parsbert
1.0.0
Парсберт - это одноязычная языковая модель, основанная на архитектуре Google Bert. Эта модель предварительно обучена на крупных персидских корпусах с различными стилями письма от многочисленных предметов (например, научные, романы, новости) с более чем 3.9M документами, 73M предложениями и словами 1.3B .
Представление бумаги Парсберта: DOI: 10.1007/S11063-021-10528-4
Текущая версия: v3
Парсберт обучался огромному количеству публичных корпораций (персидские викидумпс, Mirastext) и шесть других текстовых данных вручную с различных типами веб -сайтов (Bigbang Page scientific , Chetor lifestyle , itinerary Eligasht, Digikala digital magazine , Ted Talks general conversational , книги novels, storybooks, short stories from old to the contemporary era .
В рамках методологии Парсберта была проведена обширная предварительная обработка, объединяющая тегинги и сегментацию слова, чтобы привлечь корпора в правильный формат.
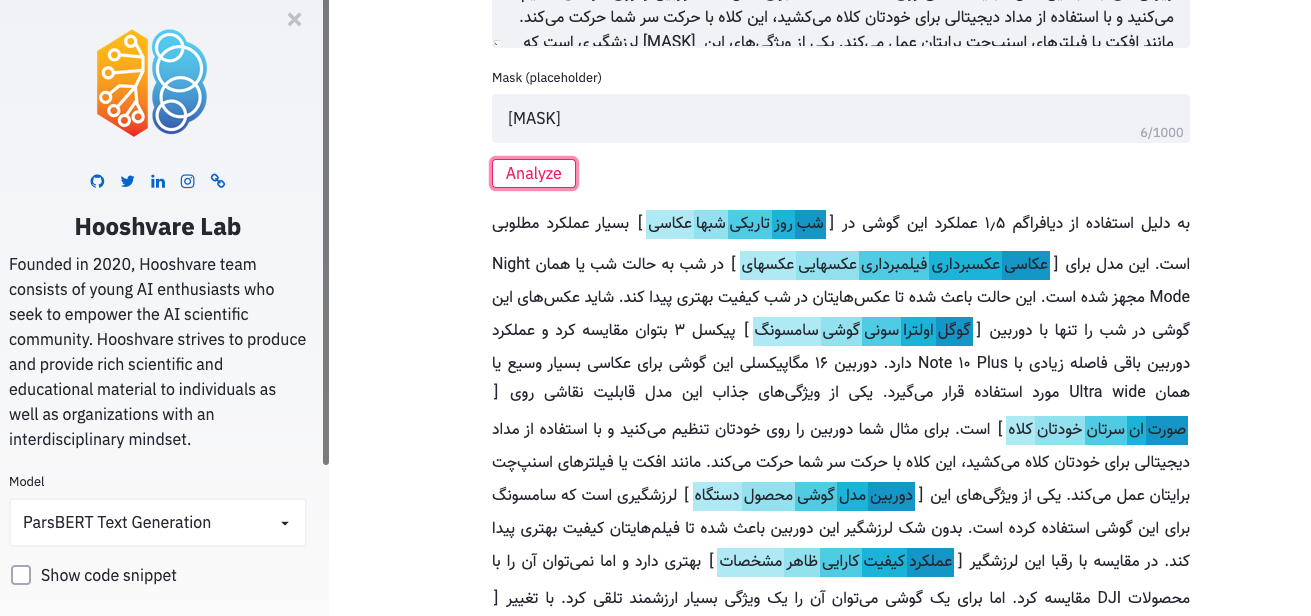
Парсберт Игровая площадка
Парсберт оценивается по трем задачам NLP вниз по течению: анализ настроений (SA), классификации текста и распознавание объектов (NER). Для этого вопроса и из -за недостаточных ресурсов были составлены два больших набора данных для SA и два для классификации текста, которые доступны для общественного использования и сравнительного анализа. Парсберт превзошел все другие языковые модели, в том числе многоязычные модели BERT и другие гибридные модели глубокого обучения для всех задач, улучшив современную производительность в моделировании персидского языка.
В следующей таблице суммируется оценка F1, полученная Парсбертом по сравнению с другими моделями и архитектурами.
