parsbert
1.0.0
Parsbert adalah model bahasa monolingual berdasarkan arsitektur Bert Google. Model ini dilatih sebelumnya pada korpora Persia besar dengan berbagai gaya penulisan dari berbagai subjek (misalnya, ilmiah, novel, berita) dengan lebih dari 3.9M dokumen, 73M kalimat, dan 1.3B kata.
Makalah yang menyajikan Parsbert: doi: 10.1007/s11063-021-10528-4
Versi Saat Ini: V3
Parsbert dilatih pada sejumlah besar korpora publik (Persia Wikidumps, Mirastext) dan enam data teks merangkak manual lainnya dari berbagai jenis situs web (Bigbang Page scientific , Chetor lifestyle , Eligasht itinerary , Digikala digital magazine , TED Talks general conversational , buku novels, storybooks, short stories from old to the contemporary era ).
Sebagai bagian dari metodologi Parsbert, pra-pemrosesan yang luas menggabungkan penandaan POS dan segmentasi Wordpiece dilakukan untuk membawa korpora ke dalam format yang tepat.
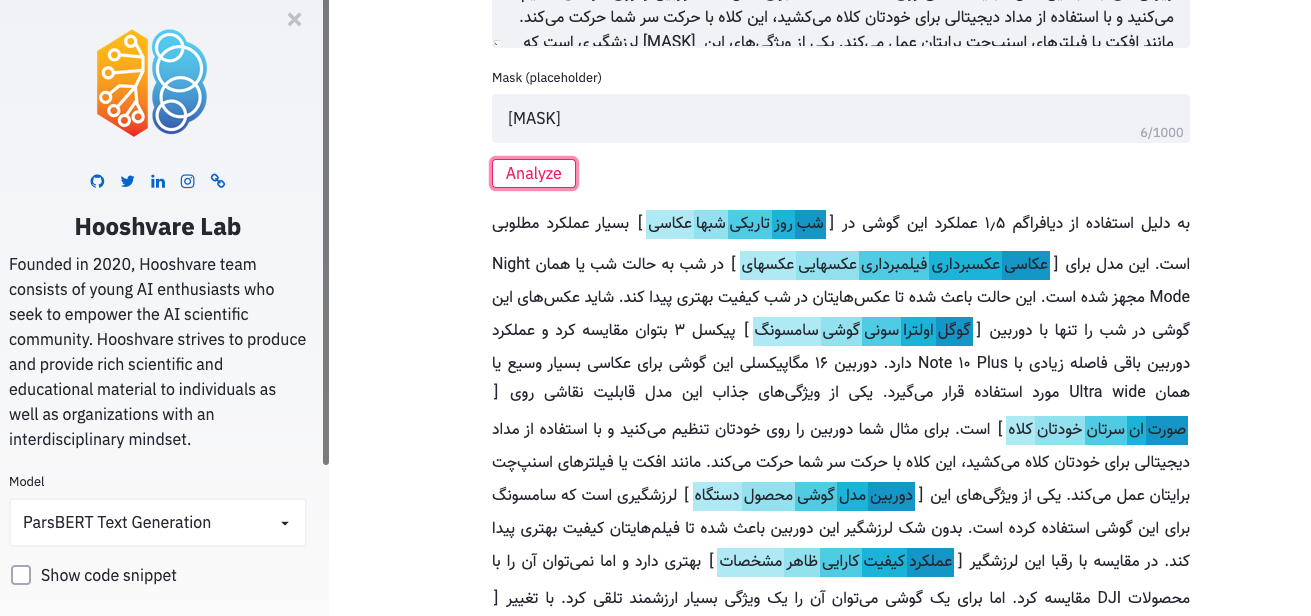
Parsbert Playground
Parsbert dievaluasi pada tiga tugas hilir NLP: analisis sentimen (SA), klasifikasi teks, dan pengenalan entitas yang dinamai (NER). Untuk masalah ini dan karena sumber daya yang tidak mencukupi, dua kumpulan data besar untuk SA dan dua untuk klasifikasi teks disusun secara manual, yang tersedia untuk penggunaan publik dan pembandingan. Parsbert mengungguli semua model bahasa lainnya, termasuk Bert multibahasa dan model pembelajaran mendalam lainnya untuk semua tugas, meningkatkan kinerja canggih dalam pemodelan bahasa Persia.
Tabel berikut merangkum skor F1 yang diperoleh Parsbert dibandingkan dengan model dan arsitektur lain.
