DnCNN
1.0.0
Nachrichten: Trunet
Hochmoderne Denoising-Leistung
Kann zur Wiederherstellung von Plug-and-Play-Bild verwendet werden

https://github.com/cszn/dpire/blob/master/main_dpir_denoising.py
I recommend to use the PyTorch code for training and testing. The model parameters of MatConvnet and PyTorch are same.
main_train_dncnn.py
main_test_dncnn.py
main_test_dncnn3_deblocking.py
import torch
import torch . nn as nn
def merge_bn ( model ):
''' merge all 'Conv+BN' (or 'TConv+BN') into 'Conv' (or 'TConv')
based on https://github.com/pytorch/pytorch/pull/901
by Kai Zhang ([email protected])
https://github.com/cszn/DnCNN
01/01/2019
'''
prev_m = None
for k , m in list ( model . named_children ()):
if ( isinstance ( m , nn . BatchNorm2d ) or isinstance ( m , nn . BatchNorm1d )) and ( isinstance ( prev_m , nn . Conv2d ) or isinstance ( prev_m , nn . Linear ) or isinstance ( prev_m , nn . ConvTranspose2d )):
w = prev_m . weight . data
if prev_m . bias is None :
zeros = torch . Tensor ( prev_m . out_channels ). zero_ (). type ( w . type ())
prev_m . bias = nn . Parameter ( zeros )
b = prev_m . bias . data
invstd = m . running_var . clone (). add_ ( m . eps ). pow_ ( - 0.5 )
if isinstance ( prev_m , nn . ConvTranspose2d ):
w . mul_ ( invstd . view ( 1 , w . size ( 1 ), 1 , 1 ). expand_as ( w ))
else :
w . mul_ ( invstd . view ( w . size ( 0 ), 1 , 1 , 1 ). expand_as ( w ))
b . add_ ( - m . running_mean ). mul_ ( invstd )
if m . affine :
if isinstance ( prev_m , nn . ConvTranspose2d ):
w . mul_ ( m . weight . data . view ( 1 , w . size ( 1 ), 1 , 1 ). expand_as ( w ))
else :
w . mul_ ( m . weight . data . view ( w . size ( 0 ), 1 , 1 , 1 ). expand_as ( w ))
b . mul_ ( m . weight . data ). add_ ( m . bias . data )
del model . _modules [ k ]
prev_m = m
merge_bn ( m )
def tidy_sequential ( model ):
for k , m in list ( model . named_children ()):
if isinstance ( m , nn . Sequential ):
if m . __len__ () == 1 :
model . _modules [ k ] = m . __getitem__ ( 0 )
tidy_sequential ( m )Simpleenn -Version
Dagnn Version
[Demos] Demo_test_DnCNN-.m .
[Models] einschließlich der ausgebildeten Modelle für Gaußsche Denoising; Ein einzelnes Modell für Gaußsche Denoising, Einzelbild-Superauflösung (SISR) und Entblocking.
[Testsets] BSD68 und SET10 für Gaußsche Denoising -Bewertung; SET5-, SET14-, BSD100- und Urban100 -Datensätze für die SISR -Bewertung; Classic5 und Live1 für JPEG Image DeBlocking Evaluation.
Ich habe neue flexible DNCNN (FDNCNN) -Modelle basierend auf FFDNET trainiert.
FDNCNN kann über ein einzelnes Modell den Rauschpegelbereich von [0, 75] verarbeiten.
