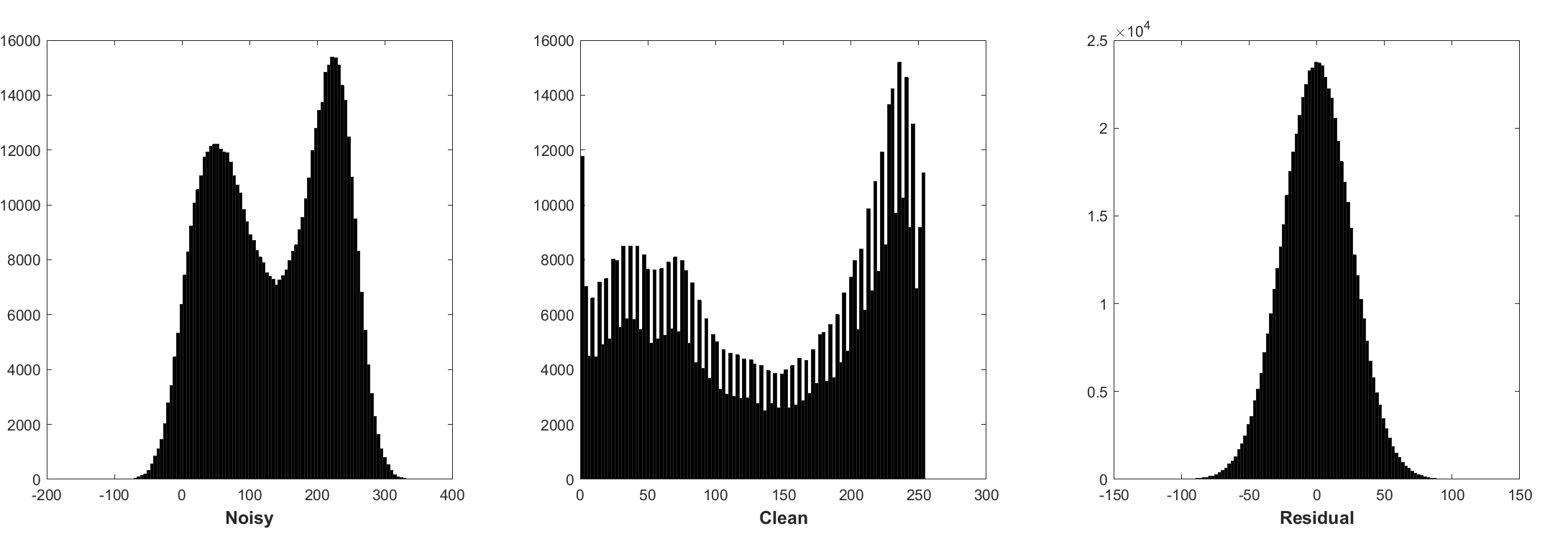
배치 정규화 및 잔류 학습은 가우스 노이즈 (특히 단일 소음 수준의 경우)에 유리합니다. 첨가제 화이트 가우시안 노이즈 (AWGN)에 의해 손상된 시끄러운 이미지의 잔차는 훈련 중에 배치 정규화를 안정시키는 일정한 가우시안 분포를 따릅니다.
잔류 예측은 시작점에서 하나의 구배 하강 추론 단계 (즉, 시끄러운 이미지)를 수행하는 것으로 해석 될 수 있습니다.
DNCNN의 매개 변수는 주로 이미지 우선권 (작업 독립)을 나타내므로 이미지 데노이징, 이미지 수퍼 레스 솔루션 및 JPEG 이미지 디 블로킹과 같은 다른 작업에 대한 단일 모델을 배울 수 있습니다.
왼쪽은 다른 열화로 손상된 입력 이미지이며 오른쪽은 DNCNN-3의 복원 된 이미지입니다.


BSD68 데이터 세트에서 다른 방법의 평균 PSNR (DB) 결과.
| 소음 수준 | BM3D | wnnm | epll | MLP | CSF | tnrd | dncnn | dncnn-b | fdncnn | 드루 넷 |
|---|---|---|---|---|---|---|---|---|---|---|
| 15 | 31.07 | 31.37 | 31.21 | - | 31.24 | 31.42 | 31.73 | 31.61 | 31.69 | 31.91 |
| 25 | 28.57 | 28.83 | 28.68 | 28.96 | 28.74 | 28.92 | 29.23 | 29.16 | 29.22 | 29.48 |
| 50 | 25.62 | 25.87 | 25.67 | 26.03 | - | 25.97 | 26.23 | 26.23 | 26.27 | 26.59 |
시각적 결과
왼쪽은 AWGN에 의해 손상된 시끄러운 이미지이며, 중간은 DNCNN의 거부 된 이미지이며 오른쪽은지면 진실입니다.









