sequence labeling BiLSTM CRF
1.0.0
Bilstm+CRF模型的张量实现,用于序列标记任务。
Sequential labeling是一种典型的方法,建模NLP中的序列预测任务。常见的顺序标记任务包括,例如,
以命名实体识别(NER)任务为示例:
Stanford University located at California .
B-ORG I-ORG O O B-LOC O在这里,将提取两个实体, Stanford University和California 。具体而言,文本中的每个token都用相应的label标记。例如,{ token :斯坦福大学, label : b-org }。给定令牌序列,序列标记模型旨在预测标签序列。
Lample等人提出的BiLSTM+CRF ,2016年,是迄今为止用于顺序标记任务的最古典和稳定的神经模型。 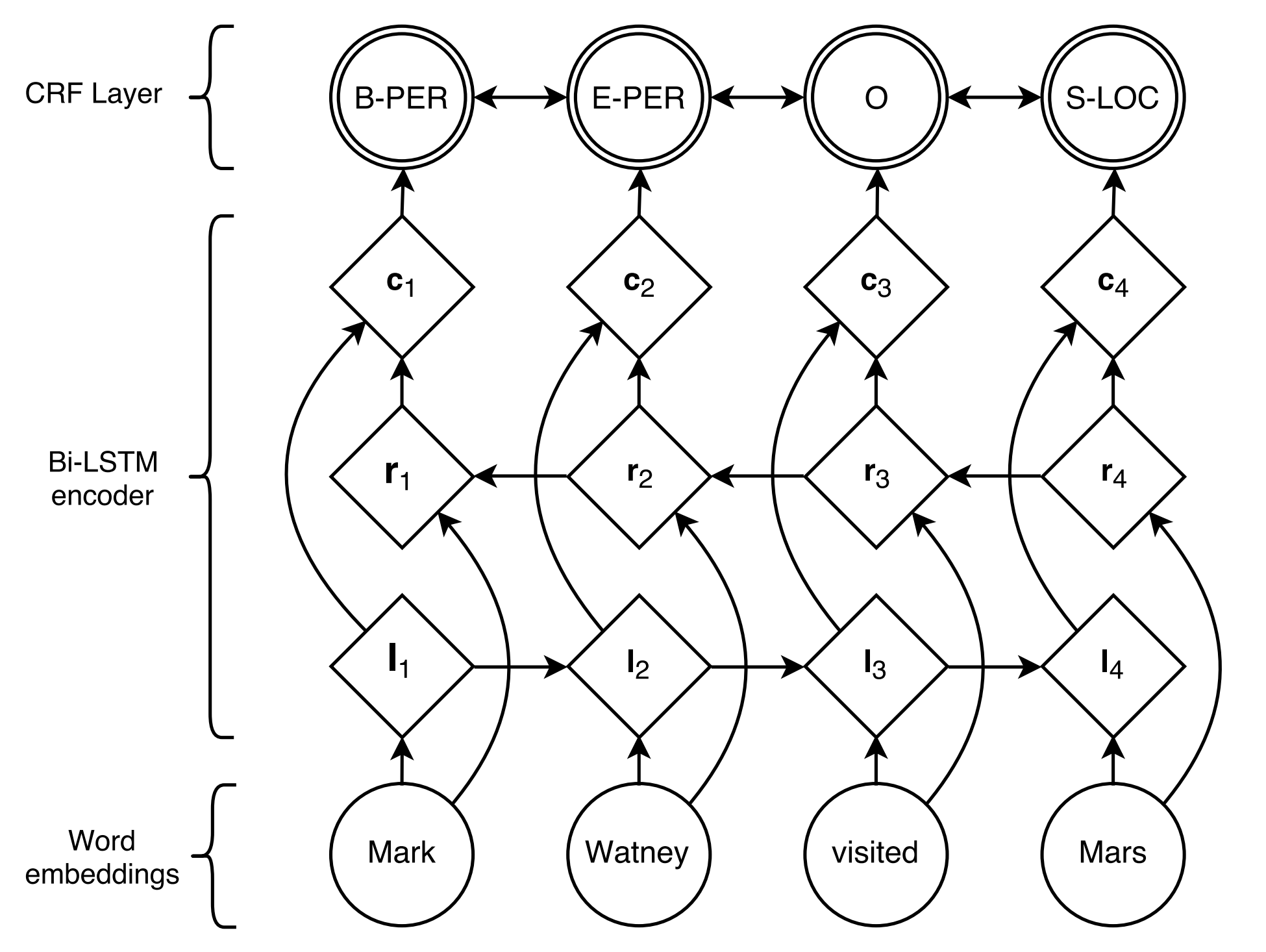
配置所有设置
train / test / interactive_predict / api_service ]BIO / BIESO ]PER | LOC | ORG ]记录所有内容
Web App Demo可轻松演示
面向对象:bilstm_crf,数据集,configer,utils
用清晰的结构模块化,易于DIY。
在手册中查看更多。
下载仓库直接使用。
git clone https://github.com/scofield7419/sequence-labeling-BiLSTM-CRF.git
pip install -r requirements.txt
将Bilstm-CRF软件包作为模块安装。
pip install BiLSTM-CRF
用法:
from BiLSTM-CRF.engines.BiLSTM_CRFs import BiLSTM_CRFs as BC
from BiLSTM-CRF.engines.DataManager import DataManager
from BiLSTM-CRF.engines.Configer import Configer
from BiLSTM-CRF.engines.utils import get_logger
...
config_file = r'/home/projects/system.config'
configs = Configer(config_file)
logger = get_logger(configs.log_dir)
configs.show_data_summary(logger) # optional
dataManager = DataManager(configs, logger)
model = BC(configs, logger, dataManager)
###### mode == 'train':
model.train()
###### mode == 'test':
model.test()
###### mode == 'single predicting':
sentence_tokens, entities, entities_type, entities_index = model.predict_single(sentence)
if configs.label_level == 1:
print("nExtracted entities:n %snn" % ("n".join(entities)))
elif configs.label_level == 2:
print("nExtracted entities:n %snn" % ("n".join([a + "t(%s)" % b for a, b in zip(entities, entities_type)])))
###### mode == 'api service webapp':
cmd_new = r'cd demo_webapp; python manage.py runserver %s:%s' % (configs.ip, configs.port)
res = os.system(cmd_new)
open `ip:port` in your browser.
├── main.py
├── system.config
├── HandBook.md
├── README.md
│
├── checkpoints
│ ├── BILSTM-CRFs-datasets1
│ │ ├── checkpoint
│ │ └── ...
│ └── ...
├── data
│ ├── example_datasets1
│ │ ├── logs
│ │ ├── vocabs
│ │ ├── test.csv
│ │ ├── train.csv
│ │ └── dev.csv
│ └── ...
