parsbert
1.0.0
Parsbert เป็นรูปแบบภาษาที่มีพื้นฐานมาจากสถาปัตยกรรมเบิร์ตของ Google โมเดลนี้ได้รับการฝึกอบรมล่วงหน้าเกี่ยวกับ Corpora เปอร์เซียขนาดใหญ่ที่มีรูปแบบการเขียนที่หลากหลายจากหลาย ๆ วิชา (เช่นวิทยาศาสตร์นวนิยายข่าว) ที่มีเอกสารมากกว่า 3.9M , ประโยค 73M และคำ 1.3B
กระดาษนำเสนอ Parsbert: ดอย: 10.1007/s11063-021-10528-4
เวอร์ชันปัจจุบัน: v3
Parsbert ได้รับการฝึกฝน digital magazine กับ Corpora มหาชนจำนวนมาก (เปอร์เซีย scientific , Mirastext general conversational และอีกหกข้อมูลข้อความ itinerary คลาน lifestyle ตนเองจาก novels, storybooks, short stories from old to the contemporary era ประเภทต่างๆ
ในฐานะที่เป็นส่วนหนึ่งของวิธีการของ Parsbert ได้ทำการรวมการติดแท็ก POS และการแบ่งส่วนคำศัพท์ล่วงหน้าอย่างกว้างขวางเพื่อนำ Corpora เข้าสู่รูปแบบที่เหมาะสม
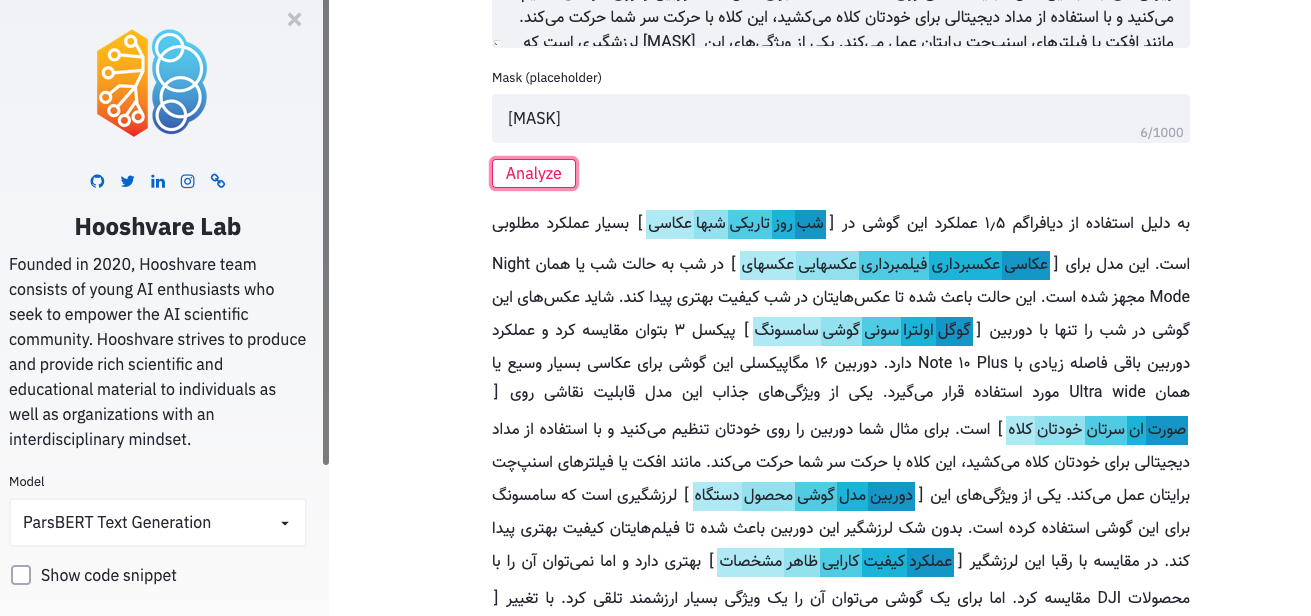
สนามเด็กเล่นพาร์สเบิร์ต
Parsbert ได้รับการประเมินในงาน NLP ดาวน์สตรีมสามงาน: การวิเคราะห์ความเชื่อมั่น (SA), การจำแนกประเภทข้อความและการจดจำเอนทิตีชื่อ (NER) สำหรับเรื่องนี้และเนื่องจากทรัพยากรที่ไม่เพียงพอชุดข้อมูลขนาดใหญ่สองชุดสำหรับ SA และสองสำหรับการจำแนกประเภทข้อความถูกแต่งด้วยตนเองซึ่งมีไว้สำหรับการใช้งานสาธารณะและการเปรียบเทียบ Parsbert มีประสิทธิภาพสูงกว่ารูปแบบภาษาอื่น ๆ ทั้งหมดรวมถึง Bert หลายภาษาและโมเดลการเรียนรู้ที่ลึกล้ำอื่น ๆ สำหรับงานทั้งหมดเพื่อปรับปรุงประสิทธิภาพที่ทันสมัยในการสร้างแบบจำลองภาษาเปอร์เซีย
ตารางต่อไปนี้สรุปคะแนน F1 ที่ได้รับจาก Parsbert เมื่อเทียบกับรุ่นและสถาปัตยกรรมอื่น ๆ
| ชุดข้อมูล | Parsbert v3 | Parsbert v2 | Parsbert v1 | Mbert | Deepsentipers |