BSD68 데이터 세트에서 노이즈 레벨 15, 25 및 50을 사용한 가우시안 비난에 대한 다양한 방법의 평균 PSNR (DB)/SSIM 결과, 고전적인 요인 10, 20, 30 및 Live11 DataSets에서 SET5, SET14, BSD100 및 URBAN100 데이터 세트에서 업 스케일링 계수 2, BSD100 및 URBAN100 데이터 세트의 업 스케일링 계수 2, 3 및 40을 갖는 단일 이미지 수퍼 레스 저해상도.
| 데이터 세트 | 소음 수준 | BM3D | tnrd | DNCNN-3 |
|---|---|---|---|---|
| 15 | 31.08 / 0.8722 | 31.42 / 0.8826 | 31.46 / 0.8826 | |
| BSD68 | 25 | 28.57 / 0.8017 | 28.92 / 0.8157 | 29.02 / 0.8190 |
| 50 | 25.62 / 0.6869 | 25.97 / 0.7029 | 26.10 / 0.7076 |
| 데이터 세트 | 업 스케일링 계수 | tnrd | vdsr | DNCNN-3 |
|---|---|---|---|---|
| 2 | 36.86 / 0.9556 | 37.56 / 0.9591 | 37.58 / 0.9590 | |
| 세트 5 | 3 | 33.18 / 0.9152 | 33.67 / 0.9220 | 33.75 / 0.9222 |
| 4 | 30.85 / 0.8732 | 31.35 / 0.8845 | 31.40 / 0.8845 | |
| 2 | 32.51 / 0.9069 | 33.02 / 0.9128 | 33.03 / 0.9128 | |
| set14 | 3 | 29.43 / 0.8232 | 29.77 / 0.8318 | 29.81 / 0.8321 |
| 4 | 27.66 / 0.7563 | 27.99 / 0.7659 | 28.04 / 0.7672 | |
| 2 | 31.40 / 0.8878 | 31.89 / 0.8961 | 31.90 / 0.8961 | |
| BSD100 | 3 | 28.50 / 0.7881 | 28.82 / 0.7980 | 28.85 / 0.7981 |
| 4 | 27.00 / 0.7140 | 27.28 / 0.7256 | 27.29 / 0.7253 | |
| 2 | 29.70 / 0.8994 | 30.76 / 0.9143 | 30.74 / 0.9139 | |
| Urban100 | 3 | 26.42 / 0.8076 | 27.13 / 0.8283 | 27.15 / 0.8276 |
| 4 | 24.61 / 0.7291 | 25.17 / 0.7528 | 25.20 / 0.7521 |
| 데이터 세트 | 품질 요인 | AR-CNN | tnrd | DNCNN-3 |
|---|---|---|---|---|
| 클래식 5 | 10 | 29.03 / 0.7929 | 29.28 / 0.7992 | 29.40 / 0.8026 |
| 20 | 31.15 / 0.8517 | 31.47 / 0.8576 | 31.63 / 0.8610 | |
| 30 | 32.51 / 0.8806 | 32.78 / 0.8837 | 32.91 / 0.8861 | |
| 40 | 33.34 / 0.8953 | - | 33.77 / 0.9003 | |
| LIVE1 | 10 | 28.96 / 0.8076 | 29.15 / 0.8111 | 29.19 / 0.8123 |
| 20 | 31.29 / 0.8733 | 31.46 / 0.8769 | 31.59 / 0.8802 | |
| 30 | 32.67 / 0.9043 | 32.84 / 0.9059 | 32.98 / 0.9090 | |
| 40 | 33.63 / 0.9198 | - | 33.96 / 0.9247 |
또는 모델을 테스트하기 위해 MATLAB R2015B 만 있습니다.
