DnCNN
1.0.0
الأخبار: ماليت
أحدث أداء تقليله
يمكن استخدامه لاستعادة صورة التوصيل والتشغيل

https://github.com/cszn/dpir/blob/master/main_dpir_denoising.py
I recommend to use the PyTorch code for training and testing. The model parameters of MatConvnet and PyTorch are same.
main_train_dncnn.py
main_test_dncnn.py
main_test_dncnn3_deblocking.py
import torch
import torch . nn as nn
def merge_bn ( model ):
''' merge all 'Conv+BN' (or 'TConv+BN') into 'Conv' (or 'TConv')
based on https://github.com/pytorch/pytorch/pull/901
by Kai Zhang ([email protected])
https://github.com/cszn/DnCNN
01/01/2019
'''
prev_m = None
for k , m in list ( model . named_children ()):
if ( isinstance ( m , nn . BatchNorm2d ) or isinstance ( m , nn . BatchNorm1d )) and ( isinstance ( prev_m , nn . Conv2d ) or isinstance ( prev_m , nn . Linear ) or isinstance ( prev_m , nn . ConvTranspose2d )):
w = prev_m . weight . data
if prev_m . bias is None :
zeros = torch . Tensor ( prev_m . out_channels ). zero_ (). type ( w . type ())
prev_m . bias = nn . Parameter ( zeros )
b = prev_m . bias . data
invstd = m . running_var . clone (). add_ ( m . eps ). pow_ ( - 0.5 )
if isinstance ( prev_m , nn . ConvTranspose2d ):
w . mul_ ( invstd . view ( 1 , w . size ( 1 ), 1 , 1 ). expand_as ( w ))
else :
w . mul_ ( invstd . view ( w . size ( 0 ), 1 , 1 , 1 ). expand_as ( w ))
b . add_ ( - m . running_mean ). mul_ ( invstd )
if m . affine :
if isinstance ( prev_m , nn . ConvTranspose2d ):
w . mul_ ( m . weight . data . view ( 1 , w . size ( 1 ), 1 , 1 ). expand_as ( w ))
else :
w . mul_ ( m . weight . data . view ( w . size ( 0 ), 1 , 1 , 1 ). expand_as ( w ))
b . mul_ ( m . weight . data ). add_ ( m . bias . data )
del model . _modules [ k ]
prev_m = m
merge_bn ( m )
def tidy_sequential ( model ):
for k , m in list ( model . named_children ()):
if isinstance ( m , nn . Sequential ):
if m . __len__ () == 1 :
model . _modules [ k ] = m . __getitem__ ( 0 )
tidy_sequential ( m )نسخة Simplenn
إصدار Dagnn
[DEMOS] Demo_test_DnCNN-.m .
[النماذج] بما في ذلك النماذج المدربة لتوضيح غاوسي ؛ نموذج واحد لـ Gaussian Dechining ، صورة واحدة فائقة الدقة (SISR) و deblocking.
[TestSets] BSD68 و SET10 لتقييم تقليل غاوسي ؛ Set5 و Set14 و BSD100 و Urban100 مجموعات بيانات لتقييم SISR ؛ Classic5 و Live1 لـ JPEG Deflocking Devaluation.
لقد قمت بتدريب نماذج DNCNN (FDNCNN) المرنة الجديدة على أساس FFDNET.
يمكن FDNCNN التعامل مع نطاق مستوى الضوضاء من [0 ، 75] عبر نموذج واحد.
