DnCNN
1.0.0
ニュース: Drunet
最先端の除去パフォーマンス
プラグアンドプレイ画像の復元に使用できます

https://github.com/cszn/dpir/blob/master/main_dpir_denoising.py
I recommend to use the PyTorch code for training and testing. The model parameters of MatConvnet and PyTorch are same.
main_train_dncnn.py
main_test_dncnn.py
main_test_dncnn3_deblocking.py
import torch
import torch . nn as nn
def merge_bn ( model ):
''' merge all 'Conv+BN' (or 'TConv+BN') into 'Conv' (or 'TConv')
based on https://github.com/pytorch/pytorch/pull/901
by Kai Zhang ([email protected])
https://github.com/cszn/DnCNN
01/01/2019
'''
prev_m = None
for k , m in list ( model . named_children ()):
if ( isinstance ( m , nn . BatchNorm2d ) or isinstance ( m , nn . BatchNorm1d )) and ( isinstance ( prev_m , nn . Conv2d ) or isinstance ( prev_m , nn . Linear ) or isinstance ( prev_m , nn . ConvTranspose2d )):
w = prev_m . weight . data
if prev_m . bias is None :
zeros = torch . Tensor ( prev_m . out_channels ). zero_ (). type ( w . type ())
prev_m . bias = nn . Parameter ( zeros )
b = prev_m . bias . data
invstd = m . running_var . clone (). add_ ( m . eps ). pow_ ( - 0.5 )
if isinstance ( prev_m , nn . ConvTranspose2d ):
w . mul_ ( invstd . view ( 1 , w . size ( 1 ), 1 , 1 ). expand_as ( w ))
else :
w . mul_ ( invstd . view ( w . size ( 0 ), 1 , 1 , 1 ). expand_as ( w ))
b . add_ ( - m . running_mean ). mul_ ( invstd )
if m . affine :
if isinstance ( prev_m , nn . ConvTranspose2d ):
w . mul_ ( m . weight . data . view ( 1 , w . size ( 1 ), 1 , 1 ). expand_as ( w ))
else :
w . mul_ ( m . weight . data . view ( w . size ( 0 ), 1 , 1 , 1 ). expand_as ( w ))