| Набор данных | Парсберт v3 | Парсберт v2 | Парсберт V1 | Мберт | Deepsentipers |
|---|---|---|---|---|---|
| Комментарии пользователей Digikala | - | 81.72 | 81,74* | 80.74 | - |
| Комментарии пользователей Snappfood | - | 87.98 | 88.12* | 87.87 | - |
| Speering (Multi Class) | - | 71.31* | 71.11 | - | 69,33 |
| Speering (двоичный класс) | - | 92,42* | 92.13 | - | 91.98 |
| Набор данных | Парсберт v3 | Парсберт v2 | Парсберт V1 | Мберт |
|---|---|---|---|---|
| Журнал Digikala | - | 93,65* | 93,59 | 90.72 |
| Персидские новости | - | 97.44* | 97.19 | 95,79 |
| Набор данных | Парсберт v3 | Парсберт v2 | Парсберт V1 | Мберт | Морфоберт | Беашти-Пан | LSTM-CRF | CRF на основе правил | Bilstm-Crf |
|---|---|---|---|---|---|---|---|---|---|
| Пейма | 93,40* | 93.10 | 86.64 | - | 90.59 | - | 84,00 | - | |
| Арман | 99,84* | 98.79 | 95,89 | 89,9 | 84,03 | 86.55 | - | 77.45 |
Если вы протестировали Парсберт в общедоступном наборе данных, и вы хотите добавить свои результаты в таблицу выше, откройте запрос на привлечение или свяжитесь с нами. Также убедитесь, что ваш код доступен в Интернете, чтобы мы могли добавить его в качестве ссылки
from transformers import AutoConfig , AutoTokenizer , AutoModel , TFAutoModel
# v3.0
model_name_or_path = "HooshvareLab/bert-fa-zwnj-base"
config = AutoConfig . from_pretrained ( model_name_or_path )
tokenizer = AutoTokenizer . from_pretrained ( model_name_or_path )
# model = TFAutoModel.from_pretrained(model_name_or_path) For TF
model = AutoModel . from_pretrained ( model_name_or_path )
text = "ما در هوشواره معتقدیم با انتقال صحیح دانش و آگاهی، همه افراد میتوانند از ابزارهای هوشمند استفاده کنند. شعار ما هوش مصنوعی برای همه است."
tokenizer . tokenize ( text )
[ 'ما' , 'در' , 'هوش' , '[ZWNJ]' , 'واره' , 'معتقدیم' , 'با' , 'انتقال' , 'صحیح' , 'دانش' , 'و' , 'آ' , '##گاهی' , '،' , 'همه' , 'افراد' , 'میتوانند' , 'از' , 'ابزارهای' , 'هوشمند' , 'استفاده' , 'کنند' , '.' , 'شعار' , 'ما' , 'هوش' , 'مصنوعی' , 'برای' , 'همه' , 'است' , '.' ]| Блокнот | |
|---|---|
| Текстовая классификация | |
| Анализ настроений | |
| Названное признание сущности | |
| Генерация текста |
Пожалуйста, укажите следующую статью в вашей публикации, если вы используете Парсберт в своем исследовании:
@article { ParsBERT ,
title = { Parsbert: Transformer-based model for Persian language understanding } ,
DOI = { 10.1007/s11063-021-10528-4 } ,
journal = { Neural Processing Letters } ,
author = { Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri } ,
year = { 2021 }
} Настоящим мы выражаем нашу благодарность программе Tensorflow Research Cloud (TFRC) за предоставление нам необходимых вычислительных ресурсов. Мы также благодарим исследовательскую группу Hooshvare за содействие сбору наборов данных и соскребают онлайн -ресурсы.
Новая версия Bert v3.0 для персидского языка доступна сегодня и может справиться с неотъемлемым персонажем с нулевой шириной для персидского письма. Кроме того, модель была обучена новой мультипийской корпорации с новым набором словарного запаса.
Доступно: hooshvarelab/bert-fa-zwnj-base
Парсберт v2.0: мы реконструировали словарный запас и настраивали Парсберт V1.1 на новой персидской корпорации, чтобы предоставить некоторые функции для использования Парсберта в других областях! Объективные цели во время обучения - это ниже (после 300 тысяч шагов).
***** Eval results *****
global_step = 300000
loss = 1.4392426
masked_lm_accuracy = 0.6865794
masked_lm_loss = 1.4469004
next_sentence_accuracy = 1.0
next_sentence_loss = 6.534152e-05Доступно: hooshvarelab/bert-fa-base-precased
Парсберт V1.1: Мы продолжили обучение для более чем 2,5 млн этап на основе той же персидской корпорации и конфигурации BERT-базы. Объективные цели во время тренировки, как показано ниже (после 2,5 млн шагов).
***** Eval results *****
global_step = 2575000
loss = 1.3973521
masked_lm_accuracy = 0.70044917
masked_lm_loss = 1.3974043
next_sentence_accuracy = 0.9976562
next_sentence_loss = 0.0088804625Доступно: hooshvarelab/bert-base-parsbert-oucdessed
Парсберт V1: Это первая версия нашего Парсберта на основе BERT-BASE. Модель была обучена обширной персидской корпорации на шаги 1920000 года. Объективные цели во время обучения - это ниже (после 1,9 млн шагов).
***** Eval results *****
global_step = 1920000
loss = 2.6646128
masked_lm_accuracy = 0.583321
masked_lm_loss = 2.2517521
next_sentence_accuracy = 0.885625
next_sentence_loss = 0.3884369Доступно: hooshvarelab/bert-base-parsbert-oucdessed
Apache License 2.0


