parsbert
1.0.0
Parsbert는 Google의 Bert Architecture를 기반으로 한 단일 언어 모델입니다. 이 모델은 3.9M 이상의 문서, 73M 문장 및 1.3B 단어를 가진 수많은 주제 (예 : 과학, 소설, 뉴스)의 다양한 작문 스타일을 가진 대형 페르시아 코퍼라에서 미리 훈련됩니다.
Parsbert : DOI : 10.1007/S11063-021-10528-4를 참조하십시오
현재 버전 : v3
Parsbert는 다양한 유형의 웹 사이트 (Bigbang Page scientific , Chetor lifestyle , itinerary , Digikala digital magazine , Ted Talks general conversational , Books Novels, novels, storybooks, short stories from old to the contemporary era 훈련 시켰습니다.
Parsbert 방법론의 일환으로, POS 태깅과 워드 피스 세분화를 결합한 광범위한 사전 프로세싱을 수행하여 Corpora를 적절한 형식으로 이끌었습니다.
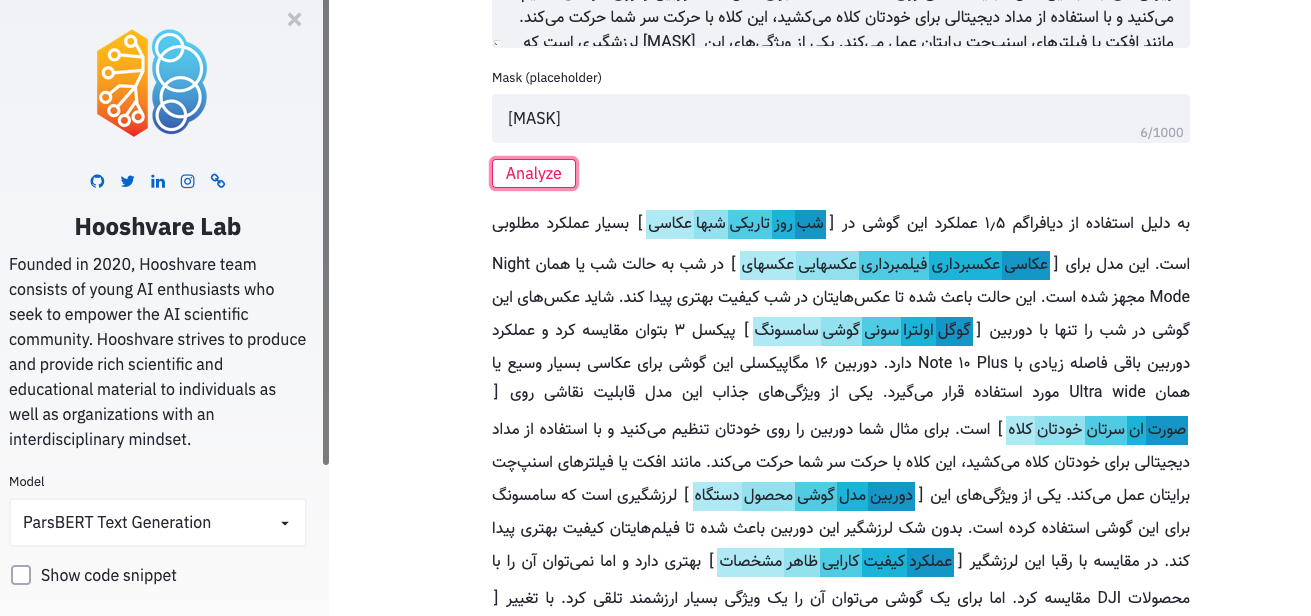
파스버트 놀이터
Parsbert는 감정 분석 (SA), 텍스트 분류 및 명명 된 엔티티 인식 (NER)의 세 가지 NLP 다운 스트림 작업에 대해 평가됩니다. 이 문제와 자원이 불충분하기 때문에 SA를위한 2 개의 큰 데이터 세트와 텍스트 분류 용 2 개가 수동으로 구성되어 공개 사용 및 벤치마킹이 가능합니다. Parsbert는 다국어 버트 및 모든 작업에 대한 기타 하이브리드 딥 러닝 모델을 포함한 다른 모든 언어 모델을 능가하여 페르시아어 모델링의 최첨단 성능을 향상 시켰습니다.
다음 표는 다른 모델 및 아키텍처와 비교하여 Parsbert가 얻은 F1 점수를 요약합니다.
| 데이터 세트 | 파스버트 V3 | 파스버트 V2 | 파스버트 v1 | Mbert | 심해 |
|---|---|---|---|---|---|
| Digikala 사용자 댓글 | - | 81.72 | 81.74* | 80.74 | - |
| snappfood 사용자 댓글 | - | 87.98 | 88.12* | 87.87 | - |
| 추방자 (다중 클래스) | - | 71.31* | 71.11 | - | 69.33 |
| 추방자 (이진 클래스) | - | 92.42* | 92.13 | - | 91.98 |
| 데이터 세트 | 파스버트 V3 | 파스버트 V2 | 파스버트 v1 | Mbert |
|---|---|---|---|---|
| Digikala 잡지 | - | 93.65* | 93.59 | 90.72 |
| 페르시아 뉴스 | - | 97.44* | 97.19 | 95.79 |
| 데이터 세트 | 파스버트 V3 | 파스버트 V2 | 파스버트 v1 | Mbert | Morphobert | Beheshti-ren | LSTM-CRF | 규칙 기반 CRF | Bilstm-Crf |
|---|---|---|---|---|---|---|---|---|---|
| PEYMA | 93.40* | 93.10 | 86.64 | - | 90.59 | - | 84.00 | - | |
| 아르맨 | 99.84* | 98.79 | 95.89 | 89.9 | 84.03 | 86.55 | - | 77.45 |
공개 데이터 세트에서 Parsbert를 테스트하고 위의 표에 결과를 추가하려면 풀 요청을 열거나 문의하십시오. 또한 참조로 추가 할 수 있도록 온라인으로 코드를 사용할 수 있도록하십시오.
