DnCNN
1.0.0
Notícias: Drunet
Desempenho de denoising de última geração
Pode ser usado para restauração de imagem plug-and-play

https://github.com/cszn/dpir/blob/master/main_dpir_denoising.py
I recommend to use the PyTorch code for training and testing. The model parameters of MatConvnet and PyTorch are same.
main_train_dncnn.py
main_test_dncnn.py
main_test_dncnn3_deblocking.py
import torch
import torch . nn as nn
def merge_bn ( model ):
''' merge all 'Conv+BN' (or 'TConv+BN') into 'Conv' (or 'TConv')
based on https://github.com/pytorch/pytorch/pull/901
by Kai Zhang ([email protected])
https://github.com/cszn/DnCNN
01/01/2019
'''
prev_m = None
for k , m in list ( model . named_children ()):
if ( isinstance ( m , nn . BatchNorm2d ) or isinstance ( m , nn . BatchNorm1d )) and ( isinstance ( prev_m , nn . Conv2d ) or isinstance ( prev_m , nn . Linear ) or isinstance ( prev_m , nn . ConvTranspose2d )):
w = prev_m . weight . data
if prev_m . bias is None :
zeros = torch . Tensor ( prev_m . out_channels ). zero_ (). type ( w . type ())
prev_m . bias = nn . Parameter ( zeros )
b = prev_m . bias . data
invstd = m . running_var . clone (). add_ ( m . eps ). pow_ ( - 0.5 )
if isinstance ( prev_m , nn . ConvTranspose2d ):
w . mul_ ( invstd . view ( 1 , w . size ( 1 ), 1 , 1 ). expand_as ( w ))
else :
w . mul_ ( invstd . view ( w . size ( 0 ), 1 , 1 , 1 ). expand_as ( w ))
b . add_ ( - m . running_mean ). mul_ ( invstd )
if m . affine :
if isinstance ( prev_m , nn . ConvTranspose2d ):
w . mul_ ( m . weight . data . view ( 1 , w . size ( 1 ), 1 , 1 ). expand_as ( w ))
else :
w . mul_ ( m . weight . data . view ( w . size ( 0 ), 1 , 1 , 1 ). expand_as ( w ))
b . mul_ ( m . weight . data ). add_ ( m . bias . data )
del model . _modules [ k ]
prev_m = m
merge_bn ( m )
def tidy_sequential ( model ):
for k , m in list ( model . named_children ()):
if isinstance ( m , nn . Sequential ):
if m . __len__ () == 1 :
model . _modules [ k ] = m . __getitem__ ( 0 )
tidy_sequential ( m )Versão Simplenn
Versão DAGNN
[DEMOS] Demo_test_DnCNN-.m .
[modelos] incluindo os modelos treinados para denoising gaussiano; Um modelo único para denoising gaussiano, super-resolução de imagem única (SISR) e desbloqueio.
[Testsets] BSD68 e Set10 para avaliação de denoising gaussiana; Conjuntos de conjuntos de conjuntos de conjuntos de conjuntos Set5, Set14, BSD100 e Urban100 para avaliação do SISR; Classic5 e Live1 para avaliação de desbloqueio de imagem JPEG.
Treinei novos modelos flexíveis de DNCNN (FDNCNN) com base no FFDNET.
O FDNCNN pode lidar com a faixa de nível de ruído de [0, 75] por meio de um único modelo.
