sequence labeling BiLSTM CRF
1.0.0
시퀀스 라벨링 작업을위한 BILSTM+CRF 모델의 텐서 플로 구현.
Sequential labeling NLP의 시퀀스 예측 작업을 모델링하는 전형적인 방법론 중 하나입니다. 일반적인 순차적 라벨링 작업에는 다음이 포함됩니다.
NER ( 지정된 엔티티 인식 ) 작업을 예로 들어보세요 :
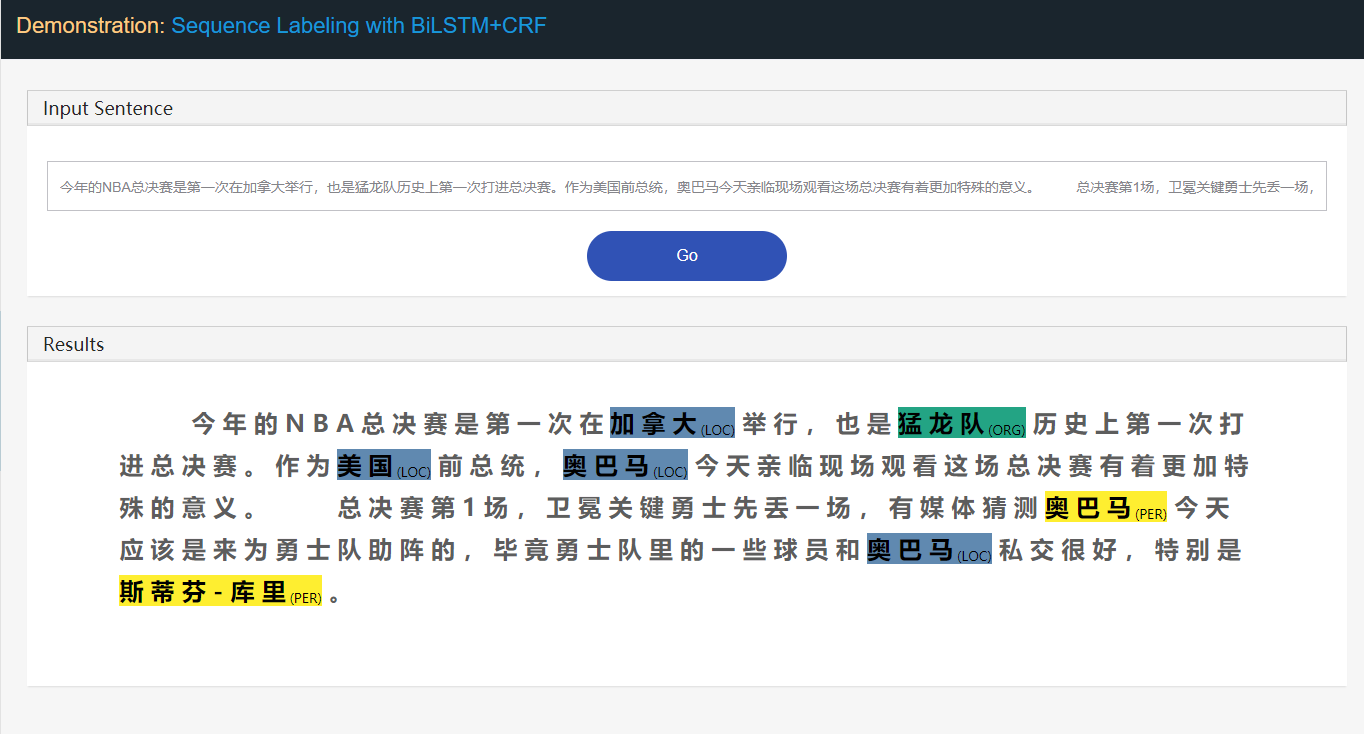
Stanford University located at California .