b . mul_ ( m . weight . data ). add_ ( m . bias . data )
del model . _modules [ k ]
prev_m = m
merge_bn ( m )
def tidy_sequential ( model ):
for k , m in list ( model . named_children ()):
if isinstance ( m , nn . Sequential ):
if m . __len__ () == 1 :
model . _modules [ k ] = m . __getitem__ ( 0 )
tidy_sequential ( m )Simplennバージョン
Dagnnバージョン
[demos] Demo_test_DnCNN-.m 。
[モデル]ガウス除去の訓練されたモデルを含む。ガウス脱類、単一の画像スーパー解像度(SISR)、およびデブロックの単一モデル。
[テストセット]ガウス除去評価のBSD68およびSET10。 SISR評価のためのSET5、SET14、BSD100およびURBAN100データセット。 JPEG画像デブロック評価のClassic5およびLive1。
FFDNETに基づいて、新しい柔軟なDNCNN(FDNCNN)モデルをトレーニングしました。
FDNCNNは、単一のモデルを介して[0、75]のノイズレベルの範囲を処理できます。
demo_fdncnn_gray.m
demo_fdncnn_gray_clip.m
demo_fdncnn_color.m
demo_fdncnn_color_clip.m
ネットワークアーキテクチャ
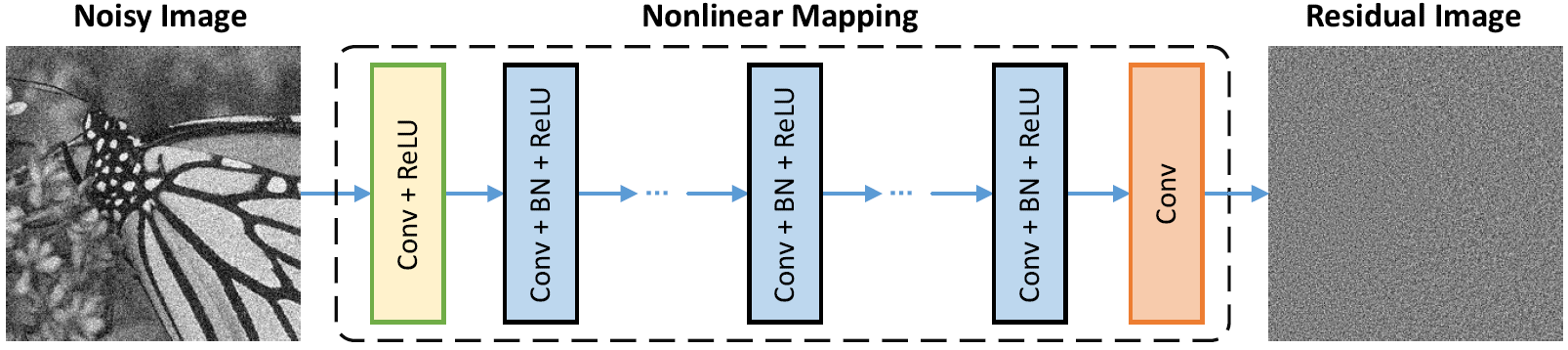
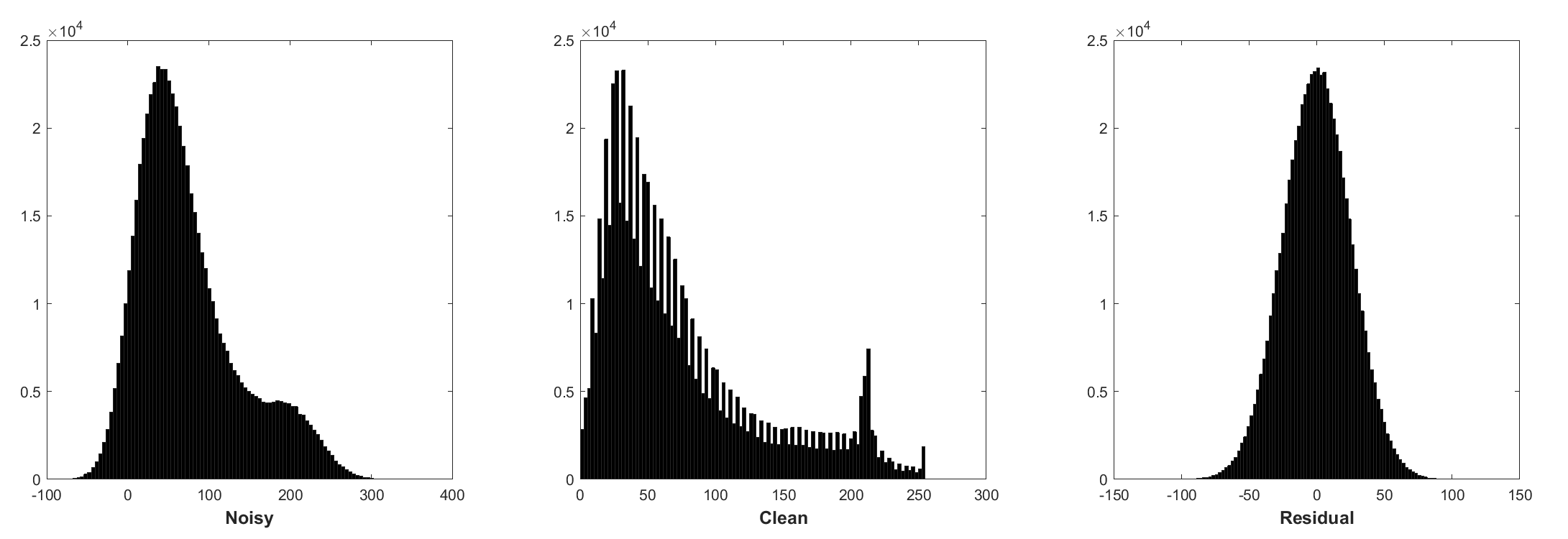
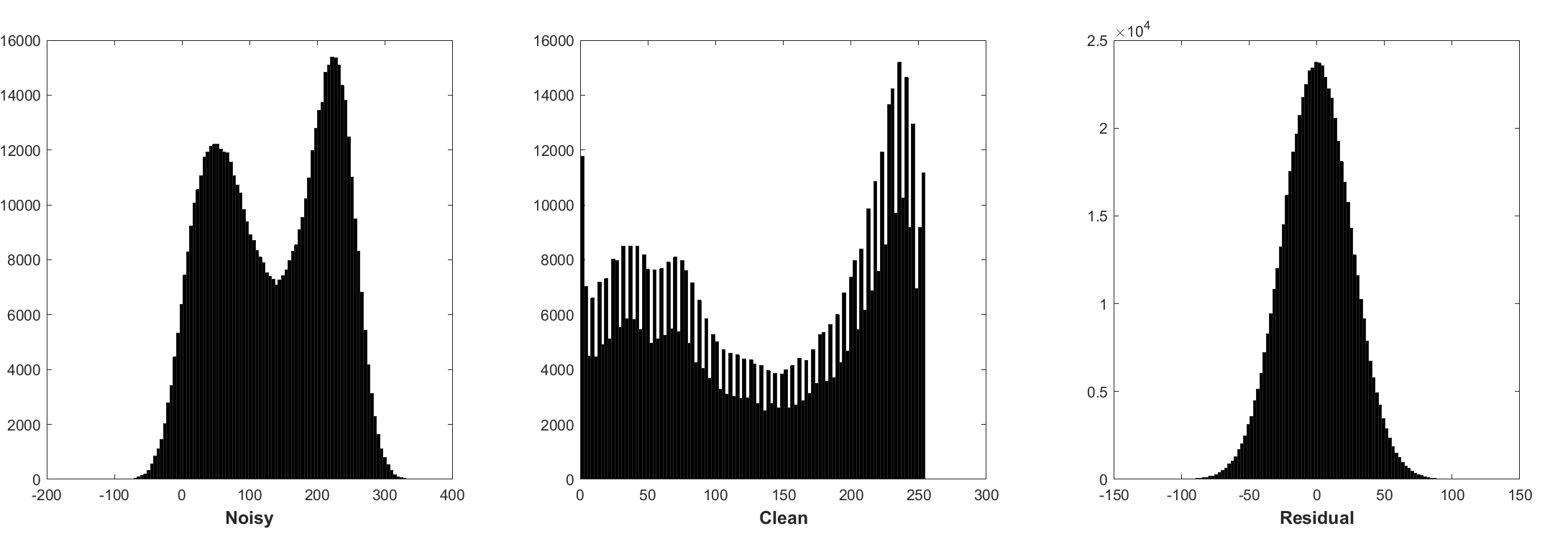
バッチの正規化と残留学習は、ガウスの除去に有益です(特に単一のノイズレベルで)。添加剤のホワイトガウスノイズ(AWGN)によって破損した騒々しい画像の残差は、トレーニング中のバッチ正規化を安定させる一定のガウス分布に従います。
残差を予測することは、開始点で1つの勾配降下推論ステップを実行すると解釈できます(つまり、ノイズの多い画像)。
DNCNNのパラメーターは、主に画像プライアー(タスクに依存しない)を表しているため、画像除去、画像スーパー解像度、JPEG画像デブロックなど、さまざまなタスクの単一モデルを学習することができます。
左は、異なる劣化によって破損した入力画像であり、右はDNCNN-3によって復元された画像です。


BSD68データセットのさまざまな方法の平均PSNR(DB)結果。
| ノイズレベル | BM3D | wnnm | epll | MLP | CSF | tnrd | dncnn | dncnn-b | fdncnn | drunet |
|---|---|---|---|---|---|---|---|---|---|---|
| 15 | 31.07 | 31.37 | 31.21 | - | 31.24 | 31.42 | 31.73 | 31.61 | 31.69 | 31.91 |
| 25 | 28.57 | 28.83 | 28.68 | 28.96 | 28.74 | 28.92 | 29.23 | 29.16 | 29.22 | 29.48 |