demo_fdncnn_gray.m
demo_fdncnn_gray_clip.m
demo_fdncnn_color.m
demo_fdncnn_color_clip.m
هندسة الشبكة
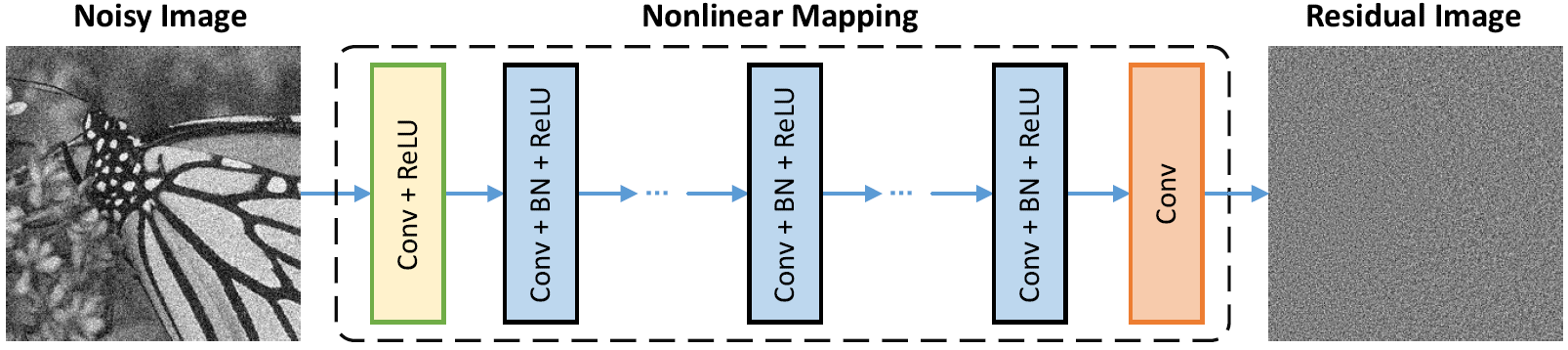
تطبيع الدُفعات والتعلم المتبقي مفيد لتوضيح غاوسي (خاصة بالنسبة لمستوى ضوضاء واحد). يتبع المتبقية من صورة صاخبة تالفة بواسطة الضوضاء الغوسية البيضاء المضافة (AWGN) توزيعًا غاوسيًا مستمرًا يثبت تطبيع الدُفعات أثناء التدريب.
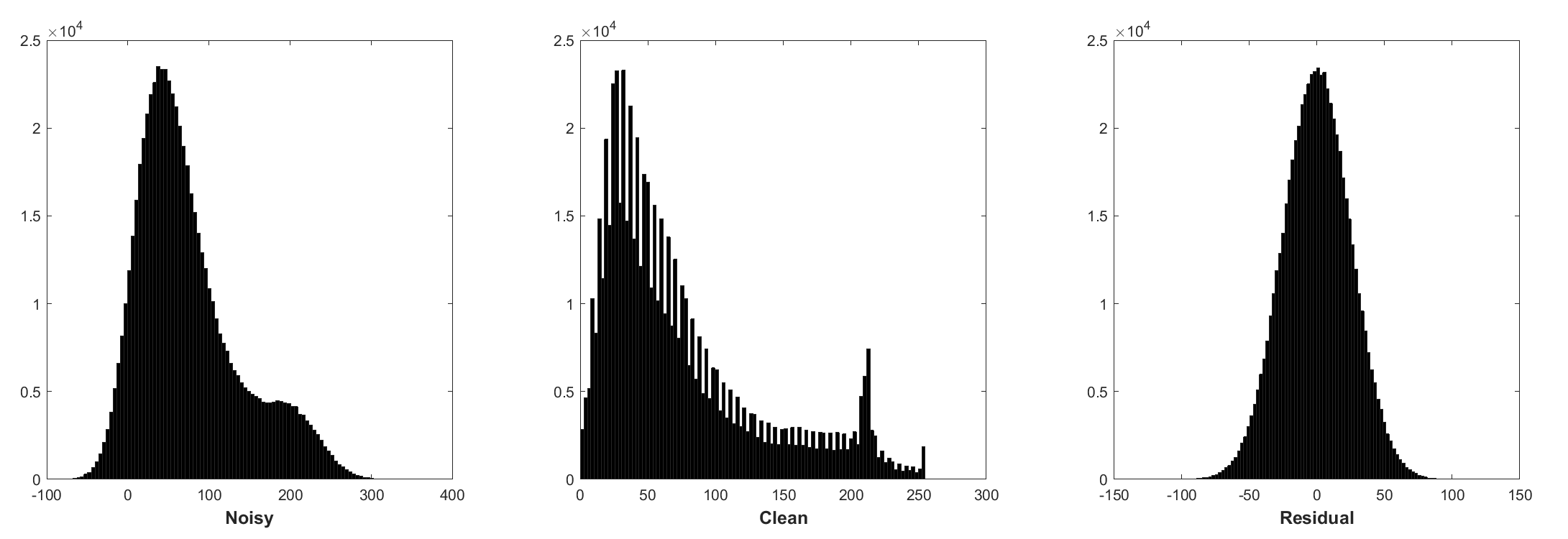
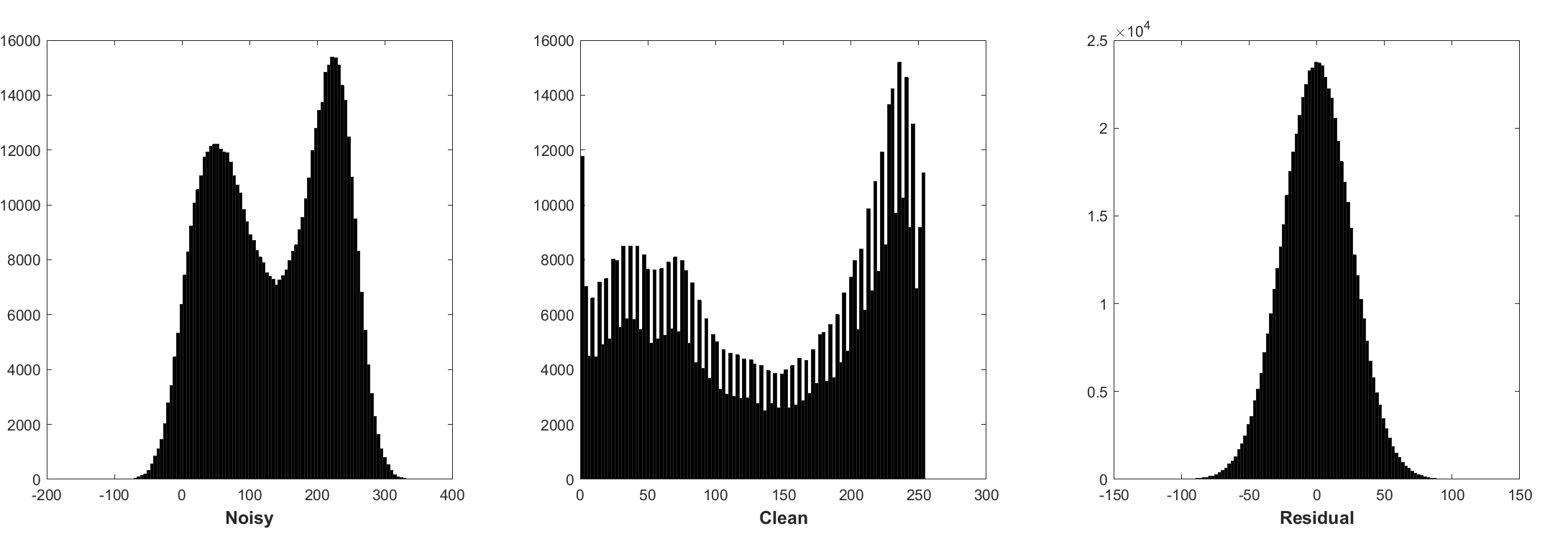
يمكن تفسير التنبؤ بالمتبقية على أنه أداء خطوة استنتاج نزول واحد عند نقطة البداية (أي الصورة الصاخبة).
تمثل المعلمات في DNCNN بشكل أساسي صور الصور (مستقلة عن المهام) ، وبالتالي من الممكن تعلم نموذج واحد للمهام المختلفة ، مثل تقليل الصور ، و deBlocking صورة فائقة الصورة.
اليسار هو صورة الإدخال تالفة من خلال تدهورات مختلفة ، واليمين هو الصورة التي تم ترميمها بواسطة DNCNN-3.


