parsbert
1.0.0
Parsbert est un modèle de langage monolingue basé sur l'architecture Bert de Google. Ce modèle est pré-formé sur les grandes corpus persans avec divers styles d'écriture de nombreux sujets (par exemple, scientifiques, romans, nouvelles) avec plus de 3.9M de documents, 73M de phrases et 1.3B .
Document présentant Parsbert: doi: 10.1007 / s11063-021-10528-4
Version actuelle: V3
Parsbert formé sur une quantité massive de corpus publics (wikidumps persan, Mirastext) et six autres données textuelles rampantes manuellement à partir d'un type de sites Web divers (Bigbang Page scientific , Chetor lifestyle , Eligasht itinerary , Digikala digital magazine , Ted Talks general conversational , Livres novels, storybooks, short stories from old to the contemporary era ).
Dans le cadre de la méthodologie de Parsbert, une vaste prétraitement combinant le marquage POS et la segmentation de la pièce de bouge a été réalisée pour amener les corpus dans un format approprié.
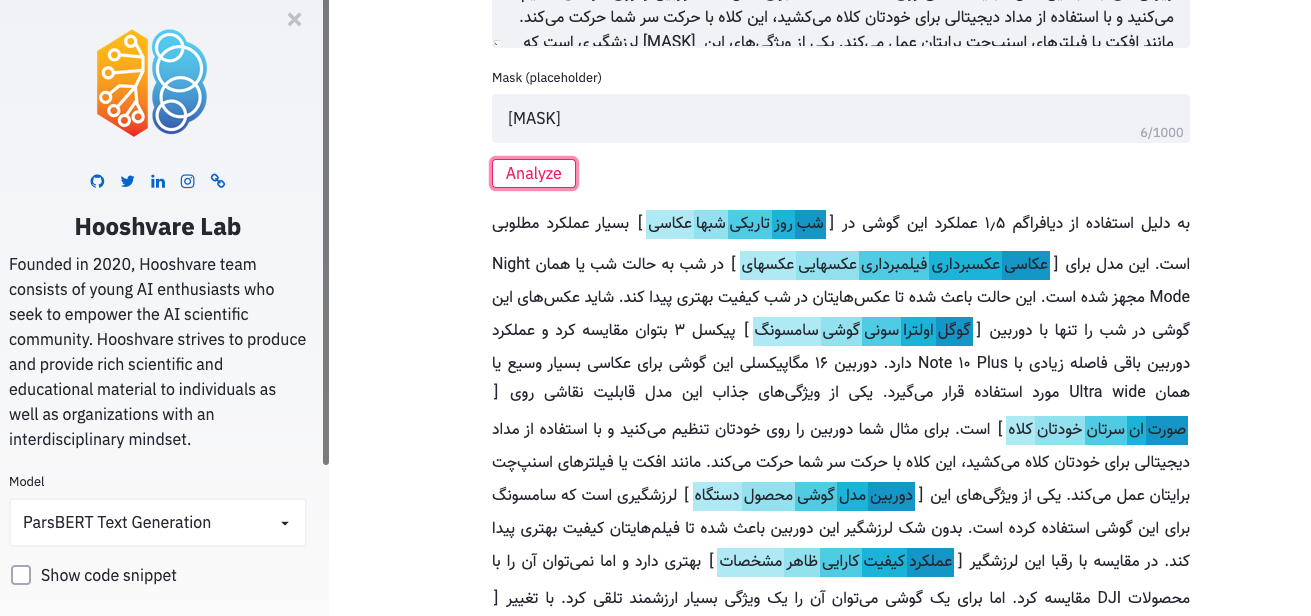
Terrain de jeu de Parsbert
Parsbert est évalué sur trois tâches NLP en aval: l'analyse des sentiments (SA), la classification du texte et la reconnaissance de l'entité nommée (NER). Pour cette affaire et en raison de ressources insuffisantes, deux grands ensembles de données pour SA et deux pour la classification du texte ont été composés manuellement, qui sont disponibles pour un usage public et l'analyse comparative. Parsbert a surpassé tous les autres modèles de langues, y compris le multilingue Bert et d'autres modèles d'hybride en profondeur pour toutes les tâches, améliorant les performances de pointe dans la modélisation de la langue persane.
Le tableau suivant résume le score F1 obtenu par Parsbert par rapport à d'autres modèles et architectures.