B-ORG I-ORG O O B-LOC O 여기에서 Stanford University 와 California 두 개체가 추출됩니다. 특히 텍스트의 각 token 에는 해당 label 태그됩니다. 예 : { token : Stanford , label : B-org }. 서열 레이블링 모델은 토큰 시퀀스가 주어진 레이블 시퀀스를 예측하는 것을 목표로한다.
2016 년 Lample et al.에 의해 제안 된 BiLSTM+CRF 지금까지 순차적 라벨링 작업을위한 가장 고전적이고 안정적인 신경 모델입니다. 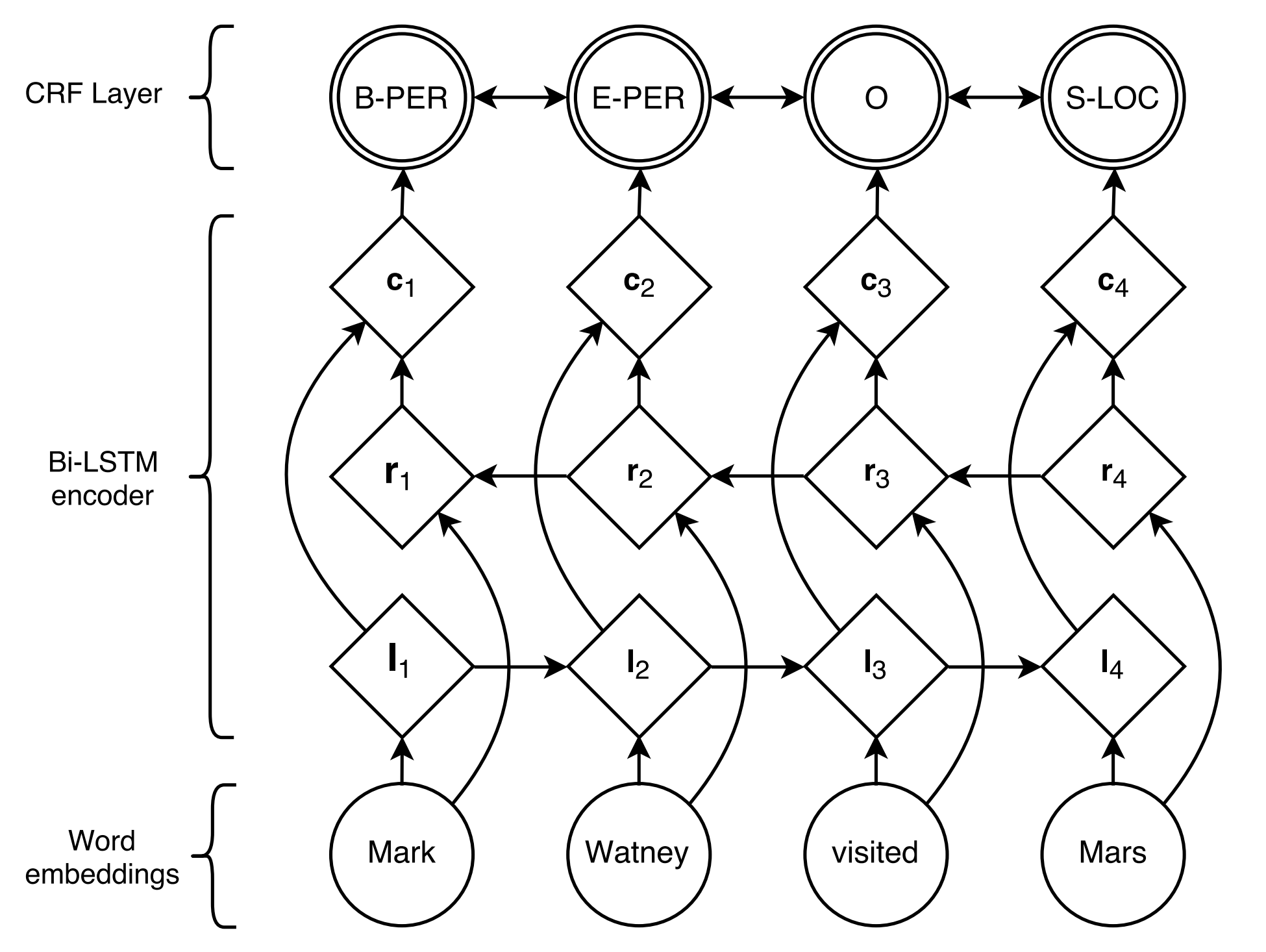
모든 설정 구성
train / test / interactive_predict / api_service ]BIO / BIESO ]PER | LOC | ORG ]모든 것을 기록합니다
쉬운 데모를위한 웹 앱 데모
객체 지향 : bilstm_crf, 데이터 세트, configer, utils
명확한 구조로 모듈화되어 DIY가 쉽습니다.