| 50 | 25.62 | 25.87 | 25.67 | 26.03 | - | 25.97 | 26.23 | 26.23 | 26.27 | 26.59 |
視覚的な結果
左はAWGNによって破損した騒々しい画像で、真ん中はDNCNNによって除去された画像で、右側は地面が真実です。









BSD68データセットでのノイズレベル15、25、50でのガウス除去のためのさまざまな方法の平均PSNR(DB)/SSIM結果、SET5、SET14、BSD100およびURBAN100データセットで2、3、40の単一画像スーパー解像度2、3、および40、およびJPEGイメージ10、30、および40 on Classic 5および40 on Classic Factureを使用してJPEGイメージ。
| データセット | ノイズレベル | BM3D | tnrd | DNCNN-3 |
|---|---|---|---|---|
| 15 | 31.08 / 0.8722 | 31.42 / 0.8826 | 31.46 / 0.8826 | |
| BSD68 | 25 | 28.57 / 0.8017 | 28.92 / 0.8157 | 29.02 / 0.8190 |
| 50 | 25.62 / 0.6869 | 25.97 / 0.7029 | 26.10 / 0.7076 |
| データセット | アップスケーリング係数 | tnrd | VDSR | DNCNN-3 |
|---|---|---|---|---|
| 2 | 36.86 / 0.9556 | 37.56 / 0.9591 | 37.58 / 0.9590 | |
| set5 | 3 | 33.18 / 0.9152 | 33.67 / 0.9220 | 33.75 / 0.9222 |
| 4 | 30.85 / 0.8732 | 31.35 / 0.8845 | 31.40 / 0.8845 | |
| 2 | 32.51 / 0.9069 | 33.02 / 0.9128 | 33.03 / 0.9128 | |
| Set14 | 3 | 29.43 / 0.8232 | 29.77 / 0.8318 | 29.81 / 0.8321 |
| 4 | 27.66 / 0.7563 | 27.99 / 0.7659 | 28.04 / 0.7672 | |
| 2 | 31.40 / 0.8878 | 31.89 / 0.8961 | 31.90 / 0.8961 | |
| BSD100 | 3 | 28.50 / 0.7881 | 28.82 / 0.7980 | 28.85 / 0.7981 |
| 4 | 27.00 / 0.7140 | 27.28 / 0.7256 | 27.29 / 0.7253 | |
| 2 | 29.70 / 0.8994 | 30.76 / 0.9143 | 30.74 / 0.9139 | |
| urban100 | 3 | 26.42 / 0.8076 | 27.13 / 0.8283 | 27.15 / 0.8276 |
| 4 | 24.61 / 0.7291 | 25.17 / 0.7528 | 25.20 / 0.7521 |
| データセット | 品質要因 | ar-cnn | tnrd | DNCNN-3 |
|---|---|---|---|---|
| Classic5 | 10 | 29.03 / 0.7929 | 29.28 / 0.7992 | 29.40 / 0.8026 |
| 20 | 31.15 / 0.8517 | 31.47 / 0.8576 | 31.63 / 0.8610 | |
