parsbert
1.0.0
Parsbert ist ein einsprachiges Sprachmodell, das auf der Bert -Architektur von Google basiert. Dieses Modell ist auf große persische Korpora mit verschiedenen Schreibstilen aus zahlreichen Fächern (z. B. wissenschaftlich, Romanen, Nachrichten) mit mehr als 3.9M Dokumenten, 73M -Sätzen und 1.3B Wörtern ausgebildet.
Papier präsentieren Parsbert: doi: 10.1007/s11063-021-10528-4
Aktuelle Version: v3
ParsBERT trained on a massive amount of public corpora (Persian Wikidumps, MirasText) and six other manually crawled text data from a various type of websites (BigBang Page scientific , Chetor lifestyle , Eligasht itinerary , Digikala digital magazine , Ted Talks general conversational , Books novels, storybooks, short stories from old to the contemporary era ).
Als Teil der Parsbert-Methodik wurde eine umfassende Vorverarbeitung, bei der POS-Tagging und Wortstückssegmentierung kombiniert werden, um die Korpora in ein ordnungsgemäßes Format zu bringen.
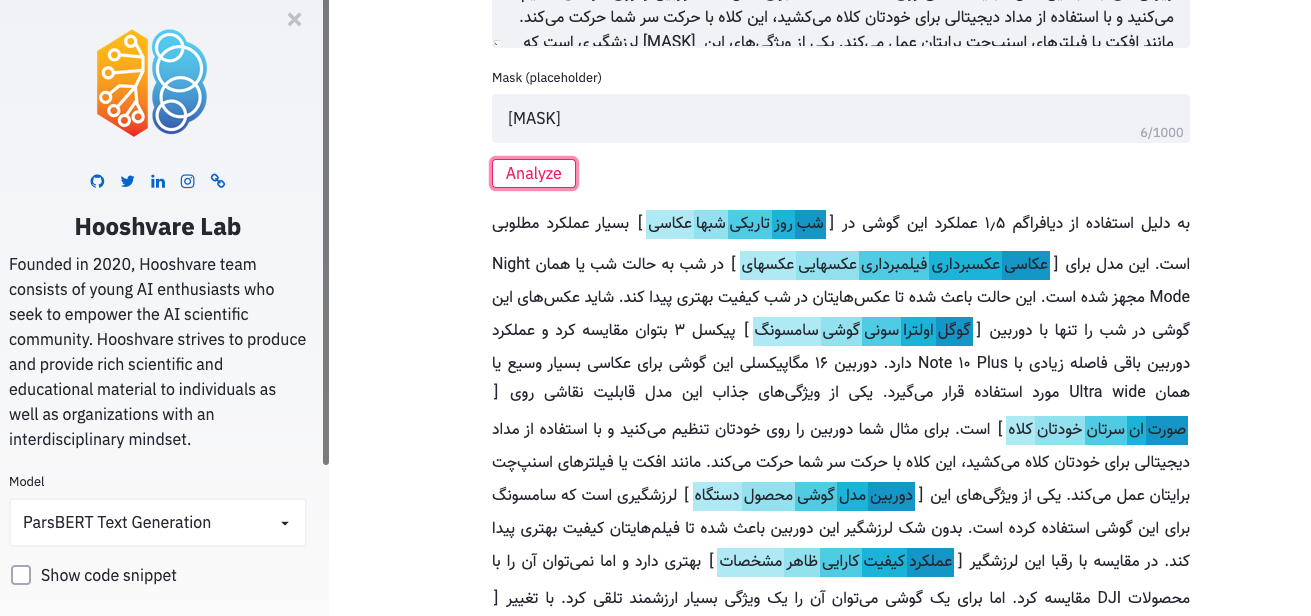
Parsbert -Spielplatz
Parsbert wird an drei NLP -Downstream -Aufgaben bewertet: Sentiment Analysis (SA), Textklassifizierung und Namen der Entitätserkennung (NER). Zu dieser Angelegenheit und aufgrund unzureichender Ressourcen wurden zwei große Datensätze für SA und zwei für die Textklassifizierung manuell komponiert, die für die öffentliche Nutzung und das Benchmarking zur Verfügung stehen. Parsbert übertraf alle anderen Sprachmodelle, darunter mehrsprachige Bert und andere hybride Deep-Learning-Modelle für alle Aufgaben, wodurch die hochmoderne Leistung in der Persischen Sprachmodellierung verbessert wurde.
Die folgende Tabelle fasst den von Parsbert erhaltenen F1 -Score im Vergleich zu anderen Modellen und Architekturen zusammen.