├── demo_webapp
│ ├── demo_webapp
│ ├── interface
│ └── manage.py
├── engines
│ ├── BiLSTM_CRFs.py
│ ├── Configer.py
│ ├── DataManager.py
│ └── utils.py
└── tools
├── calcu_measure_testout.py
└── statis.py
折叠
engines折叠中,提供核心功能PY。data-subfold折叠中,放置了数据集。checkpoints-subfold折叠中,存储模型检查点。demo_webapp折叠中,我们可以在Web中演示系统,并提供API。tools折叠中,提供了一些离线效应。文件
main.py是系统的输入python文件。system.config是所有系统设置的配置文件。HandBook.md提供了一些用法说明。BiLSTM_CRFs.py是主要模型。Configer.py解析system.config 。DataManager.py管理数据集和调度。utils.py在飞行工具上提供。 在以下步骤下:
system.config中编写您的配置文件。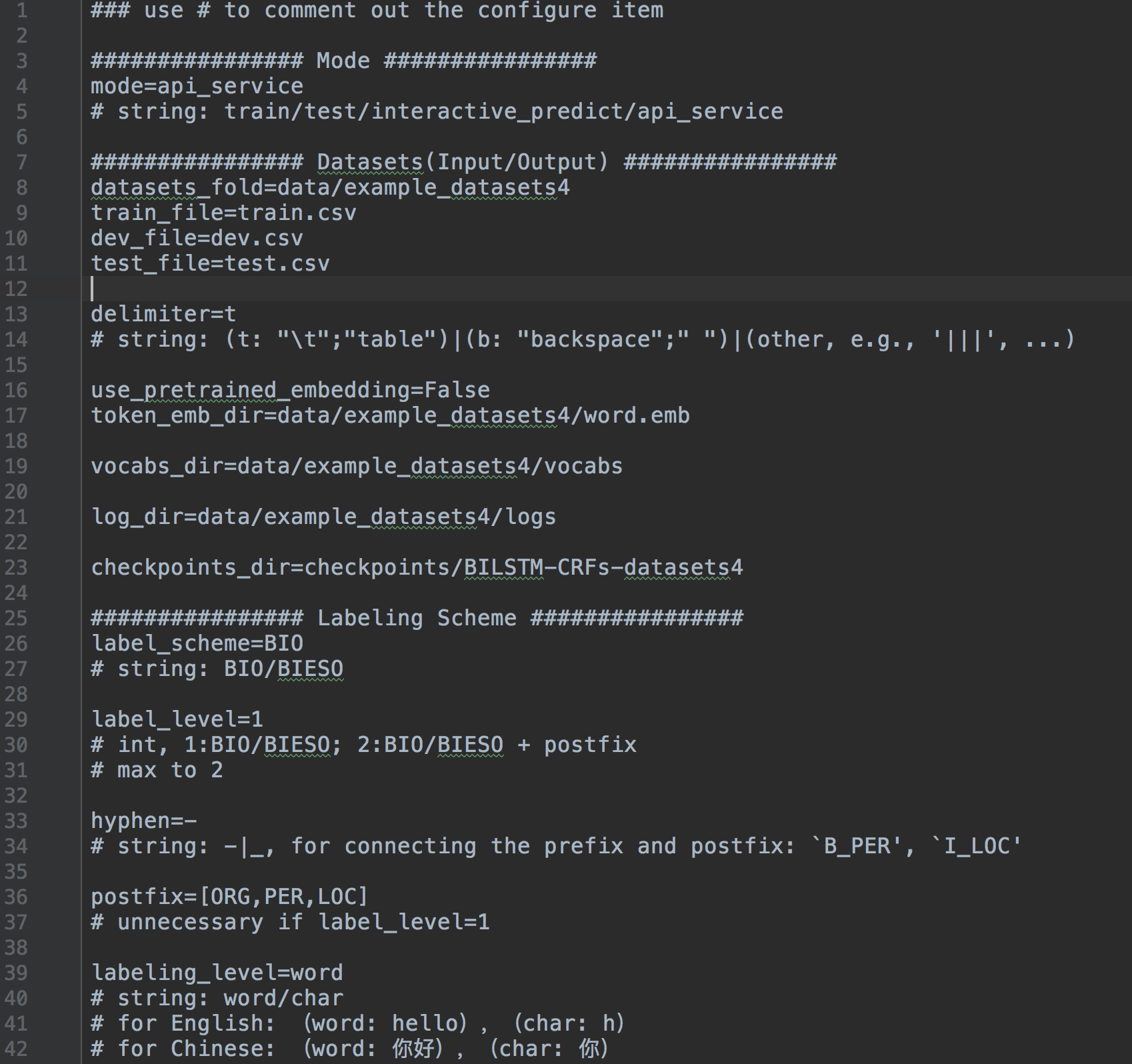