| 30 | 32.51 / 0.8806 | 32.78 / 0.8837 | 32.91 / 0.8861 | |
| 40 | 33.34 / 0.8953 | - | 33.77 / 0.9003 | |
| Live1 | 10 | 28.96 / 0.8076 | 29.15 / 0.8111 | 29.19 / 0.8123 |
| 20 | 31.29 / 0.8733 | 31.46 / 0.8769 | 31.59 / 0.8802 | |
| 30 | 32.67 / 0.9043 | 32.84 / 0.9059 | 32.98 / 0.9090 | |
| 40 | 33.63 / 0.9198 | - | 33.96 / 0.9247 |
または、MATLAB R2015Bだけでモデルをテストします。
dncnn/demo_test_dncnn.m
4A4B5B8の64〜65行
@article { zhang2017beyond ,
title = { Beyond a {Gaussian} denoiser: Residual learning of deep {CNN} for image denoising } ,
author = { Zhang, Kai and Zuo, Wangmeng and Chen, Yunjin and Meng, Deyu and Zhang, Lei } ,
journal = { IEEE Transactions on Image Processing } ,
year = { 2017 } ,
volume = { 26 } ,
number = { 7 } ,
pages = { 3142-3155 } ,
}
@article { zhang2020plug ,
title = { Plug-and-Play Image Restoration with Deep Denoiser Prior } ,
author = { Zhang, Kai and Li, Yawei and Zuo, Wangmeng and Zhang, Lei and Van Gool, Luc and Timofte, Radu } ,
journal = { arXiv preprint } ,
year = { 2020 }
}===========================================================================
@Inbook{zuo2018convolutional,
author={Zuo, Wangmeng and Zhang, Kai and Zhang, Lei},
editor={Bertalm{'i}o, Marcelo},
title={Convolutional Neural Networks for Image Denoising and Restoration},
bookTitle={Denoising of Photographic Images and Video: Fundamentals, Open Challenges and New Trends},
year={2018},
publisher={Springer International Publishing},
address={Cham},
pages={93--123},
isbn={978-3-319-96029-6},
doi={10.1007/978-3-319-96029-6_4},
url={https://doi.org/10.1007/978-3-319-96029-6_4}