متوسط نتائج PSNR (DB) لطرق مختلفة على مجموعة بيانات BSD68.
| مستوى الضوضاء | BM3D | wnnm | epll | MLP | CSF | tnrd | DNCNN | DNCNN-B | fdncnn | مرادفات |
|---|---|---|---|---|---|---|---|---|---|---|
| 15 | 31.07 | 31.37 | 31.21 | - | 31.24 | 31.42 | 31.73 | 31.61 | 31.69 | 31.91 |
| 25 | 28.57 | 28.83 | 28.68 | 28.96 | 28.74 | 28.92 | 29.23 | 29.16 | 29.22 | 29.48 |
| 50 | 25.62 | 25.87 | 25.67 | 26.03 | - | 25.97 | 26.23 | 26.23 | 26.27 | 26.59 |
النتائج البصرية
اليسار هو الصورة الصاخبة التي تالفة من قبل AWGN ، والوسط هو الصورة denoised بواسطة DNCNN ، واليمين هو الحقيقة الأرضية.









متوسط نتائج PSNR (DB)/SSIM لطرق مختلفة لتخليص Gaussian مع مستوى الضوضاء 15 و 25 و 50 على مجموعة بيانات BSD68 ، صورة واحدة ذات دقة فائقة مع عوامل الارتفاع 2 و 3 و 40 على Set5 و Set14 و BSD100 و Urban100 DataSets ، JPEG Image DeBling 10 و 20 و 40 و 40 و 40 و Live11 Datas.