dncnn/demo_test_dncnn.m
4A4B5B8에서 64 ~ 65 행
@article { zhang2017beyond ,
title = { Beyond a {Gaussian} denoiser: Residual learning of deep {CNN} for image denoising } ,
author = { Zhang, Kai and Zuo, Wangmeng and Chen, Yunjin and Meng, Deyu and Zhang, Lei } ,
journal = { IEEE Transactions on Image Processing } ,
year = { 2017 } ,
volume = { 26 } ,
number = { 7 } ,
pages = { 3142-3155 } ,
}
@article { zhang2020plug ,
title = { Plug-and-Play Image Restoration with Deep Denoiser Prior } ,
author = { Zhang, Kai and Li, Yawei and Zuo, Wangmeng and Zhang, Lei and Van Gool, Luc and Timofte, Radu } ,
journal = { arXiv preprint } ,
year = { 2020 }
}===============================================================================
@Inbook{zuo2018convolutional,
author={Zuo, Wangmeng and Zhang, Kai and Zhang, Lei},
editor={Bertalm{'i}o, Marcelo},
title={Convolutional Neural Networks for Image Denoising and Restoration},
bookTitle={Denoising of Photographic Images and Video: Fundamentals, Open Challenges and New Trends},
year={2018},
publisher={Springer International Publishing},
address={Cham},
pages={93--123},
isbn={978-3-319-96029-6},
doi={10.1007/978-3-319-96029-6_4},
url={https://doi.org/10.1007/978-3-319-96029-6_4}
}
AWGN 제거에 대한 이미지가 거부 된 반면, 실제 이미지 denoising에 대한 작업은 거의 수행되지 않았습니다. 주요 어려움은 실제 소음이 AWGN보다 훨씬 더 복잡하다는 사실에서 비롯되며, 거부자의 성능을 철저히 평가하는 것은 쉬운 일이 아닙니다. 그림 4.15는 실제 세계에서 4 가지 일반적인 노이즈 유형을 보여줍니다. 이러한 소음의 특성은 매우 다르고 단일 노이즈 레벨만으로는 이러한 노이즈 유형을 매개 변수화하기에 충분하지 않을 수 있습니다. 대부분의 경우, 거부자는 특정 노이즈 모델에서만 잘 작동 할 수 있습니다. 예를 들어, AWGN 제거를 위해 훈련 된 비난 모델은 혼합 가우스 및 포아송 소음 제거에 효과적이지 않습니다. CNN 기반 방법이 Eq. (4.3) 및 중요한 데이터 충실도 용어는 분해 과정에 해당합니다. 그럼에도 불구하고, AWGN 제거에 대한 이미지 denoising은 다음과 같은 이유로 인해 가치가 있습니다. 첫째, 다양한 CNN 기반 데노 이징 방법의 효과를 평가하기위한 이상적인 테스트 베드입니다. 둘째, 가변 분할 기술을 통한 무시되지 않은 추론에서, 많은 이미지 복원 문제는 일련의 가우시안 비난 하위 문제를 순차적으로 해결함으로써 해결 될 수 있으며, 이는 응용 분야를 더욱 확대시킨다.

CNN Denoiser의 실용성을 향상시키기 위해, 아마도 가장 간단한 방법은 실제 분해 공간을 덮을 수 있도록 훈련을위한 적절한 양의 실제 시끄러운 청소 훈련 쌍을 포착하는 것입니다. 이 솔루션은 복잡한 분해 과정을 알 필요가 없다는 이점이 있습니다. 그러나 시끄러운 이미지의 해당 깨끗한 이미지를 도출하는 것은 공간 정렬 및 조명 보정과 같은 신중한 사후 처리 단계가 필요하기 때문에 사소한 작업이 아닙니다. 또는 실제 저하 프로세스를 시뮬레이션하여 깨끗한 이미지를 위해 시끄러운 이미지를 합성 할 수 있습니다. 그러나 복잡한 분해 과정을 정확하게 모델링하는 것은 쉽지 않습니다. 특히, 노이즈 모델은 카메라마다 다를 수 있습니다. 그럼에도 불구하고, 훈련을위한 특정 노이즈 유형을 대략적으로 모델링 한 다음, 유형 별 비난을 위해 학습 된 CNN 모델을 사용하는 것이 실제로 바람직합니다.
교육 데이터 외에도 강력한 아키텍처와 강력한 교육은 CNN Denoiser의 성공을위한 중요한 역할을합니다. 강력한 아키텍처의 경우, 거친 다가오는 절차를 포함하는 깊은 멀티 스케일 CNN을 설계하는 것은 유망한 방향입니다. 이러한 네트워크는 멀티 스케일의 장점을 물려받을 것으로 예상됩니다. (i) 소음 수준은 더 큰 규모로 감소합니다. (ii) 유비쿼터스 저주파 소음은 멀티 스케일 절차에 의해 완화 될 수있다. 그리고 (iii) Denoising이 제출 된 수용 제출을 효과적으로 확대 할 수 있기 전에 이미지를 다운 샘플링합니다. 강력한 훈련의 경우 실제 이미지 데노이징을위한 생성 적대성 네트워크 (GAN)로 훈련 된 데노이저의 효과는 여전히 추가 조사로 남아 있습니다. GAN 기반 비난의 주요 아이디어는 비난 된 이미지의 지각 품질을 향상시키기 위해 적대적 손실을 도입하는 것입니다. 게다가, 간의 독특한 장점은 감독되지 않은 학습을 수행 할 수 있다는 것입니다. 보다 구체적으로, 진실이없는 시끄러운 이미지는 훈련에 사용될 수 있습니다. 지금까지 우리는 CNN Denoiser의 실용성을 향상시키기위한 몇 가지 가능한 솔루션을 제공했습니다. 이러한 솔루션을 결합하여 성능을 더욱 향상시킬 수 있습니다.