|---|---|---|---|---|---|
| ความคิดเห็นของผู้ใช้ Digikala | - | 81.72 | 81.74* | 80.74 | - |
| ความคิดเห็นของผู้ใช้ snappfood | - | 87.98 | 88.12* | 87.87 | - |
| ศิษยาภิบาล (หลายคลาส) | - | 71.31* | 71.11 | - | 69.33 |
| ศิษย์ (คลาสไบนารี) | - | 92.42* | 92.13 | - | 91.98 |
| ชุดข้อมูล | Parsbert v3 | Parsbert v2 | Parsbert v1 | Mbert |
|---|---|---|---|---|
| นิตยสาร Digikala | - | 93.65* | 93.59 | 90.72 |
| ข่าวเปอร์เซีย | - | 97.44* | 97.19 | 95.79 |
| ชุดข้อมูล | Parsbert v3 | Parsbert v2 | Parsbert v1 | Mbert | morphobert | Beheshti-ner | LSTM-CRF | CRF ตามกฎ | bilstm-crf |
|---|---|---|---|---|---|---|---|---|---|
| คนเลี้ยงสัตว์ | 93.40* | 93.10 | 86.64 | - | 90.59 | - | 84.00 | - | |
| อาร์มาน | 99.84* | 98.79 | 95.89 | 89.9 | 84.03 | 86.55 | - | 77.45 |
หากคุณทดสอบ Parsbert ในชุดข้อมูลสาธารณะและคุณต้องการเพิ่มผลลัพธ์ของคุณลงในตารางด้านบนเปิดคำขอดึงหรือติดต่อเรา ตรวจสอบให้แน่ใจว่ามีรหัสของคุณออนไลน์เพื่อให้เราสามารถเพิ่มเป็นข้อมูลอ้างอิงได้
from transformers import AutoConfig , AutoTokenizer , AutoModel , TFAutoModel
# v3.0
model_name_or_path = "HooshvareLab/bert-fa-zwnj-base"
config = AutoConfig . from_pretrained ( model_name_or_path )
tokenizer = AutoTokenizer . from_pretrained ( model_name_or_path )
# model = TFAutoModel.from_pretrained(model_name_or_path) For TF
model = AutoModel . from_pretrained ( model_name_or_path )
text = "ما در هوشواره معتقدیم با انتقال صحیح دانش و آگاهی، همه افراد میتوانند از ابزارهای هوشمند استفاده کنند. شعار ما هوش مصنوعی برای همه است."