| Datensatz | Parsbert V3 | Parsbert V2 | Parsbert V1 | Mbert | DeepSentipers |
|---|---|---|---|---|---|
| Digikala -Benutzerkommentare | - - | 81.72 | 81.74* | 80.74 | - - |
| Snappfood -Benutzerkommentare | - - | 87,98 | 88.12* | 87.87 | - - |
| Sentipers (Multi -Klasse) | - - | 71.31* | 71.11 | - - | 69.33 |
| Sentipers (Binärklasse) | - - | 92.42* | 92.13 | - - | 91.98 |
| Datensatz | Parsbert V3 | Parsbert V2 | Parsbert V1 | Mbert |
|---|---|---|---|---|
| Digikala Magazine | - - | 93.65* | 93.59 | 90.72 |
| Persische Nachrichten | - - | 97.44* | 97.19 | 95.79 |
| Datensatz | Parsbert V3 | Parsbert V2 | Parsbert V1 | Mbert | Morphobert | Beheshti-ner | Lstm-crf | Regelbasiertes CRF | Bilstm-crf |
|---|---|---|---|---|---|---|---|---|---|
| Peyma | 93.40* | 93.10 | 86.64 | - - | 90.59 | - - | 84.00 | - - | |
| Arman | 99.84* | 98.79 | 95.89 | 89,9 | 84.03 | 86,55 | - - | 77,45 |
Wenn Sie Parsbert auf einem öffentlichen Datensatz getestet haben und Ihre Ergebnisse in der obigen Tabelle hinzufügen möchten, öffnen Sie eine Pull -Anfrage oder kontaktieren Sie uns. Stellen Sie außerdem sicher, dass Ihr Code online verfügbar ist, damit wir ihn als Referenz hinzufügen können
from transformers import AutoConfig , AutoTokenizer , AutoModel , TFAutoModel
# v3.0
model_name_or_path = "HooshvareLab/bert-fa-zwnj-base"
config = AutoConfig . from_pretrained ( model_name_or_path )
tokenizer = AutoTokenizer . from_pretrained ( model_name_or_path )
# model = TFAutoModel.from_pretrained(model_name_or_path) For TF
model = AutoModel . from_pretrained ( model_name_or_path )
text = "ما در هوشواره معتقدیم با انتقال صحیح دانش و آگاهی، همه افراد میتوانند از ابزارهای هوشمند استفاده کنند. شعار ما هوش مصنوعی برای همه است."
tokenizer . tokenize ( text )
[ 'ما' , 'در' , 'هوش' , '[ZWNJ]' , 'واره' , 'معتقدیم' , 'با' , 'انتقال' , 'صحیح' , 'دانش' , 'و' , 'آ' , '##گاهی' , '،' , 'همه' , 'افراد' , 'میتوانند' , 'از' , 'ابزارهای' , 'هوشمند' , 'استفاده' , 'کنند' , '.' , 'شعار' , 'ما' , 'هوش' , 'مصنوعی' , 'برای' , 'همه' , 'است' , '.' ]| Notizbuch | |
|---|---|
| Textklassifizierung | |
| Stimmungsanalyse | |
| Genannte Entitätserkennung | |
| Textgenerierung |
Bitte zitieren Sie das folgende Papier in Ihrer Veröffentlichung, wenn Sie Parsbert in Ihrer Forschung verwenden:
@article { ParsBERT ,
title = { Parsbert: Transformer-based model for Persian language understanding } ,
DOI = { 10.1007/s11063-021-10528-4 } ,
journal = { Neural Processing Letters } ,
author = { Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri } ,
year = { 2021 }
} Hiermit bedanken wir uns beim TFRC -Programm (TensorFlow Research Cloud) für die Bereitstellung der erforderlichen Rechenressourcen. Wir danken auch die Hooshvare Research Group für die Erleichterung des Datensatzes und das Abkratzen von Online -Textressourcen.
Die neue Version von Bert V3.0 für Persisch ist heute verfügbar und kann den Null-Width-Nicht-Joiner-Charakter für das persische Schreiben in Angriff nehmen. Außerdem wurde das Modell auf neuen Multi-Typen mit einem neuen Satz Vokabular ausgebildet.
Verfügbar von: Hooshvarelab/Bert-Fa-Zwnj-Base
Parsbert V2.0: Wir haben den Wortschatz rekonstruiert und den Parsbert V1.1 auf der neuen persischen Korpora abgestimmt, um einige Funktionen für die Verwendung von Parsbert in anderen Reichweiten bereitzustellen! Die objektiven Ziele während des Trainings finden Sie unten (nach 300.000 Schritten).
***** Eval results *****
global_step = 300000
loss = 1.4392426
masked_lm_accuracy = 0.6865794
masked_lm_loss = 1.4469004
next_sentence_accuracy = 1.0
next_sentence_loss = 6.534152e-05Erhältlich von: Hooshvarelab/Bert-Fa-Base-Unbekannter
Parsbert V1.1: Wir haben das Training für mehr als 2,5 m auf derselben persischen Korpora- und Bert-Base-Konfiguration fortgesetzt. Die objektiven Ziele während des Trainings finden Sie unten (nach 2,5 -m -Schritten).
***** Eval results *****
global_step = 2575000
loss = 1.3973521
masked_lm_accuracy = 0.70044917
masked_lm_loss = 1.3974043
next_sentence_accuracy = 0.9976562
next_sentence_loss = 0.0088804625Erhältlich von: Hooshvarelab/Bert-Base-Parsbert-Unbekannter
Parsbert V1: Dies ist die erste Version unseres Parsbert, die auf Bert-Base basiert. Das Modell wurde für 1920000 Stufen auf weite persische Korpora geschult. Die objektiven Ziele während des Trainings finden Sie unten (nach 1,9 -m -Schritten).
***** Eval results *****
global_step = 1920000
loss = 2.6646128
masked_lm_accuracy = 0.583321
masked_lm_loss = 2.2517521
next_sentence_accuracy = 0.885625
next_sentence_loss = 0.3884369Erhältlich von: Hooshvarelab/Bert-Base-Parsbert-Unbekannter
Apache -Lizenz 2.0