}
AWGN除去のための除去画像はよく研究されていますが、実際の画像除去に関する作業はほとんど行われていません。主な困難は、実際のノイズがAWGNよりもはるかに複雑であり、悪魔のパフォーマンスを徹底的に評価するのは簡単な作業ではないという事実から生じます。図4.15は、現実世界の4つの典型的なノイズタイプを示しています。これらのノイズの特性は非常に異なり、単一のノイズレベルでは、これらのノイズタイプをパラメーター化するのに十分ではないかもしれないことがわかります。ほとんどの場合、除去者は特定のノイズモデルの下でのみうまく機能します。たとえば、AWGN除去のために訓練された除去モデルは、混合ガウスノイズ除去とポアソンノイズの混合には効果的ではありません。 CNNベースの方法は、式の一般的なケースとして扱うことができるため、これは直感的に合理的です。 (4.3)および重要なデータ忠実度の用語は、分解プロセスに対応しています。これにもかかわらず、AWGN除去のための除去画像は、次の理由により価値があります。まず、さまざまなCNNベースの除去方法の有効性を評価するための理想的なテストベッドです。第二に、可変分割手法を介した展開された推論では、多くの画像修復の問題に対処することができます。

CNN除去者の実用性を向上させるために、おそらく最も簡単な方法は、実際の劣化スペースをカバーできるように、トレーニングのための適切な量の真のノイズの多いトレーニングペアをキャプチャすることです。このソリューションには、複雑な分解プロセスを知る必要がないという利点があります。ただし、騒々しいイメージの対応するクリーンなイメージを導き出すことは、空間アライメントや照明補正など、慎重な後処理ステップが必要なため、些細なタスクではありません。または、実際の劣化プロセスをシミュレートして、きれいな画像の騒々しい画像を合成することができます。ただし、複雑な劣化プロセスを正確にモデル化することは容易ではありません。特に、ノイズモデルは異なるカメラで異なる場合があります。それにもかかわらず、トレーニングのために特定のノイズタイプを大まかにモデル化し、型固有の除去のために学習したCNNモデルを使用することが実際に望ましいです。
トレーニングデータに加えて、堅牢なアーキテクチャと堅牢なトレーニングは、CNN脱類の成功のために重要な役割を果たしています。堅牢なアーキテクチャの場合、粗から洗練された手順を伴う深いマルチスケールCNNを設計することは、有望な方向です。このようなネットワークは、マルチスケールのメリットを継承することが期待されています。(i)大きなスケールでノイズレベルが減少します。 (ii)マルチスケールの手順により、遍在する低周波ノイズは緩和される可能性があります。 (iii)除去前に画像をダウンサンプリングすることで、提出された受容的な受容を効果的に拡大することができます。堅牢なトレーニングのために、実際の画像除去のための生成敵対的ネットワーク(GAN)で訓練されたe眼の有効性は、まださらなる調査のままです。 Ganベースの除去の主な考え方は、敵対的な損失を導入して、除去された画像の知覚品質を改善することです。それに加えて、GANの際立った利点は、監視されていない学習を行うことができることです。より具体的には、グラウンドトゥルースのない騒々しいイメージをトレーニングで使用できます。これまでのところ、CNN除去者の実用性を改善するためのいくつかの可能なソリューションを提供してきました。これらのソリューションを組み合わせて、パフォーマンスをさらに向上させることができることに注意する必要があります。