| مجموعة البيانات | مستوى الضوضاء | BM3D | tnrd | DNCNN-3 |
|---|---|---|---|---|
| 15 | 31.08 / 0.8722 | 31.42 / 0.8826 | 31.46 / 0.8826 | |
| BSD68 | 25 | 28.57 / 0.8017 | 28.92 / 0.8157 | 29.02 / 0.8190 |
| 50 | 25.62 / 0.6869 | 25.97 / 0.7029 | 26.10 / 0.7076 |
| مجموعة البيانات | عامل الارتفاع | tnrd | VDSR | DNCNN-3 |
|---|---|---|---|---|
| 2 | 36.86 / 0.9556 | 37.56 / 0.9591 | 37.58 / 0.9590 | |
| set5 | 3 | 33.18 / 0.9152 | 33.67 / 0.9220 | 33.75 / 0.9222 |
| 4 | 30.85 / 0.8732 | 31.35 / 0.8845 | 31.40 / 0.8845 | |
| 2 | 32.51 / 0.9069 | 33.02 / 0.9128 | 33.03 / 0.9128 | |
| set14 | 3 | 29.43 / 0.8232 | 29.77 / 0.8318 | 29.81 / 0.8321 |
| 4 | 27.66 / 0.7563 | 27.99 / 0.7659 | 28.04 / 0.7672 | |
| 2 | 31.40 / 0.8878 | 31.89 / 0.8961 | 31.90 / 0.8961 | |
| BSD100 | 3 | 28.50 / 0.7881 | 28.82 / 0.7980 | 28.85 / 0.7981 |
| 4 | 27.00 / 0.7140 | 27.28 / 0.7256 | 27.29 / 0.7253 | |
| 2 | 29.70 / 0.8994 | 30.76 / 0.9143 | 30.74 / 0.9139 | |
| Urban100 | 3 | 26.42 / 0.8076 | 27.13 / 0.8283 | 27.15 / 0.8276 |
| 4 | 24.61 / 0.7291 | 25.17 / 0.7528 | 25.20 / 0.7521 |
| مجموعة البيانات | عامل الجودة | AR-CNN | tnrd | DNCNN-3 |
|---|---|---|---|---|
| الكلاسيكية | 10 | 29.03 / 0.7929 | 29.28 / 0.7992 | 29.40 / 0.8026 |
| 20 | 31.15 / 0.8517 | 31.47 / 0.8576 | 31.63 / 0.8610 | |
| 30 | 32.51 / 0.8806 | 32.78 / 0.8837 | 32.91 / 0.8861 | |
| 40 | 33.34 / 0.8953 | - | 33.77 / 0.9003 | |
| Live1 | 10 | 28.96 / 0.8076 | 29.15 / 0.8111 | 29.19 / 0.8123 |
| 20 | 31.29 / 0.8733 | 31.46 / 0.8769 | 31.59 / 0.8802 | |
| 30 | 32.67 / 0.9043 | 32.84 / 0.9059 | 32.98 / 0.9090 | |
| 40 | 33.63 / 0.9198 | - | 33.96 / 0.9247 |
أو فقط MATLAB R2015B لاختبار النموذج.
dncnn/demo_test_dncnn.m
الخطوط 64 إلى 65 في 4A4B5B8
@article { zhang2017beyond ,
title = { Beyond a {Gaussian} denoiser: Residual learning of deep {CNN} for image denoising } ,
author = { Zhang, Kai and Zuo, Wangmeng and Chen, Yunjin and Meng, Deyu and Zhang, Lei } ,
journal = { IEEE Transactions on Image Processing } ,
year = { 2017 } ,
volume = { 26 } ,
number = { 7 } ,
pages = { 3142-3155 } ,
}
@article { zhang2020plug ,
title = { Plug-and-Play Image Restoration with Deep Denoiser Prior } ,
author = { Zhang, Kai and Li, Yawei and Zuo, Wangmeng and Zhang, Lei and Van Gool, Luc and Timofte, Radu } ,
journal = { arXiv preprint } ,
year = { 2020 }
}==================================================================
@Inbook{zuo2018convolutional,
author={Zuo, Wangmeng and Zhang, Kai and Zhang, Lei},
editor={Bertalm{'i}o, Marcelo},
title={Convolutional Neural Networks for Image Denoising and Restoration},
bookTitle={Denoising of Photographic Images and Video: Fundamentals, Open Challenges and New Trends},
year={2018},
publisher={Springer International Publishing},
address={Cham},
pages={93--123},
isbn={978-3-319-96029-6},
doi={10.1007/978-3-319-96029-6_4},
url={https://doi.org/10.1007/978-3-319-96029-6_4}