핸드북에서 더 많이보십시오.
직접 사용하려면 저장소를 다운로드하십시오.
git clone https://github.com/scofield7419/sequence-labeling-BiLSTM-CRF.git
pip install -r requirements.txt
BILSTM-CRF 패키지를 모듈로 설치하십시오.
pip install BiLSTM-CRF
용법:
from BiLSTM-CRF.engines.BiLSTM_CRFs import BiLSTM_CRFs as BC
from BiLSTM-CRF.engines.DataManager import DataManager
from BiLSTM-CRF.engines.Configer import Configer
from BiLSTM-CRF.engines.utils import get_logger
...
config_file = r'/home/projects/system.config'
configs = Configer(config_file)
logger = get_logger(configs.log_dir)
configs.show_data_summary(logger) # optional
dataManager = DataManager(configs, logger)
model = BC(configs, logger, dataManager)
###### mode == 'train':
model.train()
###### mode == 'test':
model.test()
###### mode == 'single predicting':
sentence_tokens, entities, entities_type, entities_index = model.predict_single(sentence)
if configs.label_level == 1:
print("nExtracted entities:n %snn" % ("n".join(entities)))
elif configs.label_level == 2:
print("nExtracted entities:n %snn" % ("n".join([a + "t(%s)" % b for a, b in zip(entities, entities_type)])))