Demo_fdncnn_gray.m
Demo_FDNCNN_GRAY_CLIP.M
Demo_fdncnn_color.m
Demo_FDNCNN_COLOR_CLIP.M
Arquitetura de rede
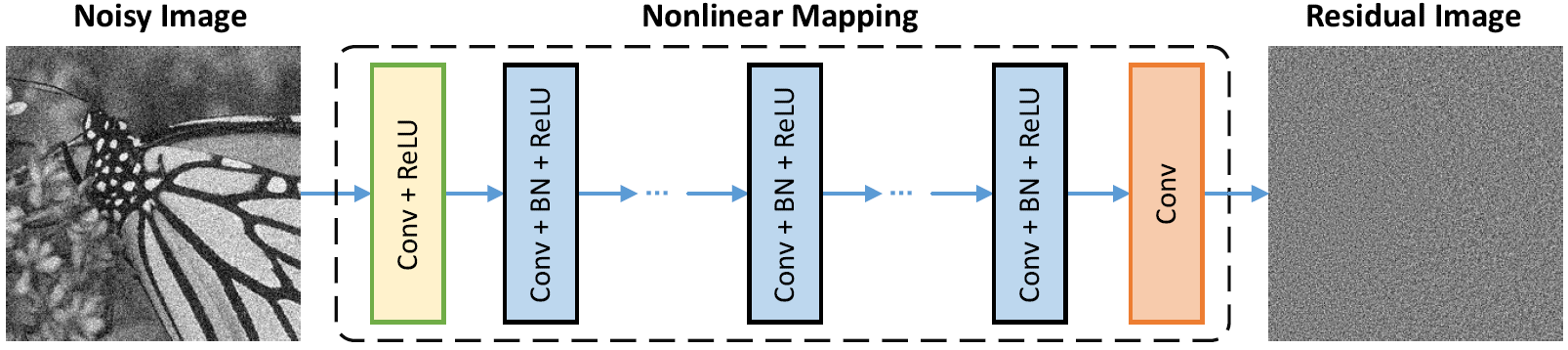
A normalização do lote e o aprendizado residual são benéficos para o denoising gaussiano (especialmente para um único nível de ruído). O resíduo de uma imagem barulhenta corrompida pelo ruído gaussiano branco aditivo (AWGN) segue uma distribuição gaussiana constante que estabiliza a normalização do lote durante o treinamento.
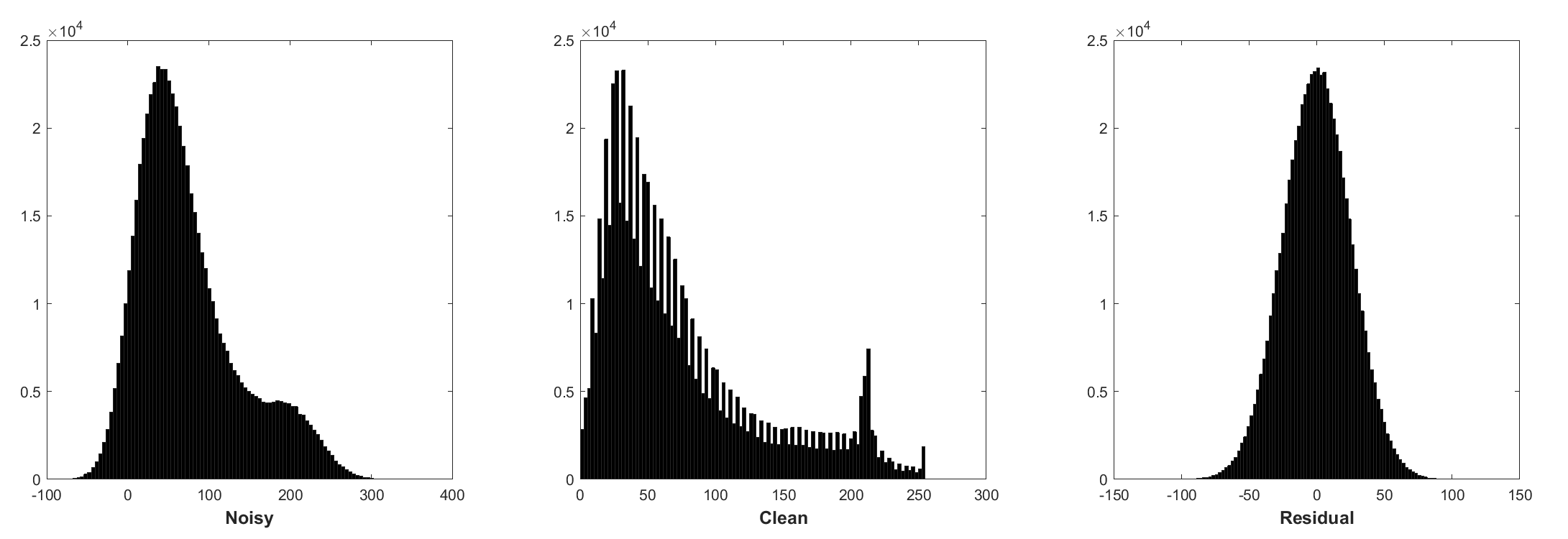
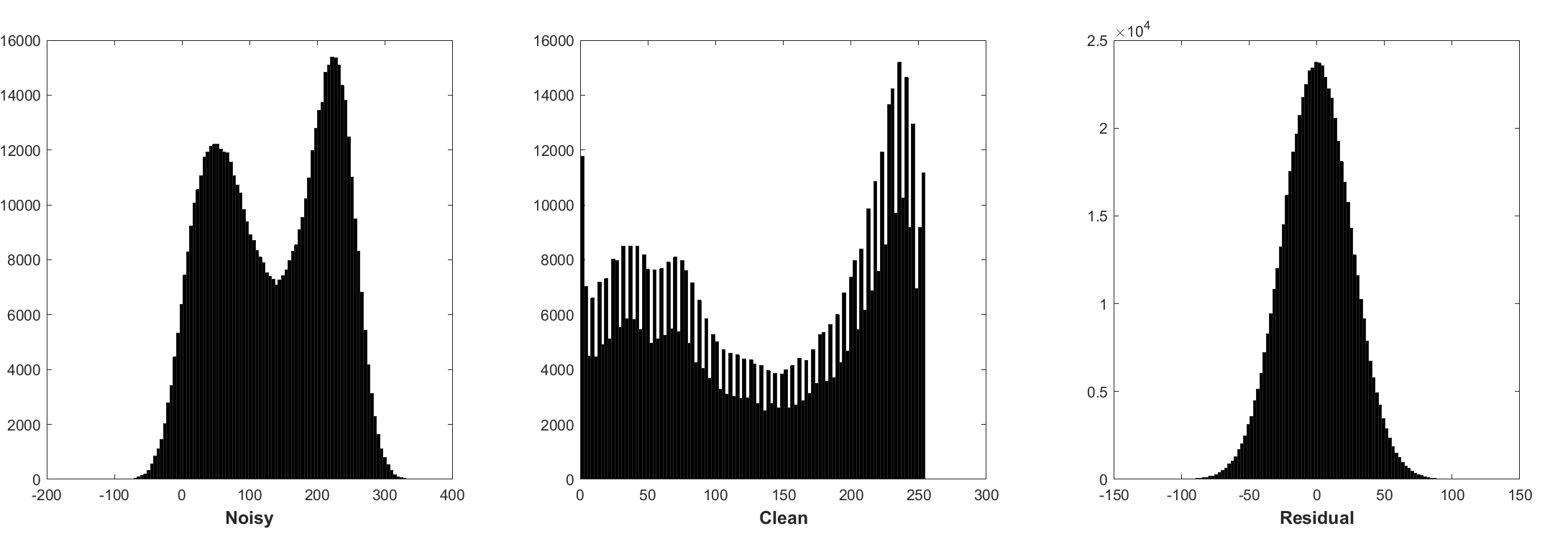
A previsão do resíduo pode ser interpretada como execução de uma etapa de inferência de descendência de gradiente no ponto de partida (ou seja, imagem barulhenta).
Os parâmetros no DNCNN representam principalmente os anteriores da imagem (independentes de tarefas); portanto, é possível aprender um único modelo para diferentes tarefas, como denoising de imagem, super-resolução de imagem e desbloqueio de imagem JPEG.
A esquerda é a imagem de entrada corrompida por diferentes degradações, a direita é a imagem restaurada pelo DNCNN-3.


Os resultados médios do PSNR (DB) de diferentes métodos no conjunto de dados BSD68.
| Nível de ruído | BM3D | Wnnm | Epll | MLP | CSF | Tnrd | Dncnn | Dncnn-b | Fdncnn | Drunet |
|---|---|---|---|---|---|---|---|---|---|---|
| 15 | 31.07 | 31.37 | 31.21 | - | 31.24 | 31.42 | 31.73 | 31.61 | 31.69 | 31.91 |
| 25 | 28.57 | 28.83 | 28.68 | 28.96 | 28.74 | 28.92 | 29.23 | 29.16 | 29.22 | 29.48 |
| 50 | 25.62 | 25.87 | 25.67 | 26.03 | - | 25.97 | 26.23 | 26.23 | 26.27 | 26.59 |
Resultados visuais
A esquerda é a imagem barulhenta corrompida por AWGN, o meio é a imagem denoada por DNCNN, a direita é a verdadeira-verdade.









