parsbert
1.0.0
Parsbertは、GoogleのBertアーキテクチャに基づいた単一言語モデルです。このモデルは、 3.9M以上の文書、 73M万文、 1.3B単語を備えた多数の科目(科学、小説、ニュースなど)のさまざまな執筆スタイルを持つペルシャの大規模なコーパスで事前に訓練されています。
Parsbertの提示論文:doi:10.1007/s11063-021-10528-4
現在のバージョン:V3
Parsbertは、膨大な量のパブリックコーポラ(ペルシャ語のウィキムンサ、ミラストテキスト)と、さまざまなタイプのWebサイト(Bigbang Page scientific 、Chetor lifestyle 、Eligashtのitinerary 、Digikala digital magazine 、Ted Talks general conversational 、Books novels, storybooks, short stories from old to the contemporary era )で大量に訓練を受けました。
Parsbertの方法論の一環として、POSタグ付けとWordピースセグメンテーションを組み合わせた広範な前処理を組み合わせて、コーパスを適切な形式にすることが実施されました。
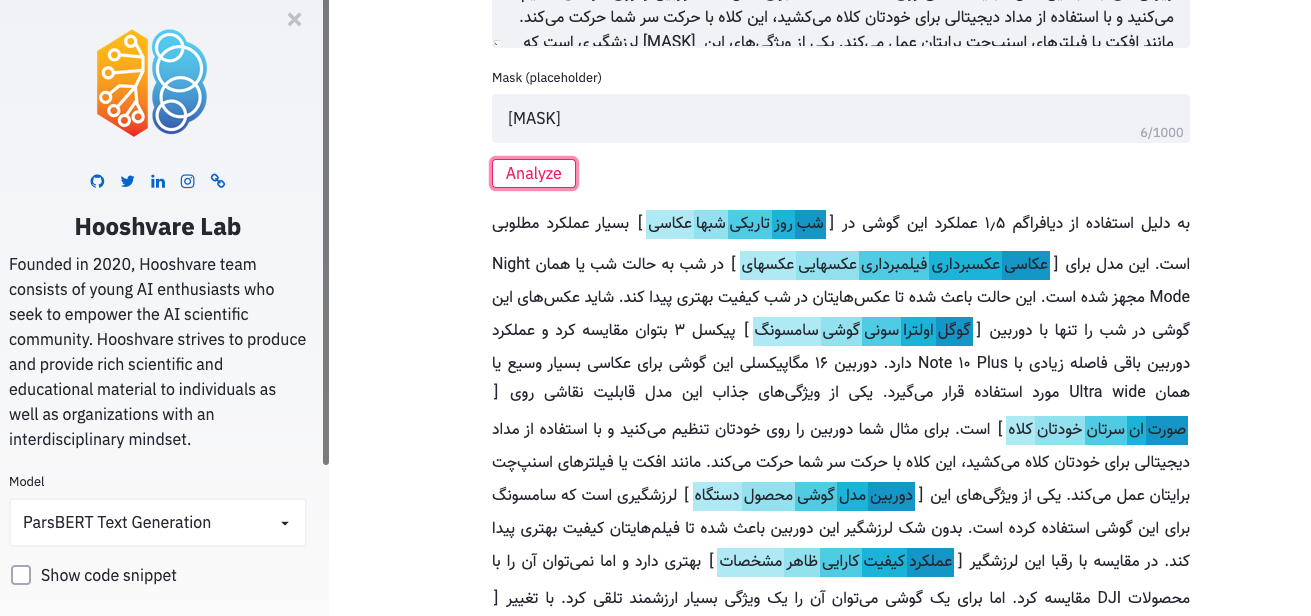
パセバートの遊び場
Parsbertは、3つのNLPダウンストリームタスクで評価されます:センチメント分析(SA)、テキスト分類、および名前付きエンティティ認識(NER)。この問題とリソースが不十分であるため、SAの2つの大きなデータセットとテキスト分類用の2つの大きなデータセットが手動で構成されました。 Parsbertは、すべてのタスクの多言語BERTやその他のハイブリッドディープラーニングモデルなど、他のすべての言語モデルを上回り、ペルシャ語モデリングの最先端のパフォーマンスを改善しました。
次の表は、他のモデルやアーキテクチャと比較して、Parsbertが取得したF1スコアをまとめたものです。
| データセット | Parsbert V3 | Parsbert V2 | Parsbert V1 | Mbert | ディープセン師 |
|---|---|---|---|---|---|
| Digikalaユーザーのコメント | - | 81.72 | 81.74* | 80.74 | - |
| Snappfoodユーザーのコメント | - | 87.98 | 88.12* | 87.87 | - |
| センチパーズ(マルチクラス) | - | 71.31* | 71.11 | - | 69.33 |
| Sentipers(バイナリクラス) | - | 92.42* | 92.13 | - | 91.98 |
| データセット | Parsbert V3 | Parsbert V2 | Parsbert V1 | Mbert |
|---|---|---|---|---|
| Digikala Magazine | - | 93.65* | 93.59 | 90.72 |
| ペルシャのニュース | - | 97.44* | 97.19 | 95.79 |
| データセット | Parsbert V3 | Parsbert V2 | Parsbert V1 | Mbert | モルフォベルト | Beheshti-ner | LSTM-CRF | ルールベースのCRF | bilstm-crf |
|---|---|---|---|---|---|---|---|---|---|
| ペイマ | 93.40* | 93.10 | 86.64 | - | 90.59 | - | 84.00 | - | |
| アーマン | 99.84* | 98.79 | 95.89 | 89.9 | 84.03 | 86.55 | - | 77.45 |
パブリックデータセットでParsbertをテストし、上記のテーブルに結果を追加する場合は、プルリクエストを開くか、お問い合わせください。また、コードをオンラインで利用できるようにしてください。そうすれば、参照として追加できます
from transformers import AutoConfig , AutoTokenizer , AutoModel , TFAutoModel
# v3.0
model_name_or_path = "HooshvareLab/bert-fa-zwnj-base"
config = AutoConfig . from_pretrained ( model_name_or_path )
tokenizer = AutoTokenizer . from_pretrained ( model_name_or_path )
# model = TFAutoModel.from_pretrained(model_name_or_path) For TF
model = AutoModel . from_pretrained ( model_name_or_path )
