parsbert
1.0.0
Parsbert是基于Google的Bert体系结构的单语言模型。该模型已在大型波斯语料库中进行了预培训,该模型具有来自众多主题(例如,科学,小说,新闻)的各种写作风格,具有超过3.9M文档, 73M句子和1.3B字。
论文呈现Parsbert:doi:10.1007/s11063-021-10528-4
当前版本:V3
ParsBERT trained on a massive amount of public corpora (Persian Wikidumps, MirasText) and six other manually crawled text data from a various type of websites (BigBang Page scientific , Chetor lifestyle , Eligasht itinerary , Digikala digital magazine , Ted Talks general conversational , Books novels, storybooks, short stories from old to the contemporary era ).
作为Parsbert方法论的一部分,进行了广泛的预处理,结合了POS标签和文书分段,以使Corpora成为适当的格式。
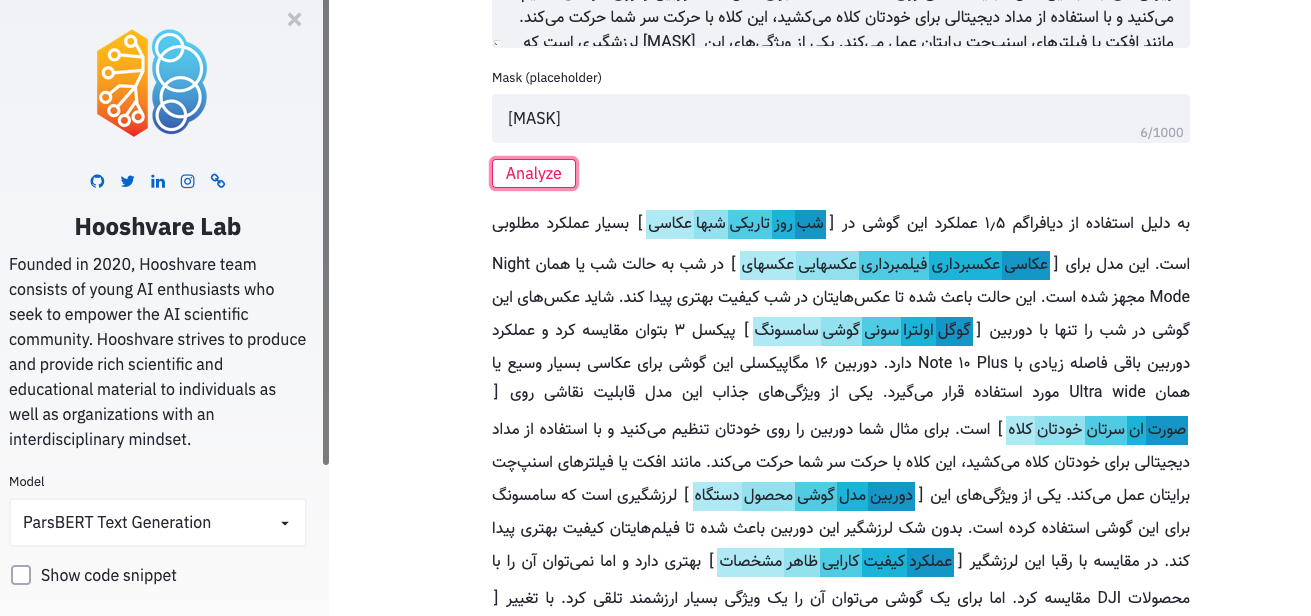
帕斯伯特游乐场
Parsbert在三个NLP下游任务上进行了评估:情感分析(SA),文本分类和命名实体识别(NER)。对于此问题,由于资源不足,手动组成了两个用于SA的大型数据集和两个用于文本分类的大型数据集,可用于公共使用和基准测试。帕斯伯特(Parsbert)的表现优于所有其他语言模型,包括用于所有任务的多语言BERT和其他混合深度学习模型,从而提高了波斯语模型的最新性能。
下表与其他模型和体系结构相比,总结了Parsbert获得的F1分数。
| 数据集 | Parsbert V3 | Parsbert V2 | Parsbert V1 | 姆伯特 | 深森特人 |
|---|---|---|---|---|---|
| Digikala用户评论 | - | 81.72 | 81.74* | 80.74 | - |
| Snappfood用户评论 | - | 87.98 | 88.12* | 87.87 | - |
| 哨兵(多类) | - | 71.31* | 71.11 | - | 69.33 |
| 哨兵(二进制班) | - | 92.42* | 92.13 | - | 91.98 |
| 数据集 | Parsbert V3 | Parsbert V2 | Parsbert V1 | 姆伯特 |
|---|---|---|---|---|
| Digikala杂志 | - | 93.65* | 93.59 | 90.72 |
| 波斯新闻 | - | 97.44* | 97.19 | 95.79 |
| 数据集 | Parsbert V3 | Parsbert V2 | Parsbert V1 | 姆伯特 | Morphobert | Beheshti-ner | LSTM-CRF | 基于规则的CRF | Bilstm-Crf |
|---|---|---|---|---|---|---|---|---|---|
| 皮马 | 93.40* | 93.10 | 86.64 | - | 90.59 | - | 84.00 | - | |
| 阿曼 | 99.84* | 98.79 | 95.89 | 89.9 | 84.03 | 86.55 | - | 77.45 |
如果您在公共数据集上测试了Parsbert,并且要将结果添加到上表中,请打开拉请请求或与我们联系。另请确保您的代码在线可用,以便我们可以将其添加为参考
from transformers import AutoConfig , AutoTokenizer , AutoModel , TFAutoModel
# v3.0
model_name_or_path = "HooshvareLab/bert-fa-zwnj-base"
config = AutoConfig . from_pretrained ( model_name_or_path )
tokenizer = AutoTokenizer . from_pretrained ( model_name_or_path )
# model = TFAutoModel.from_pretrained(model_name_or_path) For TF
model = AutoModel . from_pretrained ( model_name_or_path )