Demo_Fdncnn_gray.m
Demo_FDNCNN_GRAY_CLIP.M
Demo_Fdncnn_color.m
Demo_FDNCNN_COLOR_CLIP.M
Netzwerkarchitektur
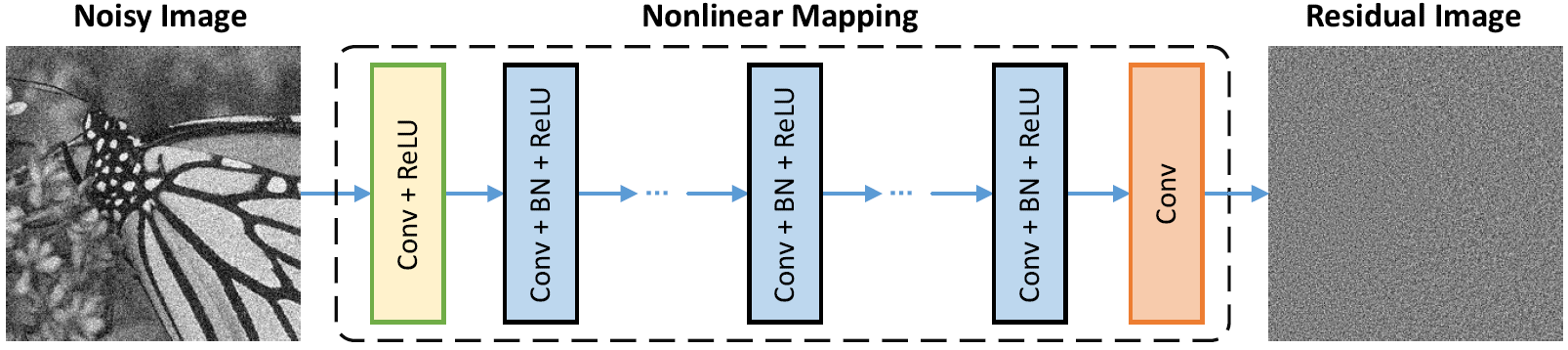
Die Normalisierung der Charge und das restliche Lernen sind für die Gaußsche Denoising von Vorteil (insbesondere für einen einzigen Geräuschpegel). Das Rest eines lauten Bildes, das durch additive weiße Gaußsche Rauschen (AWGN) beschädigt wird, folgt einer konstanten Gaußschen Verteilung, die die Stapel -Normalisierung während des Trainings stabilisiert.
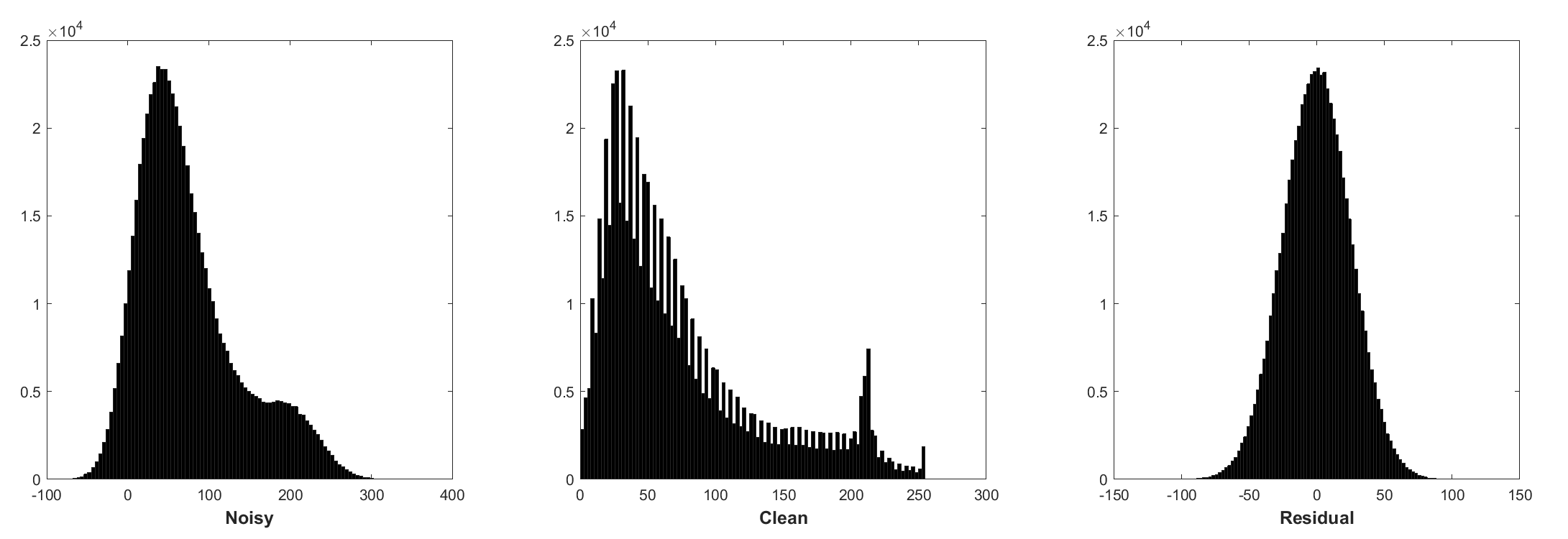
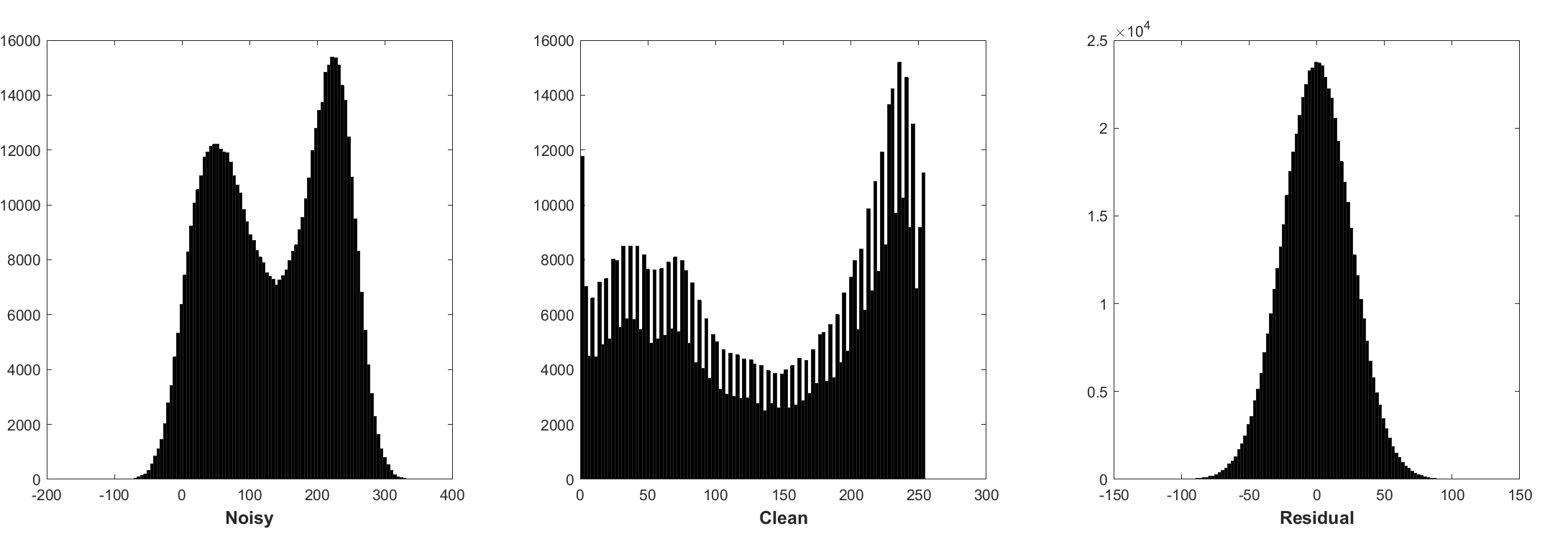
Das Vorhersagen des Restes kann als Durchführung eines Inferenzschritts des Gradientenabstiegs am Startpunkt (dh, lautes Bild) interpretiert werden.
