parsbert
1.0.0
Parsbert هو نموذج لغة أحادية اللغة يعتمد على بنية Bert من Google. يتم تدريب هذا النموذج مسبقًا على الشركات الفارسية الكبيرة مع أنماط الكتابة المختلفة من العديد من الموضوعات (على سبيل المثال ، العلمية ، الروايات ، الأخبار) مع أكثر من 3.9M مستندات ، 73M جمل ، و 1.3B من الكلمات.
ورقة عرض بارسبيرت: doi: 10.1007/s11063-021-10528-4
الإصدار الحالي: V3
تدرب بارسبيرت على كمية هائلة من الشركات العامة (Wikidumps الفارسية ، Mirastext) وستة بيانات نصية أخرى يدويًا من نوع مختلف من digital magazine الويب (Bigbang Page scientific ، Chetor lifestyle ، itinerary Old general conversational novels, storybooks, short stories from old to the contemporary era ).
كجزء من منهجية Parsbert ، تم تنفيذ معالجة مسبقة واسعة النطاق تجمع بين وضع علامات POS وتجزئة WordPiece لجلب الشركة إلى تنسيق مناسب.
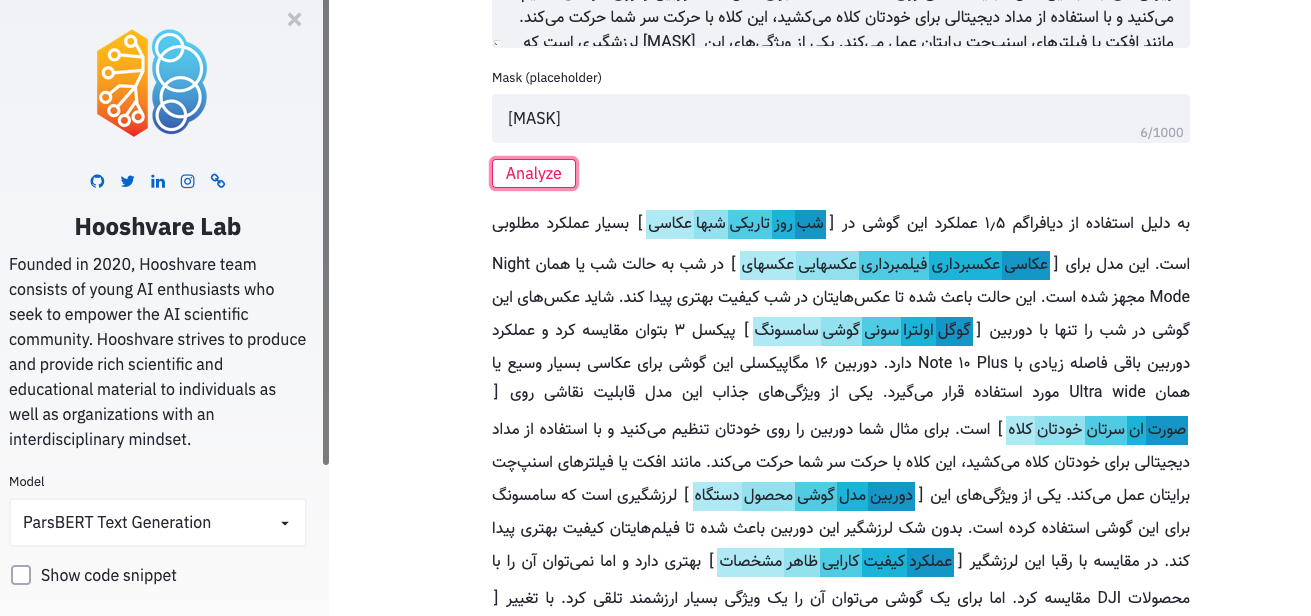
Parsbert Playground
يتم تقييم Parsbert على ثلاث مهام NLP المصب: تحليل المشاعر (SA) ، وتصنيف النص ، والتعرف على الكيان المسماة (NER). بالنسبة لهذه المسألة وبسبب عدم كفاية الموارد ، تم تأليف مجموعتين كبيرتين لتصنيف SA واثنين لتصنيف النص يدويًا ، وهما متاحان للاستخدام العام والقياس. تفوقت Parsbert على جميع نماذج اللغة الأخرى ، بما في ذلك Bert متعددة اللغات ونماذج التعلم العميق الهجينة الأخرى لجميع المهام ، مما يحسن الأداء الحديث في نمذجة اللغة الفارسية.
يلخص الجدول التالي درجة F1 التي حصل عليها Parsbert بالمقارنة مع النماذج والبنية الأخرى.