Resultados médios de PSNR (dB)/SSIM de diferentes métodos para o denoising gaussiano com o ruído Nível 15, 25 e 50 no conjunto de dados BSD68, super-resolução de imagem única com fatores de aumento 2, 3 e 40 em SET5, Set14, 20, 20 e Urban100 DataSets, JPEG Image Deblock com Qualidade 10, 20, 20, 20, 20, 30 e Urban100 DataSets, JPEG Image Deblock com Qualidade 10, 20, 20, 20, 20, 20, 30 e Urban100 DataSets, JPEG Image Deblock com qualidade 10.
| Conjunto de dados | Nível de ruído | BM3D | Tnrd | DNCNN-3 |
|---|---|---|---|---|
| 15 | 31.08 / 0,8722 | 31.42 / 0.8826 | 31.46 / 0.8826 | |
| BSD68 | 25 | 28.57 / 0.8017 | 28.92 / 0.8157 | 29.02 / 0.8190 |
| 50 | 25.62 / 0.6869 | 25.97 / 0.7029 | 26.10 / 0.7076 |
| Conjunto de dados | Fator de aumento | Tnrd | Vdsr | DNCNN-3 |
|---|---|---|---|---|
| 2 | 36.86 / 0,9556 | 37.56 / 0,9591 | 37.58 / 0,9590 | |
| Set5 | 3 | 33.18 / 0,9152 | 33.67 / 0,9220 | 33.75 / 0,9222 |
| 4 | 30.85 / 0,8732 | 31.35 / 0.8845 | 31.40 / 0.8845 | |
| 2 | 32.51 / 0.9069 | 33.02 / 0,9128 | 33.03 / 0,9128 | |
| Set14 | 3 | 29.43 / 0,8232 | 29.77 / 0,8318 | 29.81 / 0,8321 |
| 4 | 27.66 / 0,7563 | 27.99 / 0,7659 | 28.04 / 0,7672 | |
| 2 | 31.40 / 0.8878 | 31.89 / 0.8961 | 31.90 / 0,8961 | |
| BSD100 | 3 | 28.50 / 0,7881 | 28.82 / 0,7980 | 28.85 / 0,7981 |
| 4 | 27.00 / 0.7140 | 27.28 / 0,7256 | 27.29 / 0,7253 | |
| 2 | 29.70 / 0,8994 | 30.76 / 0.9143 | 30.74 / 0.9139 | |
| Urban100 | 3 | 26.42 / 0.8076 | 27.13 / 0,8283 | 27.15 / 0,8276 |
| 4 | 24.61 / 0,7291 | 25.17 / 0,7528 | 25.20 / 0,7521 |
| Conjunto de dados | Fator de qualidade | Ar-cnn | Tnrd | DNCNN-3 |
|---|---|---|---|---|
| Classic5 | 10 | 29.03 / 0,7929 | 29.28 / 0,7992 | 29.40 / 0.8026 |
| 20 | 31.15 / 0.8517 | 31.47 / 0.8576 | 31.63 / 0.8610 | |
| 30 | 32.51 / 0.8806 | 32.78 / 0,8837 | 32.91 / 0,8861 | |
| 40 | 33.34 / 0,8953 | - | 33.77 / 0.9003 | |
| Live1 | 10 | 28.96 / 0.8076 | 29.15 / 0.8111 | 29.19 / 0,8123 |
| 20 | 31.29 / 0,8733 | 31.46 / 0,8769 | 31.59 / 0.8802 | |
| 30 | 32.67 / 0.9043 | 32.84 / 0.9059 | 32.98 / 0.9090 | |
| 40 | 33.63 / 0.9198 | - | 33.96 / 0,9247 |
ou apenas MATLAB R2015B para testar o modelo.