Die Parameter in DNCNN repräsentieren hauptsächlich die Bildpriors (aufgabenunabhängig). Daher ist es möglich, ein einzelnes Modell für verschiedene Aufgaben zu lernen, wie z. B. Bild-Denoising, Bild-Superauflösungen und JPEG-Bildentblocking.
Die linke ist das Eingangsbild, das durch unterschiedliche Verschlechterungen beschädigt wird. Das rechte ist das restaurierte Bild von DNCNN-3.


Die durchschnittlichen PSNR (DB) -Ergebnisse verschiedener Methoden im BSD68 -Datensatz.
| Geräuschpegel | BM3D | Wnnm | EPLL | MLP | CSF | Tnrd | Dncnn | DNCNN-B | Fdncnn | Tunking |
|---|---|---|---|---|---|---|---|---|---|---|
| 15 | 31.07 | 31.37 | 31.21 | - - | 31.24 | 31.42 | 31.73 | 31.61 | 31.69 | 31.91 |
| 25 | 28.57 | 28.83 | 28.68 | 28.96 | 28.74 | 28.92 | 29.23 | 29.16 | 29.22 | 29.48 |
| 50 | 25.62 | 25.87 | 25.67 | 26.03 | - - | 25.97 | 26.23 | 26.23 | 26.27 | 26.59 |
Visuelle Ergebnisse
Die linke ist das laute Bild, das AWGN verderbt, die Mitte ist das beengte Bild von DNCNN, das rechte ist die Bodenwahrheit.









Durchschnittliche PSNR (DB)/SSIM-Ergebnisse verschiedener Methoden zur Gaußschen Denoising mit Rauschpegel 15, 25 und 50 auf BSD68-Datensatz, Einzelbild-Superauflösung mit Upscaling-Faktoren 2, 3 und 40 auf Set5, Set14, BSD100 und Urban100-Datensätzen, JPEG-Bild-DeBlocking mit Qualitätsfaktoren 10, 20 und 40, 30 und 40, und 40 und 40, und 40 und 40, und 40 und 40, und 40 und 40, und 40 und 40, und 40 und 40, und 40 und 40, und 40 und 40, und 40 und 40 und 40 und 40 und 40 und 40 und 40 und 40 und 40 und 40 und 40 und 40 und 40 und 40 und 40 und 40 und 40 und 40 und 40 und 40, 20 und 40, und 40, und 40, und 40.
| Datensatz | Geräuschpegel | BM3D | Tnrd | DNCNN-3 |
|---|---|---|---|---|
| 15 | 31.08 / 0,8722 | 31.42 / 0,8826 | 31.46 / 0,8826 | |
| BSD68 | 25 | 28.57 / 0,8017 | 28.92 / 0,8157 | 29,02 / 0,8190 |
| 50 | 25.62 / 0,6869 | 25.97 / 0,7029 | 26.10 / 0,7076 |
| Datensatz | Hochskalierungsfaktor | Tnrd | Vdsr | DNCNN-3 |
|---|---|---|---|---|
| 2 | 36,86 / 0,9556 | 37,56 / 0,9591 | 37,58 / 0,9590 | |
| Set5 | 3 | 33,18 / 0,9152 | 33,67 / 0,9220 | 33,75 / 0,9222 |
| 4 | 30.85 / 0,8732 | 31.35 / 0,8845 | 31.40 / 0,8845 | |
| 2 | 32,51 / 0,9069 | 33,02 / 0,9128 | 33,03 / 0,9128 | |
| Set14 | 3 | 29,43 / 0,8232 | 29,77 / 0,8318 | 29,81 / 0,8321 |
| 4 | 27.66 / 0,7563 | 27.99 / 0,7659 | 28.04 / 0,7672 | |
| 2 | 31.40 / 0,8878 | 31.89 / 0,8961 | 31.90 / 0,8961 | |
| BSD100 | 3 | 28.50 / 0,7881 | 28.82 / 0,7980 | 28.85 / 0,7981 |
| 4 | 27.00 / 0.7140 | 27.28 / 0,7256 | 27.29 / 0,7253 | |
| 2 | 29,70 / 0,8994 | 30.76 / 0,9143 | 30.74 / 0,9139 | |
| Urban100 | 3 | 26.42 / 0,8076 | 27.13 / 0,8283 | 27.15 / 0,8276 |
| 4 | 24.61 / 0,7291 | 25.17 / 0,7528 | 25.20 / 0,7521 |
| Datensatz | Qualitätsfaktor | AR-CNN | Tnrd | DNCNN-3 |
|---|---|---|---|---|
| Classic5 | 10 | 29.03 / 0,7929 | 29,28 / 0,7992 | 29,40 / 0,8026 |
| 20 | 31.15 / 0,8517 | 31.47 / 0,8576 | 31.63 / 0,8610 | |
| 30 | 32,51 / 0,8806 | 32,78 / 0,8837 | 32,91 / 0,8861 | |