| مجموعة البيانات | بارسبيرت V3 | بارسبيرت V2 | بارسبيرت V1 | Mbert | DeepSentipers |
|---|---|---|---|---|---|
| تعليقات مستخدم Digikala | - | 81.72 | 81.74* | 80.74 | - |
| تعليقات المستخدم Snappfood | - | 87.98 | 88.12* | 87.87 | - |
| مصفّفون (فئة متعددة) | - | 71.31* | 71.11 | - | 69.33 |
| مستلزمات (فئة ثنائية) | - | 92.42* | 92.13 | - | 91.98 |
| مجموعة البيانات | بارسبيرت V3 | بارسبيرت V2 | بارسبيرت V1 | Mbert |
|---|---|---|---|---|
| مجلة Digikala | - | 93.65* | 93.59 | 90.72 |
| الأخبار الفارسية | - | 97.44* | 97.19 | 95.79 |
| مجموعة البيانات | بارسبيرت V3 | بارسبيرت V2 | بارسبيرت V1 | Mbert | morphobert | Beheshti | LSTM-CRF | CRF القائم على القواعد | BILSTM-CRF |
|---|---|---|---|---|---|---|---|---|---|
| بيما | 93.40* | 93.10 | 86.64 | - | 90.59 | - | 84.00 | - | |
| أرمان | 99.84* | 98.79 | 95.89 | 89.9 | 84.03 | 86.55 | - | 77.45 |
إذا قمت باختبار Parsbert على مجموعة بيانات عامة ، وكنت ترغب في إضافة نتائجك إلى الجدول أعلاه ، افتح طلب سحب أو اتصل بنا. تأكد أيضًا من توفر الكود الخاص بك عبر الإنترنت حتى نتمكن من إضافته كمرجع
from transformers import AutoConfig , AutoTokenizer , AutoModel , TFAutoModel
# v3.0
model_name_or_path = "HooshvareLab/bert-fa-zwnj-base"
config = AutoConfig . from_pretrained ( model_name_or_path )
tokenizer = AutoTokenizer . from_pretrained ( model_name_or_path )
# model = TFAutoModel.from_pretrained(model_name_or_path) For TF
model = AutoModel . from_pretrained ( model_name_or_path )
text = "ما در هوشواره معتقدیم با انتقال صحیح دانش و آگاهی، همه افراد میتوانند از ابزارهای هوشمند استفاده کنند. شعار ما هوش مصنوعی برای همه است."
tokenizer . tokenize ( text )
[ 'ما' , 'در' , 'هوش' , '[ZWNJ]' , 'واره' , 'معتقدیم' , 'با' , 'انتقال' , 'صحیح' , 'دانش' , 'و' , 'آ' , '##گاهی' , '،' , 'همه' , 'افراد' , 'میتوانند' , 'از' , 'ابزارهای' , 'هوشمند' , 'استفاده' , 'کنند' , '.' , 'شعار' , 'ما' , 'هوش' , 'مصنوعی' , 'برای' , 'همه' , 'است' , '.' ]| دفتر | |
|---|---|
| تصنيف النص | |
| تحليل المشاعر | |
| اسم التعرف على الكيان | |
| توليد النص |
يرجى الاستشهاد بالورقة التالية في منشورك إذا كنت تستخدم بارسبيرت في بحثك:
@article { ParsBERT ,
title = { Parsbert: Transformer-based model for Persian language understanding } ,
DOI = { 10.1007/s11063-021-10528-4 } ,
journal = { Neural Processing Letters } ,
author = { Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri } ,
year = { 2021 }
} نعبر بموجب هذا امتناننا لبرنامج TensorFlow Research Cloud (TFRC) لتزويدنا بموارد الحساب اللازمة. نشكر أيضًا مجموعة Hooshvare Research Group على تسهيل جمع مجموعات البيانات وتجنب موارد النص على الإنترنت.
يتوفر الإصدار الجديد من Bert V3.0 للفرار اليوم ويمكنه معالجة شخصية غير Joininer من خلال الكتابة الفارسية. كما تم تدريب النموذج على شركة جديدة متعددة الأنواع مع مجموعة جديدة من المفردات.
متاح بواسطة: Hooshvarelab/Bert-Fa-Zwnj-base
Parsbert v2.0: قمنا بإعادة بناء المفردات وضبطنا Parsbert v1.1 على الشركة الفارسية الجديدة من أجل توفير بعض الوظائف لاستخدام بارسبيرت في نطاقات أخرى! الأهداف الموضوعية أثناء التدريب هي كما يلي (بعد 300 ألف خطوة).
***** Eval results *****
global_step = 300000
loss = 1.4392426
masked_lm_accuracy = 0.6865794
masked_lm_loss = 1.4469004
next_sentence_accuracy = 1.0
next_sentence_loss = 6.534152e-05متاح بواسطة: Hooshvarelab/Bert-Fa-base-uncared
Parsbert v1.1: واصلنا التدريب لأكثر من 2.5 مليون خطوة استنادًا إلى نفس Corpora الفارسية وتكوين Bert-Base. الأهداف الموضوعية أثناء التدريب هي على النحو التالي (بعد 2.5 مليون خطوة).
***** Eval results *****
global_step = 2575000
loss = 1.3973521
masked_lm_accuracy = 0.70044917
masked_lm_loss = 1.3974043
next_sentence_accuracy = 0.9976562
next_sentence_loss = 0.0088804625متوفر بواسطة: Hooshvarelab/Bert-Base-Parsbert
Parsbert V1: هذا هو الإصدار الأول من Parsbert على أساس Bert-Base. تم تدريب النموذج على شركة فارسية شاسعة لخطوات 1920000. الأهداف الموضوعية أثناء التدريب هي كما يلي (بعد 1.9 مليون خطوة).
***** Eval results *****
global_step = 1920000
loss = 2.6646128
masked_lm_accuracy = 0.583321
masked_lm_loss = 2.2517521
next_sentence_accuracy = 0.885625
next_sentence_loss = 0.3884369متوفر بواسطة: Hooshvarelab/Bert-Base-Parsbert
ترخيص Apache 2.0