from transformers import AutoConfig , AutoTokenizer , AutoModel , TFAutoModel
# v3.0
model_name_or_path = "HooshvareLab/bert-fa-zwnj-base"
config = AutoConfig . from_pretrained ( model_name_or_path )
tokenizer = AutoTokenizer . from_pretrained ( model_name_or_path )
# model = TFAutoModel.from_pretrained(model_name_or_path) For TF
model = AutoModel . from_pretrained ( model_name_or_path )
text = "ما در هوشواره معتقدیم با انتقال صحیح دانش و آگاهی، همه افراد میتوانند از ابزارهای هوشمند استفاده کنند. شعار ما هوش مصنوعی برای همه است."
tokenizer . tokenize ( text )
[ 'ما' , 'در' , 'هوش' , '[ZWNJ]' , 'واره' , 'معتقدیم' , 'با' , 'انتقال' , 'صحیح' , 'دانش' , 'و' , 'آ' , '##گاهی' , '،' , 'همه' , 'افراد' , 'میتوانند' , 'از' , 'ابزارهای' , 'هوشمند' , 'استفاده' , 'کنند' , '.' , 'شعار' , 'ما' , 'هوش' , 'مصنوعی' , 'برای' , 'همه' , 'است' , '.' ]| 공책 | |
|---|---|
| 텍스트 분류 | |
| 감정 분석 | |
| 지명 된 엔티티 인식 | |
| 텍스트 생성 |
연구에서 Parsbert를 사용하는 경우 발행물에서 다음 논문을 인용하십시오.
@article { ParsBERT ,
title = { Parsbert: Transformer-based model for Persian language understanding } ,
DOI = { 10.1007/s11063-021-10528-4 } ,
journal = { Neural Processing Letters } ,
author = { Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri } ,
year = { 2021 }
} 우리는 필요한 계산 리소스를 제공하기 위해 TFRC (Tensorflow Research Cloud) 프로그램에 감사를 표합니다. 또한 데이터 세트 수집을 촉진하고 온라인 텍스트 리소스를 긁어 낸 Hooshvare Research Group에 감사드립니다.
페르시아어 용 Bert v3.0의 새로운 버전은 오늘날 이용할 수 있으며 페르시아어 작문을위한 제로 폭이 아닌 비 조명 캐릭터를 다룰 수 있습니다. 또한이 모델은 새로운 어휘 세트로 새로운 다형 Corpora에 대한 교육을 받았습니다.
이용 가능 : Hooshvarelab/Bert-Fa-Zwnj-Base
Parsbert v2.0 : 우리는 다른 범위에서 Parsbert를 사용하기위한 몇 가지 기능을 제공하기 위해 새로운 페르시아 코퍼라의 파스버트 v1.1을 미세 조정했습니다! 훈련 중 객관적인 목표는 다음과 같습니다 (300K 단계 후).
***** Eval results *****
global_step = 300000
loss = 1.4392426
masked_lm_accuracy = 0.6865794
masked_lm_loss = 1.4469004
next_sentence_accuracy = 1.0
next_sentence_loss = 6.534152e-05이용 가능 : Hooshvarelab/Bert-Fa-Base-uncased
Parsbert v1.1 : 우리는 동일한 페르시아 코포라 및 버트베이스 구성을 기반으로 2.5m 이상의 단계에 대한 교육을 계속했습니다. 훈련 중 객관적인 목표는 다음과 같습니다 (2.5m 단계 후).
***** Eval results *****
global_step = 2575000
loss = 1.3973521
masked_lm_accuracy = 0.70044917
masked_lm_loss = 1.3974043
next_sentence_accuracy = 0.9976562
next_sentence_loss = 0.0088804625이용 가능 : Hooshvarelab/Bert-Base-Parsbert-incased
Parsbert V1 : 이것은 Bert-Base를 기반으로 한 Parsbert의 첫 번째 버전입니다. 이 모델은 1920000 년 단계 동안 Vast Persian Corpora에 대한 교육을 받았습니다. 훈련 중 객관적인 목표는 다음과 같습니다 (1.9m 단계 후).
***** Eval results *****
global_step = 1920000
loss = 2.6646128
masked_lm_accuracy = 0.583321
masked_lm_loss = 2.2517521
next_sentence_accuracy = 0.885625
next_sentence_loss = 0.3884369이용 가능 : Hooshvarelab/Bert-Base-Parsbert-incased
아파치 라이센스 2.0