| 40 | 33,34 / 0,8953 | - - | 33.77 / 0.9003 | |
| Live1 | 10 | 28.96 / 0,8076 | 29.15 / 0,8111 | 29,19 / 0,8123 |
| 20 | 31.29 / 0,8733 | 31.46 / 0,8769 | 31.59 / 0,8802 | |
| 30 | 32,67 / 0,9043 | 32,84 / 0,9059 | 32,98 / 0,9090 | |
| 40 | 33,63 / 0,9198 | - - | 33,96 / 0,9247 |
Oder einfach Matlab R2015B, um das Modell zu testen.
Dncnn/Demo_test_dncnn.m
Zeilen 64 bis 65 in 4a4b5b8
@article { zhang2017beyond ,
title = { Beyond a {Gaussian} denoiser: Residual learning of deep {CNN} for image denoising } ,
author = { Zhang, Kai and Zuo, Wangmeng and Chen, Yunjin and Meng, Deyu and Zhang, Lei } ,
journal = { IEEE Transactions on Image Processing } ,
year = { 2017 } ,
volume = { 26 } ,
number = { 7 } ,
pages = { 3142-3155 } ,
}
@article { zhang2020plug ,
title = { Plug-and-Play Image Restoration with Deep Denoiser Prior } ,
author = { Zhang, Kai and Li, Yawei and Zuo, Wangmeng and Zhang, Lei and Van Gool, Luc and Timofte, Radu } ,
journal = { arXiv preprint } ,
year = { 2020 }
}=========================================================================
@Inbook{zuo2018convolutional,
author={Zuo, Wangmeng and Zhang, Kai and Zhang, Lei},
editor={Bertalm{'i}o, Marcelo},
title={Convolutional Neural Networks for Image Denoising and Restoration},
bookTitle={Denoising of Photographic Images and Video: Fundamentals, Open Challenges and New Trends},
year={2018},
publisher={Springer International Publishing},
address={Cham},
pages={93--123},
isbn={978-3-319-96029-6},
doi={10.1007/978-3-319-96029-6_4},
url={https://doi.org/10.1007/978-3-319-96029-6_4}
}
Während das Bild-Denoising für die AWGN-Entfernung gut untersucht wurde, wurden nur wenig Arbeiten bei der echten Image-Denoising geleistet. Die Hauptschwierigkeit ergibt sich aus der Tatsache, dass reale Geräusche viel komplexer sind als AWGN, und es ist keine leichte Aufgabe, die Leistung eines Denoisers gründlich zu bewerten. Abb. 4.15 zeigt vier typische Geräuschtypen in der realen Welt. Es ist ersichtlich, dass die Eigenschaften dieser Geräusche sehr unterschiedlich sind und ein einzelner Geräuschpegel möglicherweise nicht ausreicht, um diese Rauscharten zu parametrisieren. In den meisten Fällen kann ein Denoiser nur unter einem bestimmten Rauschmodell gut arbeiten. Zum Beispiel ist ein für die Entfernung von AWGN ausgebildetes Denoising -Modell für die Entfernung von Mischgaus- und Poisson -Rauschen nicht wirksam. Dies ist intuitiv vernünftig, da die CNN-basierten Methoden als allgemeiner Fall von Gl. (4.3) und der wichtige Daten -Treue -Term entspricht dem Abbauprozess. Trotzdem ist das Bild, das die AWGN -Entfernung beengte, aus folgenden Gründen wertvoll. Erstens ist es ein ideales Testbett, um die Wirksamkeit verschiedener CNN-basierter Denoising-Methoden zu bewerten. Zweitens können in der ungehörten Inferenz über variable Spaltungstechniken viele Probleme mit der Bildrestaurierung angegangen werden, indem eine Reihe von Gaußschen beenoisierenden Unterproblemen nacheinander gelöst werden, die die Anwendungsfelder weiter erweitern.