text = "ما در هوشواره معتقدیم با انتقال صحیح دانش و آگاهی، همه افراد میتوانند از ابزارهای هوشمند استفاده کنند. شعار ما هوش مصنوعی برای همه است."
tokenizer . tokenize ( text )
[ 'ما' , 'در' , 'هوش' , '[ZWNJ]' , 'واره' , 'معتقدیم' , 'با' , 'انتقال' , 'صحیح' , 'دانش' , 'و' , 'آ' , '##گاهی' , '،' , 'همه' , 'افراد' , 'میتوانند' , 'از' , 'ابزارهای' , 'هوشمند' , 'استفاده' , 'کنند' , '.' , 'شعار' , 'ما' , 'هوش' , 'مصنوعی' , 'برای' , 'همه' , 'است' , '.' ]| ノート | |
|---|---|
| テキスト分類 | |
| 感情分析 | |
| 名前付きエンティティ認識 | |
| テキスト生成 |
あなたがあなたの研究でParsbertを使用している場合、あなたの出版物で次の論文を引用してください:
@article { ParsBERT ,
title = { Parsbert: Transformer-based model for Persian language understanding } ,
DOI = { 10.1007/s11063-021-10528-4 } ,
journal = { Neural Processing Letters } ,
author = { Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri } ,
year = { 2021 }
} ここで、必要な計算リソースを提供するために、Tensorflow Research Cloud(TFRC)プログラムに感謝します。また、データセットの収集とオンラインテキストリソースの削減を促進してくれたHooshvare Research Groupにも感謝します。
ペルシャ語向けのBert V3.0の新しいバージョンは、今日利用可能であり、ペルシャ語の執筆のためのゼロ幅の非ジョイナーキャラクターに取り組むことができます。また、このモデルは、新しい語彙セットを備えた新しいマルチタイプコーパスでトレーニングされました。
Hooshvarelab/Bert-fa-zwnj-baseで入手可能
Parsbert v2.0:他のスコープでParsbertを使用するための機能を提供するために、語彙を再構築し、新しいペルシャコーパラのParsbert v1.1を微調整しました!トレーニング中の客観的な目標は、以下のとおりです(300kステップ以降)。
***** Eval results *****
global_step = 300000
loss = 1.4392426
masked_lm_accuracy = 0.6865794
masked_lm_loss = 1.4469004
next_sentence_accuracy = 1.0
next_sentence_loss = 6.534152e-05利用可能:Hooshvarelab/Bert-Fa-Base-Uncased
Parsbert v1.1:同じペルシャのコーパスとバートベースの構成に基づいて、2.5m以上のステップのトレーニングを続けました。トレーニング中の客観的な目標は、下の(250万段のステップ以下)のとおりです。
***** Eval results *****
global_step = 2575000
loss = 1.3973521
masked_lm_accuracy = 0.70044917
masked_lm_loss = 1.3974043
next_sentence_accuracy = 0.9976562
next_sentence_loss = 0.0088804625利用可能:Hooshvarelab/Bert-Base-Parsbert-Uncased
Parsbert V1:これは、Bert-Baseに基づくParsbertの最初のバージョンです。このモデルは、1920000年の広大なペルシャコーパスで訓練されました。トレーニング中の客観的な目標は、以下のように(1.9mのステップ以降)。
***** Eval results *****
global_step = 1920000
loss = 2.6646128
masked_lm_accuracy = 0.583321
masked_lm_loss = 2.2517521
next_sentence_accuracy = 0.885625
next_sentence_loss = 0.3884369利用可能:Hooshvarelab/Bert-Base-Parsbert-Uncased
Apacheライセンス2.0