}
على الرغم من أن الصورة القلبة لإزالة AWGN قد تم دراستها بشكل جيد ، فقد تم القيام بعمل قليل على تقليد الصورة الحقيقية. تنشأ الصعوبة الرئيسية من حقيقة أن الضوضاء الحقيقية أكثر تعقيدًا بكثير من AWGN وليس من السهل تقييم أداء Denoiser تمامًا. يوضح الشكل 4.15 أربعة أنواع ضوضاء نموذجية في العالم الحقيقي. يمكن ملاحظة أن خصائص تلك الضوضاء مختلفة تمامًا وقد لا يكون مستوى الضوضاء الواحد كافياً لتعليم أنواع الضوضاء هذه. في معظم الحالات ، لا يمكن لعناية الجدل أن تعمل بشكل جيد إلا في ظل نموذج ضوضاء معين. على سبيل المثال ، لا يكون نموذج تقليل الاستثمار المدرب على إزالة AWGN فعالًا لإزالة الضوضاء الغاوسية والمختلطة. هذا معقول حدسي لأنه يمكن التعامل مع الأساليب المستندة إلى CNN كحالة عامة للمعادلة. (4.3) ومصطلح دقة البيانات المهم يتوافق مع عملية التحلل. على الرغم من ذلك ، فإن الصورة القوية لإزالة AWGN هي قيمة بسبب الأسباب التالية. أولاً ، إنه سرير اختبار مثالي لتقييم فعالية أساليب القلوة المختلفة القائمة على CNN. ثانياً ، في الاستدلال غير المتواصل عن طريق تقنيات تقسيم المتغير ، يمكن معالجة العديد من مشاكل استعادة الصور عن طريق حل سلسلة من المشكلات الفرعية المتنوعة Gaussian ، مما يزيد من موسع حقول التطبيق.

لتحسين القدرة العملية ل Denoiser CNN ، ربما تكون الطريقة الأكثر وضوحًا هي التقاط كميات كافية من أزواج التدريب النظيف الصاخبة الحقيقية للتدريب بحيث يمكن تغطية مساحة التدهور الحقيقي. هذا الحل له ميزة أنه ليست هناك حاجة لمعرفة عملية التدهور المعقدة. ومع ذلك ، فإن استخلاص الصورة النظيفة المقابلة لصحيفة صاخبة ليست مهمة تافهة بسبب الحاجة إلى خطوات معالجة دقيقة ، مثل المحاذاة المكانية وتصحيح الإضاءة. بدلاً من ذلك ، يمكن للمرء محاكاة عملية التدهور الحقيقي لتوليف الصور الصاخبة لأحدها نظيفة. ومع ذلك ، ليس من السهل تصميم عملية التدهور المعقدة بدقة. على وجه الخصوص ، يمكن أن يكون نموذج الضوضاء مختلفًا عبر كاميرات مختلفة. ومع ذلك ، فمن الأفضل عملياً تصميم نوع ضوضاء معين تقريبًا للتدريب ومن ثم استخدام نموذج CNN المستفاد من أجل تقليل النوع الخاص.
إلى جانب بيانات التدريب ، تلعب الهندسة المعمارية القوية والتدريب القوي أيضًا أدوارًا حيوية لنجاح Denoiser CNN. بالنسبة للهندسة المعمارية القوية ، فإن تصميم CNN متعددة النطاقات العميق الذي يتضمن إجراءً خشنًا إلى الوراء هو اتجاه واعد. من المتوقع أن ترث هذه الشبكة مزايا المتعددة: (1) انخفاض مستوى الضوضاء في المقاييس الأكبر ؛ (2) يمكن تخفيف ضوضاء التردد المنخفض في كل مكان عن طريق الإجراءات متعددة المقاييس ؛ و (iii) يمكن تخفيض الصورة قبل تقليله بشكل فعال أن يوسع التقبل المقبى. للتدريب القوي ، لا تزال فعالية Denoiser المدربة على شبكات الخصومة التوليدية (GAN) من أجل تقليل الصورة الحقيقية مزيد من التحقيق. تتمثل الفكرة الرئيسية في تقليل القائمة على GAN في إدخال خسارة عدوانية لتحسين الجودة الإدراكية للصورة التي يتم تحديدها. علاوة على ذلك ، تتمثل ميزة مميزة لـ GAN في أنه يمكنه التعلم غير الخاضع للإشراف. وبشكل أكثر تحديداً ، يمكن استخدام الصورة الصاخبة بدون الحقيقة الأرضية في التدريب. حتى الآن ، قدمنا العديد من الحلول الممكنة لتحسين القدرة العملية ل Denoiser CNN. يجب أن نلاحظ أنه يمكن دمج هذه الحلول لزيادة تحسين الأداء.