| Ensemble de données | Parsbert V3 | Parsbert V2 | Parsbert V1 | Mbert | Profondément |
|---|---|---|---|---|---|
| Commentaires de l'utilisateur Digikala | - | 81.72 | 81.74 * | 80.74 | - |
| Commentaires de l'utilisateur SnappFood | - | 87,98 | 88.12 * | 87.87 | - |
| Senicateurs (multi-classes) | - | 71.31 * | 71.11 | - | 69.33 |
| Sentiveurs (classe binaire) | - | 92.42 * | 92.13 | - | 91.98 |
| Ensemble de données | Parsbert V3 | Parsbert V2 | Parsbert V1 | Mbert |
|---|---|---|---|---|
| Magazine Digikala | - | 93.65 * | 93.59 | 90,72 |
| Nouvelles persanes | - | 97.44 * | 97.19 | 95,79 |
| Ensemble de données | Parsbert V3 | Parsbert V2 | Parsbert V1 | Mbert | Morphobert | Beheshti-net | LSTM-CRF | CRF basé sur des règles | Bilstm-crf |
|---|---|---|---|---|---|---|---|---|---|
| Peyma | 93.40 * | 93.10 | 86.64 | - | 90,59 | - | 84.00 | - | |
| Arman | 99.84 * | 98.79 | 95.89 | 89.9 | 84.03 | 86,55 | - | 77.45 |
Si vous avez testé Parsbert sur un ensemble de données public et que vous souhaitez ajouter vos résultats au tableau ci-dessus, ouvrez une demande de traction ou contactez-nous. Assurez-vous également que votre code soit disponible en ligne afin que nous puissions l'ajouter en tant que référence
from transformers import AutoConfig , AutoTokenizer , AutoModel , TFAutoModel
# v3.0
model_name_or_path = "HooshvareLab/bert-fa-zwnj-base"
config = AutoConfig . from_pretrained ( model_name_or_path )
tokenizer = AutoTokenizer . from_pretrained ( model_name_or_path )
# model = TFAutoModel.from_pretrained(model_name_or_path) For TF
model = AutoModel . from_pretrained ( model_name_or_path )
text = "ما در هوشواره معتقدیم با انتقال صحیح دانش و آگاهی، همه افراد میتوانند از ابزارهای هوشمند استفاده کنند. شعار ما هوش مصنوعی برای همه است."
tokenizer . tokenize ( text )
[ 'ما' , 'در' , 'هوش' , '[ZWNJ]' , 'واره' , 'معتقدیم' , 'با' , 'انتقال' , 'صحیح' , 'دانش' , 'و' , 'آ' , '##گاهی' , '،' , 'همه' , 'افراد' , 'میتوانند' , 'از' , 'ابزارهای' , 'هوشمند' , 'استفاده' , 'کنند' , '.' , 'شعار' , 'ما' , 'هوش' , 'مصنوعی' , 'برای' , 'همه' , 'است' , '.' ]| Carnet de notes | |
|---|---|
| Classification de texte | |
| Analyse des sentiments | |
| Reconnaissance d'entité nommée | |
| Génération de texte |
Veuillez citer l'article suivant dans votre publication si vous utilisez Parsbert dans votre recherche:
@article { ParsBERT ,
title = { Parsbert: Transformer-based model for Persian language understanding } ,
DOI = { 10.1007/s11063-021-10528-4 } ,
journal = { Neural Processing Letters } ,
author = { Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri } ,
year = { 2021 }
} Nous exprimons par la présente notre gratitude au programme Tensorflow Research Cloud (TFRC) pour nous fournir les ressources de calcul nécessaires. Nous remercions également Hooshvare Research Group d'avoir facilité la collecte de données et de gratter les ressources de texte en ligne.
La nouvelle version de Bert V3.0 pour le Perse est disponible aujourd'hui et peut s'attaquer au personnage non-junior zéro largeur pour l'écriture persane. En outre, le modèle a été formé sur de nouveaux corpus multi-types avec un nouvel ensemble de vocabulaire.
Disponible par: HooshvareLab / Bert-Fa-Zwnj-Base
Parsbert V2.0: Nous avons reconstruit le vocabulaire et affiné le Parsbert V1.1 sur les nouvelles corpus persans afin de fournir des fonctionnalités pour utiliser Parsbert dans d'autres lunettes! Les buts objectifs pendant la formation sont comme ci-dessous (après 300 000 étapes).
***** Eval results *****
global_step = 300000
loss = 1.4392426
masked_lm_accuracy = 0.6865794
masked_lm_loss = 1.4469004
next_sentence_accuracy = 1.0
next_sentence_loss = 6.534152e-05Disponible par: HooshvareLab / Bert-Fa-Base-Snoyled
Parsbert V1.1: Nous avons poursuivi la formation de plus de 2,5 m d'étapes basées sur les mêmes corpus persans et configuration de base Bert. Les buts objectifs pendant la formation sont comme ci-dessous (après 2,5 millions d'étapes).
***** Eval results *****
global_step = 2575000
loss = 1.3973521
masked_lm_accuracy = 0.70044917
masked_lm_loss = 1.3974043
next_sentence_accuracy = 0.9976562
next_sentence_loss = 0.0088804625Disponible par: HooshvareLab / Bert-Base-Parsbert-Orle dans
Parsbert V1: Ceci est la première version de notre Parsbert basé sur Bert-Base. Le modèle a été formé sur de vastes corpus persans pour les étapes de 1920000. Les buts objectifs pendant la formation sont comme ci-dessous (après 1,9 million d'étapes).
***** Eval results *****
global_step = 1920000
loss = 2.6646128
masked_lm_accuracy = 0.583321
masked_lm_loss = 2.2517521
next_sentence_accuracy = 0.885625
next_sentence_loss = 0.3884369Disponible par: HooshvareLab / Bert-Base-Parsbert-Orle dans
Licence Apache 2.0