Dncnn/Demo_test_dncnn.m
Linhas 64 a 65 em 4a4b5b8
@article { zhang2017beyond ,
title = { Beyond a {Gaussian} denoiser: Residual learning of deep {CNN} for image denoising } ,
author = { Zhang, Kai and Zuo, Wangmeng and Chen, Yunjin and Meng, Deyu and Zhang, Lei } ,
journal = { IEEE Transactions on Image Processing } ,
year = { 2017 } ,
volume = { 26 } ,
number = { 7 } ,
pages = { 3142-3155 } ,
}
@article { zhang2020plug ,
title = { Plug-and-Play Image Restoration with Deep Denoiser Prior } ,
author = { Zhang, Kai and Li, Yawei and Zuo, Wangmeng and Zhang, Lei and Van Gool, Luc and Timofte, Radu } ,
journal = { arXiv preprint } ,
year = { 2020 }
}========================================================================
@Inbook{zuo2018convolutional,
author={Zuo, Wangmeng and Zhang, Kai and Zhang, Lei},
editor={Bertalm{'i}o, Marcelo},
title={Convolutional Neural Networks for Image Denoising and Restoration},
bookTitle={Denoising of Photographic Images and Video: Fundamentals, Open Challenges and New Trends},
year={2018},
publisher={Springer International Publishing},
address={Cham},
pages={93--123},
isbn={978-3-319-96029-6},
doi={10.1007/978-3-319-96029-6_4},
url={https://doi.org/10.1007/978-3-319-96029-6_4}
}
Embora a imagem de denoising para a remoção da AWGN tenha sido bem estudada, pouco trabalho foi feito em denoising de imagem real. A principal dificuldade surge do fato de que ruídos reais são muito mais complexos que o AWGN e não é uma tarefa fácil avaliar completamente o desempenho de um denoiser. A Fig. 4.15 mostra quatro tipos de ruído típicos no mundo real. Pode -se observar que as características desses ruídos são muito diferentes e um único nível de ruído pode não ser suficiente para parametrizar esses tipos de ruído. Na maioria dos casos, um denoiser só pode funcionar bem sob um determinado modelo de ruído. Por exemplo, um modelo de denoising treinado para a remoção do AWGN não é eficaz para a remoção mista de ruído gaussiano e Poisson. Isso é intuitivamente razoável porque os métodos baseados em CNN podem ser tratados como caso geral da Eq. (4.3) e o termo importante de fidelidade de dados corresponde ao processo de degradação. Apesar disso, a imagem DenOising para a remoção do AWGN é valiosa devido aos seguintes motivos. Primeiro, é um leito de teste ideal para avaliar a eficácia de diferentes métodos de denoising baseados na CNN. Segundo, na inferência desenrolada por meio de técnicas de divisão variável, muitos problemas de restauração de imagens podem ser abordados resolvendo sequencialmente uma série de subproblemas de denoising gaussiano, o que amplia ainda mais os campos de aplicação.

Para melhorar a praticabilidade de um denoiser da CNN, talvez a maneira mais direta seja capturar quantidades adequadas de pares de treinamento com limpeza de barulho para treinamento para que o espaço real de degradação possa ser coberto. Esta solução tem vantagem de que não há necessidade de conhecer o complexo processo de degradação. No entanto, derivar a imagem limpa correspondente de uma barulhenta não é uma tarefa trivial devido à necessidade de etapas cuidadosas de pós-processamento, como alinhamento espacial e correção de iluminação. Como alternativa, pode -se simular o processo de degradação real para sintetizar imagens barulhentas para uma limpeza. No entanto, não é fácil modelar com precisão o complexo processo de degradação. Em particular, o modelo de ruído pode ser diferente em diferentes câmeras. No entanto, é praticamente preferível modelar aproximadamente um certo tipo de ruído para treinamento e depois usar o modelo CNN instruído para denoising específico do tipo.
Além dos dados de treinamento, a arquitetura robusta e o treinamento robusto também desempenham papéis vitais para o sucesso de um Denoiser da CNN. Para a arquitetura robusta, projetar uma CNN em várias escalas que envolve um procedimento grosso para a fila é uma direção promissora. Espera -se que essa rede herde o mérito de várias escalas: (i) o nível de ruído diminui em escalas maiores; (ii) o onipresente ruído de baixa frequência pode ser aliviado pelo procedimento em várias escalas; e (iii) a redução da amostra da imagem antes de denoising pode efetivamente aumentar o registrado receptivo. Para o treinamento robusto, a eficácia do denoiser treinou com redes adversárias generativas (GaN) para a imagem real denoising ainda continua sendo uma investigação mais aprofundada. A principal idéia do denoising baseado em GaN é introduzir uma perda contraditória para melhorar a qualidade perceptiva da imagem denoada. Além disso, uma vantagem distinta do GaN é que ele pode fazer aprendizado sem supervisão. Mais especificamente, a imagem barulhenta sem a verdade do fundamento pode ser usada no treinamento. Até agora, fornecemos várias soluções possíveis para melhorar a praticabilidade de um Denoiser da CNN. Devemos observar que essas soluções podem ser combinadas para melhorar ainda mais o desempenho.