main.py 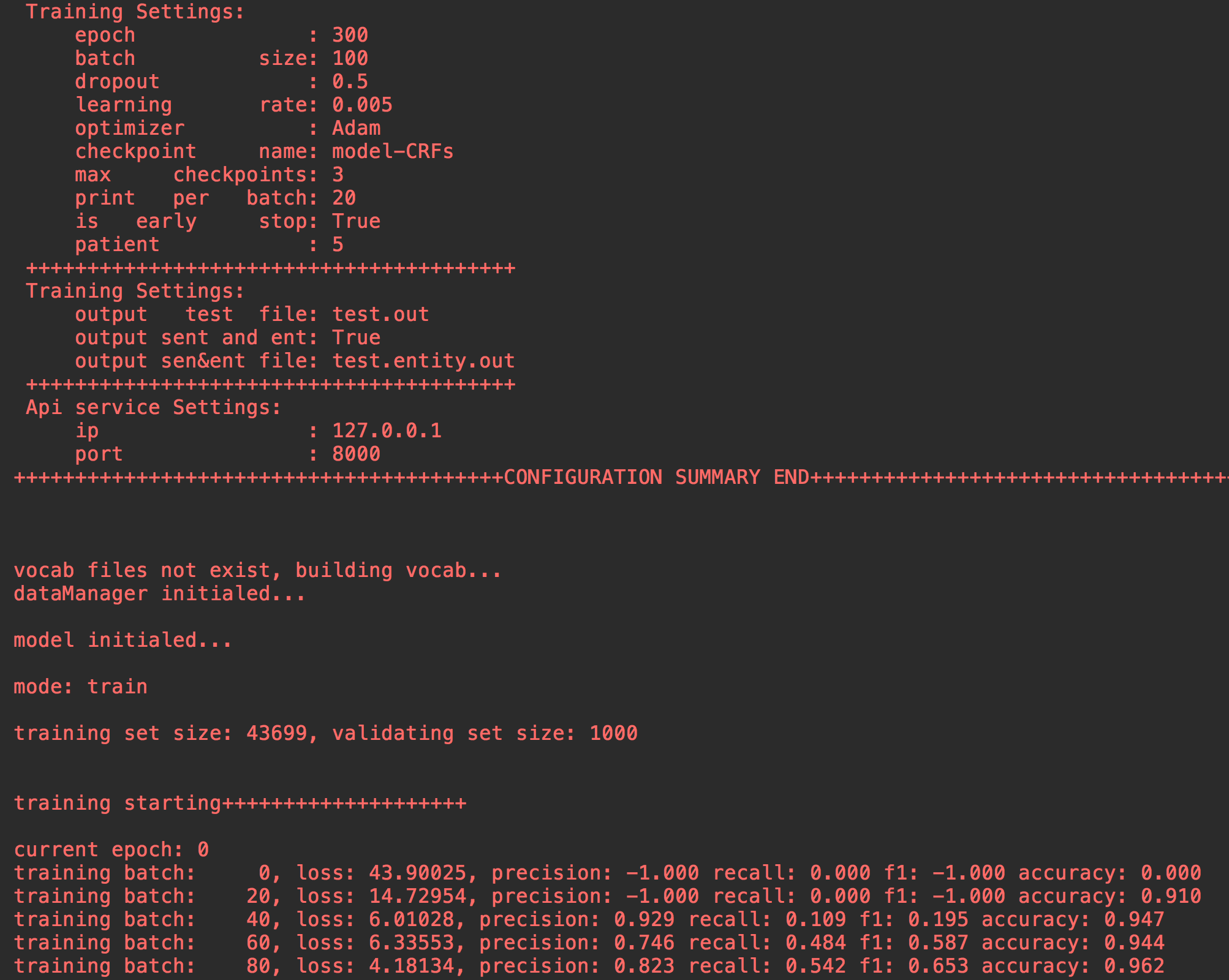
main.py main.py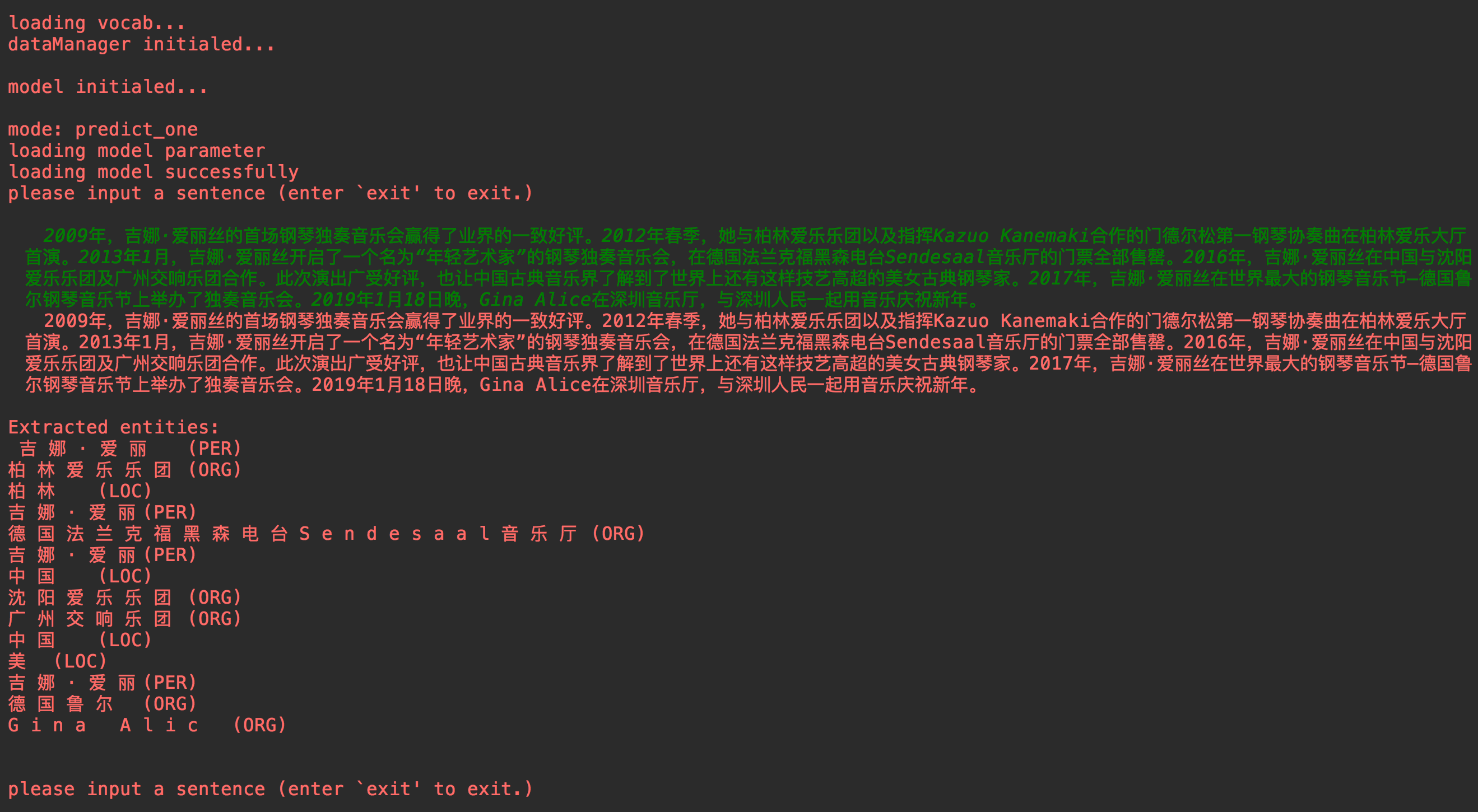
main.py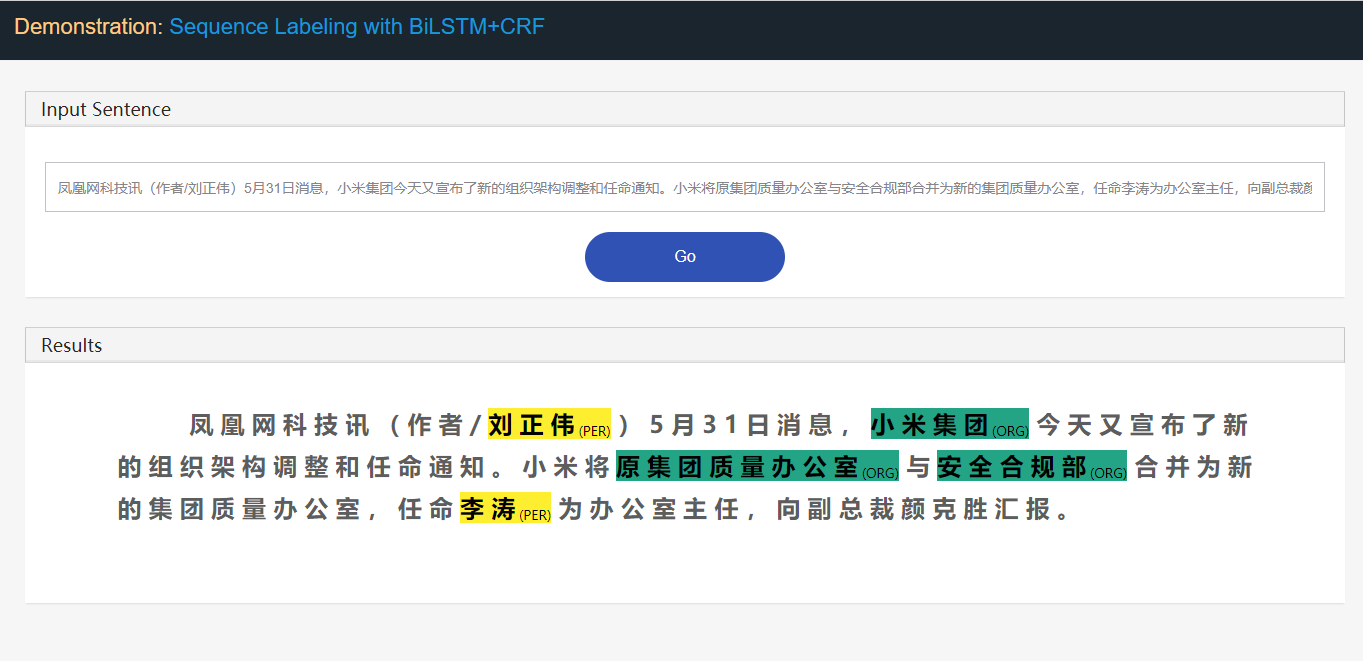
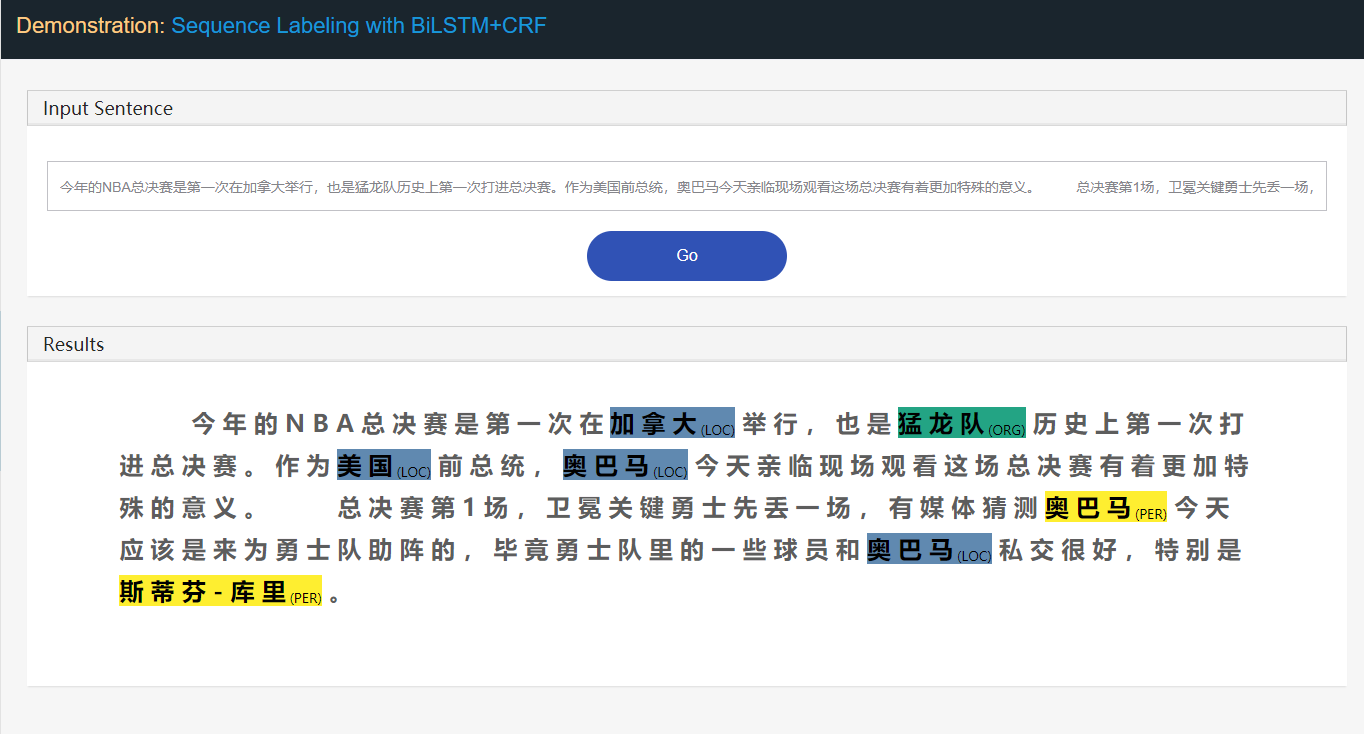
包括火车集,测试集,DEV集在内的数据集对于整体使用情况是必需的。但是,您是否只想训练模型脱机,只需要火车集。训练后,您可以使用保存的模型检查点文件进行推断。如果您想进行测试,应该
对于trainset , testset , devset ,常见格式如下:
(Token) (Label)
for O
the O
lattice B_TAS
QCD I_TAS
computation I_TAS
of I_TAS
nucleon–nucleon I_TAS
low-energy I_TAS
interactions E_TAS
. O
It O
consists O
in O
simulating B_PRO
...
(Token) (Label)
马 B-LOC
来 I-LOC
西 I-LOC
亚 I-LOC
副 O
总 O
理 O
。 O
他 O
兼 O
任 O
财 B-ORG
政 I-ORG
部 I-ORG
长 O
...
注意:
testset只能使用Token行存在。在测试过程中,模型将基于test.csv输出预测的实体。输出文件包括两个: test.out , test.entity.out (可选)。
test.out
与输入test.csv相同的形成。
test.entity.out
Sentence
entity1 (Type)
entity2 (Type)
entity3 (Type)
...