| Dataset | Parsbert v3 | Parsbert v2 | Parsbert V1 | mbert | Deepsentipers |
|---|---|---|---|---|---|
| Komentar Pengguna Digikala | - | 81.72 | 81.74* | 80.74 | - |
| Komentar Pengguna Snappfood | - | 87.98 | 88.12* | 87.87 | - |
| SENIPERS (MULTI CLASS) | - | 71.31* | 71.11 | - | 69.33 |
| Sustipers (Kelas Biner) | - | 92.42* | 92.13 | - | 91.98 |
| Dataset | Parsbert v3 | Parsbert v2 | Parsbert V1 | mbert |
|---|---|---|---|---|
| Majalah Digikala | - | 93.65* | 93.59 | 90.72 |
| Berita Persia | - | 97.44* | 97.19 | 95.79 |
| Dataset | Parsbert v3 | Parsbert v2 | Parsbert V1 | mbert | Morphobert | Beheshti-ner | LSTM-CRF | CRF berbasis aturan | BILSTM-CRF |
|---|---|---|---|---|---|---|---|---|---|
| PEYMA | 93.40* | 93.10 | 86.64 | - | 90.59 | - | 84.00 | - | |
| Arman | 99.84* | 98.79 | 95.89 | 89.9 | 84.03 | 86.55 | - | 77.45 |
Jika Anda menguji Parsbert pada dataset publik, dan Anda ingin menambahkan hasil Anda ke tabel di atas, buka permintaan tarik atau hubungi kami. Pastikan juga memiliki kode Anda secara online sehingga kami dapat menambahkannya sebagai referensi
from transformers import AutoConfig , AutoTokenizer , AutoModel , TFAutoModel
# v3.0
model_name_or_path = "HooshvareLab/bert-fa-zwnj-base"
config = AutoConfig . from_pretrained ( model_name_or_path )
tokenizer = AutoTokenizer . from_pretrained ( model_name_or_path )
# model = TFAutoModel.from_pretrained(model_name_or_path) For TF
model = AutoModel . from_pretrained ( model_name_or_path )
text = "ما در هوشواره معتقدیم با انتقال صحیح دانش و آگاهی، همه افراد میتوانند از ابزارهای هوشمند استفاده کنند. شعار ما هوش مصنوعی برای همه است."
tokenizer . tokenize ( text )
[ 'ما' , 'در' , 'هوش' , '[ZWNJ]' , 'واره' , 'معتقدیم' , 'با' , 'انتقال' , 'صحیح' , 'دانش' , 'و' , 'آ' , '##گاهی' , '،' , 'همه' , 'افراد' , 'میتوانند' , 'از' , 'ابزارهای' , 'هوشمند' , 'استفاده' , 'کنند' , '.' , 'شعار' , 'ما' , 'هوش' , 'مصنوعی' , 'برای' , 'همه' , 'است' , '.' ]| Buku catatan | |
|---|---|
| Klasifikasi Teks | |
| Analisis sentimen | |
| Pengakuan entitas yang disebutkan | |
| Pembuatan teks |
Harap kutip makalah berikut dalam publikasi Anda jika Anda menggunakan Parsbert dalam penelitian Anda:
@article { ParsBERT ,
title = { Parsbert: Transformer-based model for Persian language understanding } ,
DOI = { 10.1007/s11063-021-10528-4 } ,
journal = { Neural Processing Letters } ,
author = { Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri } ,
year = { 2021 }
} Kami dengan ini, mengucapkan terima kasih kepada program TensorFlow Research Cloud (TFRC) untuk memberi kami sumber daya perhitungan yang diperlukan. Kami juga berterima kasih kepada Hooshvare Research Group karena memfasilitasi pengumpulan dataset dan mengikis sumber daya teks online.
Versi baru Bert V3.0 untuk Persia tersedia saat ini dan dapat menangani karakter non-joiner nol-lebar untuk penulisan Persia. Juga, model ini dilatih pada korpora multi-tipe baru dengan serangkaian kosa kata baru.
Tersedia oleh: hooshvarelab/bert-fa-zwnj-base
Parsbert V2.0: Kami merekonstruksi kosa kata dan menyempurnakan Parsbert v1.1 pada korpora Persia baru untuk memberikan beberapa fungsi untuk menggunakan Parsbert dalam lingkup lain! Tujuan obyektif selama pelatihan adalah seperti di bawah ini (setelah 300 ribu langkah).
***** Eval results *****
global_step = 300000
loss = 1.4392426
masked_lm_accuracy = 0.6865794
masked_lm_loss = 1.4469004
next_sentence_accuracy = 1.0
next_sentence_loss = 6.534152e-05Tersedia oleh: Hooshvarelab/Bert-Fa-Base-Incased
Parsbert V1.1: Kami melanjutkan pelatihan untuk lebih dari 2,5 juta langkah berdasarkan pada korpora Persia yang sama dan konfigurasi BERT-BASE. Tujuan obyektif selama pelatihan adalah seperti di bawah ini (setelah 2,5 m langkah).
***** Eval results *****
global_step = 2575000
loss = 1.3973521
masked_lm_accuracy = 0.70044917
masked_lm_loss = 1.3974043
next_sentence_accuracy = 0.9976562
next_sentence_loss = 0.0088804625Tersedia oleh: Hooshvarelab/Bert-Base-Parsbert-Incased
Parsbert V1: Ini adalah versi pertama dari Parsbert kami berdasarkan Bert-Base. Model ini dilatih pada korpora Persia yang luas untuk langkah 1920000. Tujuan obyektif selama pelatihan adalah seperti di bawah ini (setelah 1,9m langkah).
***** Eval results *****
global_step = 1920000
loss = 2.6646128
masked_lm_accuracy = 0.583321
masked_lm_loss = 2.2517521
next_sentence_accuracy = 0.885625
next_sentence_loss = 0.3884369Tersedia oleh: Hooshvarelab/Bert-Base-Parsbert-Incased
Lisensi Apache 2.0