Um die Praktikabilität eines CNN-Denoisers zu verbessern, besteht der vielleicht unkomplizierteste Weg darin, angemessene Mengen an realer, lauter Trainingspaare für das Training zu erfassen, damit der reale Verschlechterungsraum abgedeckt werden kann. Diese Lösung hat einen Vorteil, dass der komplexe Verschlechterungsprozess nicht bekannt ist. Das entsprechende saubere Bild einer lauten Ableitung ist jedoch keine triviale Aufgabe, da sorgfältige Nachbearbeitungsschritte wie räumliche Ausrichtung und Beleuchtungskorrektur erforderlich sind. Alternativ kann man den tatsächlichen Abbauprozess simulieren, um laute Bilder für eine saubere zu synthetisieren. Es ist jedoch nicht einfach, den komplexen Abbauprozess genau zu modellieren. Insbesondere kann das Rauschmodell über verschiedene Kameras unterschiedlich sein. Trotzdem ist es praktisch vorzuziehen, einen bestimmten Rauschart für das Training grob zu modellieren und dann das gelernte CNN-Modell für die typenspezifische Beenoisierung zu verwenden.
Neben den Trainingsdaten spielen die robuste Architektur und das robuste Training auch eine wichtige Rolle für den Erfolg eines CNN -Denoiser. Für die robuste Architektur ist das Entwerfen eines tiefen Multiscale-CNN, bei dem ein grobes bis zum Finanzverfahren beinhaltet, eine vielversprechende Richtung. Es wird erwartet, dass ein solches Netzwerk die Verdienste von Multiscale erbt: (i) der Geräuschpegel nimmt bei größeren Skalen ab; (ii) das allgegenwärtige Niederfrequenzgeräusch kann durch ein Multiskale-Verfahren gelindert werden; und (iii) das Bild vor dem Denoising down Sampling kann die eingereichte Empfangsdauer effektiv vergrößern. Für das robuste Training bleibt die Effektivität des mit generativen kontroversen Netzwerken (GaN) für echten Image -Beerdigungen ausgebildeten Denoiser weiterhin weitere Untersuchungen. Die Hauptidee der GaN-basierten Denoising besteht darin, einen kontroversen Verlust zur Verbesserung der Wahrnehmungsqualität des beengten Bildes einzuführen. Außerdem besteht ein unverwechselbarer Vorteil von Gan darin, dass es unbeaufsichtigtes Lernen sein kann. Insbesondere kann das laute Bild ohne Grundwahrheit im Training verwendet werden. Bisher haben wir mehrere mögliche Lösungen zur Verbesserung der Praktikabilität eines CNN -Denoisers bereitgestellt. Wir sollten beachten, dass diese Lösungen kombiniert werden können, um die Leistung weiter zu verbessern.