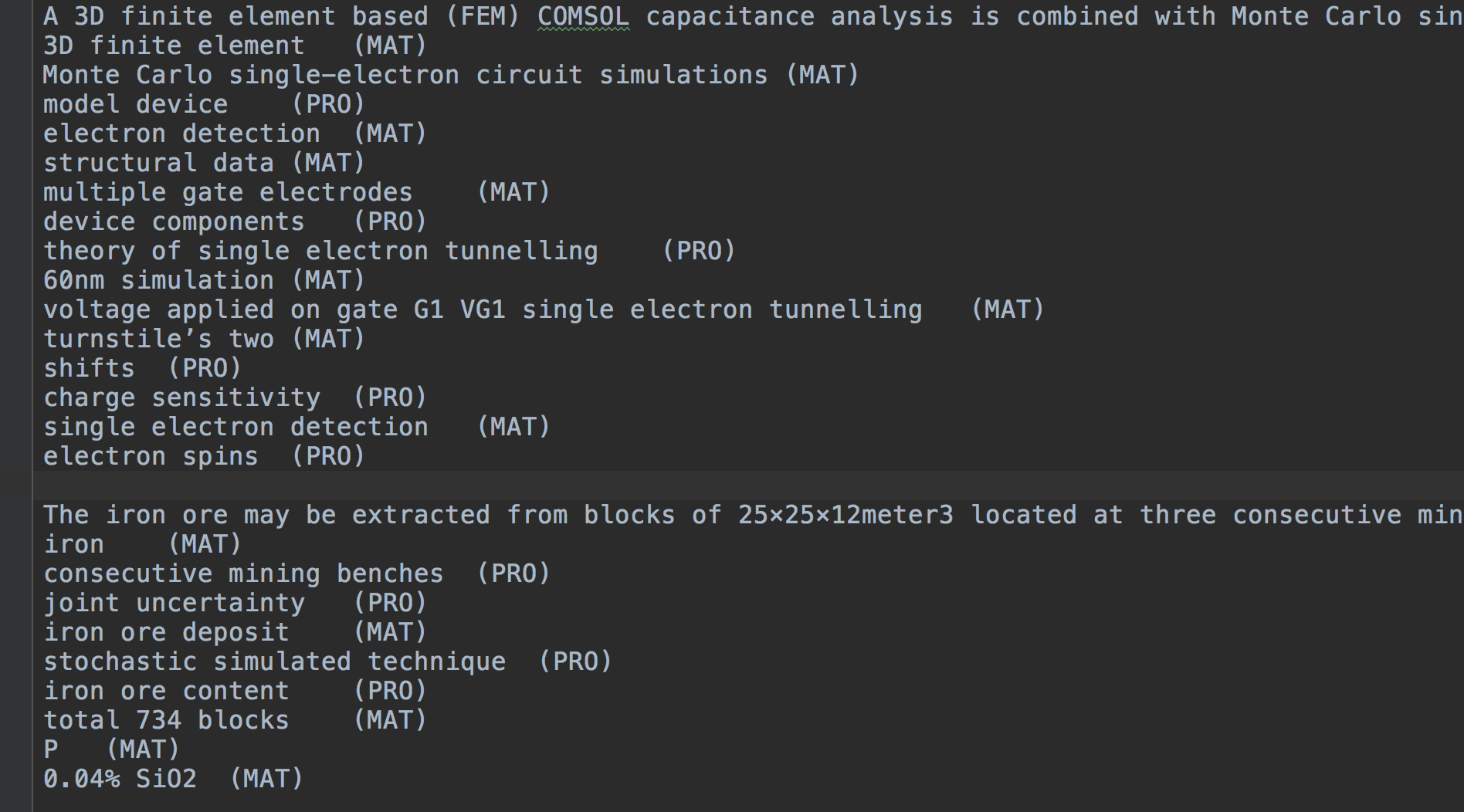
如果您想将该项目适应自己的特定序列标签任务,则可能需要以下提示。
下载回购资源。
标签方案(最重要)
B_PER', i_loc'模型:将模型体系结构修改为您想要的模型架构,以BiLSTM_CRFs.py 。
数据集:在正确的编辑中适应您的数据集。
训练
有关更多使用详细信息,请参考手册
欢迎您发出任何错误。