text = "ما در هوشواره معتقدیم با انتقال صحیح دانش و آگاهی، همه افراد میتوانند از ابزارهای هوشمند استفاده کنند. شعار ما هوش مصنوعی برای همه است."
tokenizer . tokenize ( text )
[ 'ما' , 'در' , 'هوش' , '[ZWNJ]' , 'واره' , 'معتقدیم' , 'با' , 'انتقال' , 'صحیح' , 'دانش' , 'و' , 'آ' , '##گاهی' , '،' , 'همه' , 'افراد' , 'میتوانند' , 'از' , 'ابزارهای' , 'هوشمند' , 'استفاده' , 'کنند' , '.' , 'شعار' , 'ما' , 'هوش' , 'مصنوعی' , 'برای' , 'همه' , 'است' , '.' ]| 笔记本 | |
|---|---|
| 文本分类 | |
| 情感分析 | |
| 命名实体识别 | |
| 文字生成 |
如果您在研究中使用Parsbert,请在出版物中引用以下论文:
@article { ParsBERT ,
title = { Parsbert: Transformer-based model for Persian language understanding } ,
DOI = { 10.1007/s11063-021-10528-4 } ,
journal = { Neural Processing Letters } ,
author = { Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri } ,
year = { 2021 }
} 在此,我们对Tensorflow Research Cloud(TFRC)计划表示感谢,以为我们提供必要的计算资源。我们还要感谢Hooshvare Research Group促进数据集收集和刮擦在线文本资源。
今天可以使用新版本的Bert v3.0 V3.0,并且可以解决波斯写作的零宽非加路人角色。此外,该模型还接受了新的多类型语料库的培训,并具有新的词汇量。
可获得:Hooshvarelab/bert-fa-zwnj-base
Parsbert v2.0:我们重建了词汇量,并在新波斯语料库上对Parsbert v1.1进行了微调,以便为在其他范围中使用Parsbert提供一些功能!训练期间的客观目标如下(30万步之后)。
***** Eval results *****
global_step = 300000
loss = 1.4392426
masked_lm_accuracy = 0.6865794
masked_lm_loss = 1.4469004
next_sentence_accuracy = 1.0
next_sentence_loss = 6.534152e-05可获得:Hooshvarelab/Bert-Fa-base-unc.unc.
PARSBERT v1.1:我们根据同一波斯语料库和Bert-Base配置继续进行超过250万步的培训。培训期间的客观目标如下(250万步骤之后)。
***** Eval results *****
global_step = 2575000
loss = 1.3973521
masked_lm_accuracy = 0.70044917
masked_lm_loss = 1.3974043
next_sentence_accuracy = 0.9976562
next_sentence_loss = 0.0088804625可获得:Hooshvarelab/Bert-Base-Parsbert-uncund
PARSBERT V1:这是我们基于Bert-Base的Parsbert的第一个版本。该模型经过了1920000步骤的庞大波斯语料库培训。培训期间的客观目标如下(19m步骤之后)。
***** Eval results *****
global_step = 1920000
loss = 2.6646128
masked_lm_accuracy = 0.583321
masked_lm_loss = 2.2517521
next_sentence_accuracy = 0.885625
next_sentence_loss = 0.3884369可获得:Hooshvarelab/Bert-Base-Parsbert-uncund
Apache许可证2.0