tokenizer . tokenize ( text )
[ 'ما' , 'در' , 'هوش' , '[ZWNJ]' , 'واره' , 'معتقدیم' , 'با' , 'انتقال' , 'صحیح' , 'دانش' , 'و' , 'آ' , '##گاهی' , '،' , 'همه' , 'افراد' , 'میتوانند' , 'از' , 'ابزارهای' , 'هوشمند' , 'استفاده' , 'کنند' , '.' , 'شعار' , 'ما' , 'هوش' , 'مصنوعی' , 'برای' , 'همه' , 'است' , '.' ]| สมุดบันทึก | |
|---|---|
| การจำแนกข้อความ | |
| การวิเคราะห์ความเชื่อมั่น | |
| การจดจำเอนทิตีชื่อ | |
| การสร้างข้อความ |
โปรดอ้างอิงบทความต่อไปนี้ในสิ่งพิมพ์ของคุณหากคุณใช้ Parsbert ในการวิจัยของคุณ:
@article { ParsBERT ,
title = { Parsbert: Transformer-based model for Persian language understanding } ,
DOI = { 10.1007/s11063-021-10528-4 } ,
journal = { Neural Processing Letters } ,
author = { Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri } ,
year = { 2021 }
} เราขอแสดงความขอบคุณต่อโปรแกรม Tensorflow Research Cloud (TFRC) สำหรับการจัดหาทรัพยากรการคำนวณที่จำเป็นให้เรา นอกจากนี้เรายังขอขอบคุณ Hooshvare Research Group สำหรับการอำนวยความสะดวกในการรวบรวมชุดข้อมูลและขูดทรัพยากรข้อความออนไลน์
Bert V3.0 เวอร์ชันใหม่สำหรับเปอร์เซียมีให้บริการในวันนี้และสามารถจัดการกับตัวละครที่ไม่ใช่ตัวละครที่ไม่มีความกว้างสำหรับการเขียนเปอร์เซีย นอกจากนี้โมเดลได้รับการฝึกฝนเกี่ยวกับ Corpora หลายประเภทใหม่ด้วยคำศัพท์ชุดใหม่
มีให้โดย: hooshvarelab/bert-fa-zwnj-base
Parsbert v2.0: เราสร้างคำศัพท์และปรับแต่ง Parsbert v1.1 บน Corpora ใหม่ของเปอร์เซียเพื่อให้ฟังก์ชั่นบางอย่างสำหรับการใช้ Parsbert ในขอบเขตอื่น ๆ ! เป้าหมายวัตถุประสงค์ระหว่างการฝึกอบรมอยู่ด้านล่าง (หลังจากขั้นตอน 300K)
***** Eval results *****
global_step = 300000
loss = 1.4392426
masked_lm_accuracy = 0.6865794
masked_lm_loss = 1.4469004
next_sentence_accuracy = 1.0
next_sentence_loss = 6.534152e-05มีให้โดย: hooshvarelab/bert-fa-base-uncased
Parsbert v1.1: เรายังคงฝึกอบรมต่อไปมากกว่า 2.5 ม. ตามขั้นตอนของ Corpora และ Bert-Base เป้าหมายวัตถุประสงค์ในระหว่างการฝึกอบรมอยู่ด้านล่าง (หลังจากขั้นตอน 2.5 ม.)
***** Eval results *****
global_step = 2575000
loss = 1.3973521
masked_lm_accuracy = 0.70044917
masked_lm_loss = 1.3974043
next_sentence_accuracy = 0.9976562
next_sentence_loss = 0.0088804625มีให้โดย: Hooshvarelab/Bert-Base-Parsbert-uncased
Parsbert v1: นี่เป็นเวอร์ชันแรกของ Parsbert ของเราตาม Bert-Base แบบจำลองได้รับการฝึกฝนเกี่ยวกับ Corpora เปอร์เซียอันกว้างใหญ่ในปี 1920000 ขั้นตอน เป้าหมายวัตถุประสงค์ระหว่างการฝึกอบรมอยู่ด้านล่าง (หลังจากขั้นตอน 1.9 ม.)
***** Eval results *****
global_step = 1920000
loss = 2.6646128
masked_lm_accuracy = 0.583321
masked_lm_loss = 2.2517521
next_sentence_accuracy = 0.885625
next_sentence_loss = 0.3884369มีให้โดย: Hooshvarelab/Bert-Base-Parsbert-uncased
ใบอนุญาต Apache 2.0