###### mode == 'api service webapp':
cmd_new = r'cd demo_webapp; python manage.py runserver %s:%s' % (configs.ip, configs.port)
res = os.system(cmd_new)
open `ip:port` in your browser.
├── main.py
├── system.config
├── HandBook.md
├── README.md
│
├── checkpoints
│ ├── BILSTM-CRFs-datasets1
│ │ ├── checkpoint
│ │ └── ...
│ └── ...
├── data
│ ├── example_datasets1
│ │ ├── logs
│ │ ├── vocabs
│ │ ├── test.csv
│ │ ├── train.csv
│ │ └── dev.csv
│ └── ...
├── demo_webapp
│ ├── demo_webapp
│ ├── interface
│ └── manage.py
├── engines
│ ├── BiLSTM_CRFs.py
│ ├── Configer.py
│ ├── DataManager.py
│ └── utils.py
└── tools
├── calcu_measure_testout.py
└── statis.py
주름
engines 접이식에서 코어 기능 PY를 제공합니다.data-subfold Fold에서는 데이터 세트가 배치됩니다.checkpoints-subfold 폴드에서 모델 체크 포인트가 저장됩니다.demo_webapp Fold에서는 웹에서 시스템을 시연하고 API를 제공 할 수 있습니다.tools 접이식으로 일부 오프라인 유틸리티를 제공합니다.파일
main.py 는 시스템의 입력 파이썬 파일입니다.system.config 는 모든 시스템 설정에 대한 구성 파일입니다.HandBook.md 몇 가지 사용 지침을 제공합니다.BiLSTM_CRFs.py 기본 모델입니다.Configer.py system.config 구문 분석합니다.DataManager.py 데이터 세트 및 스케줄링을 관리합니다.utils.py 비행 도구를 제공합니다. 다음 단계에 따라 :
system.config 에서 구성 파일 작성.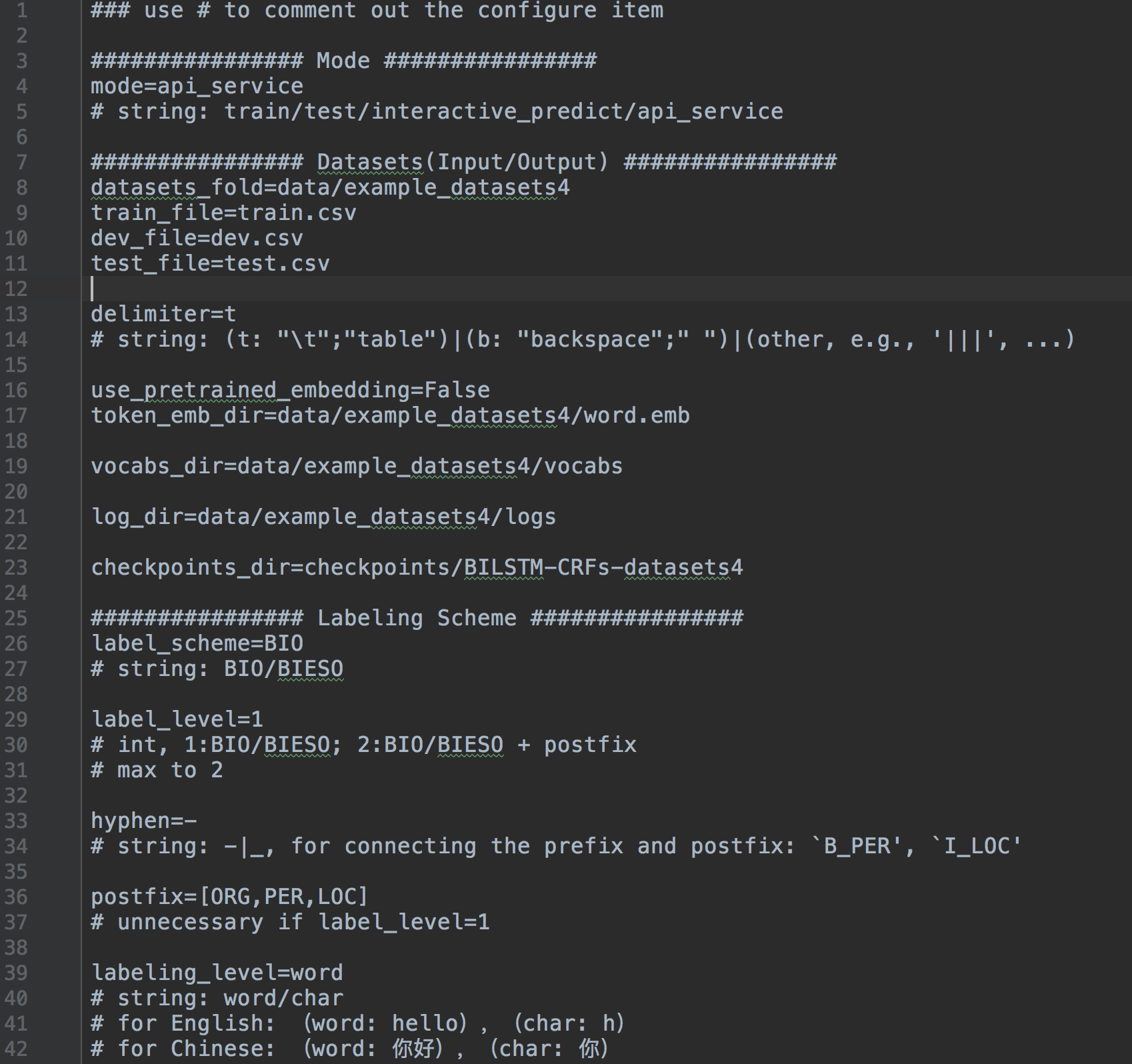
main.py 실행하십시오. 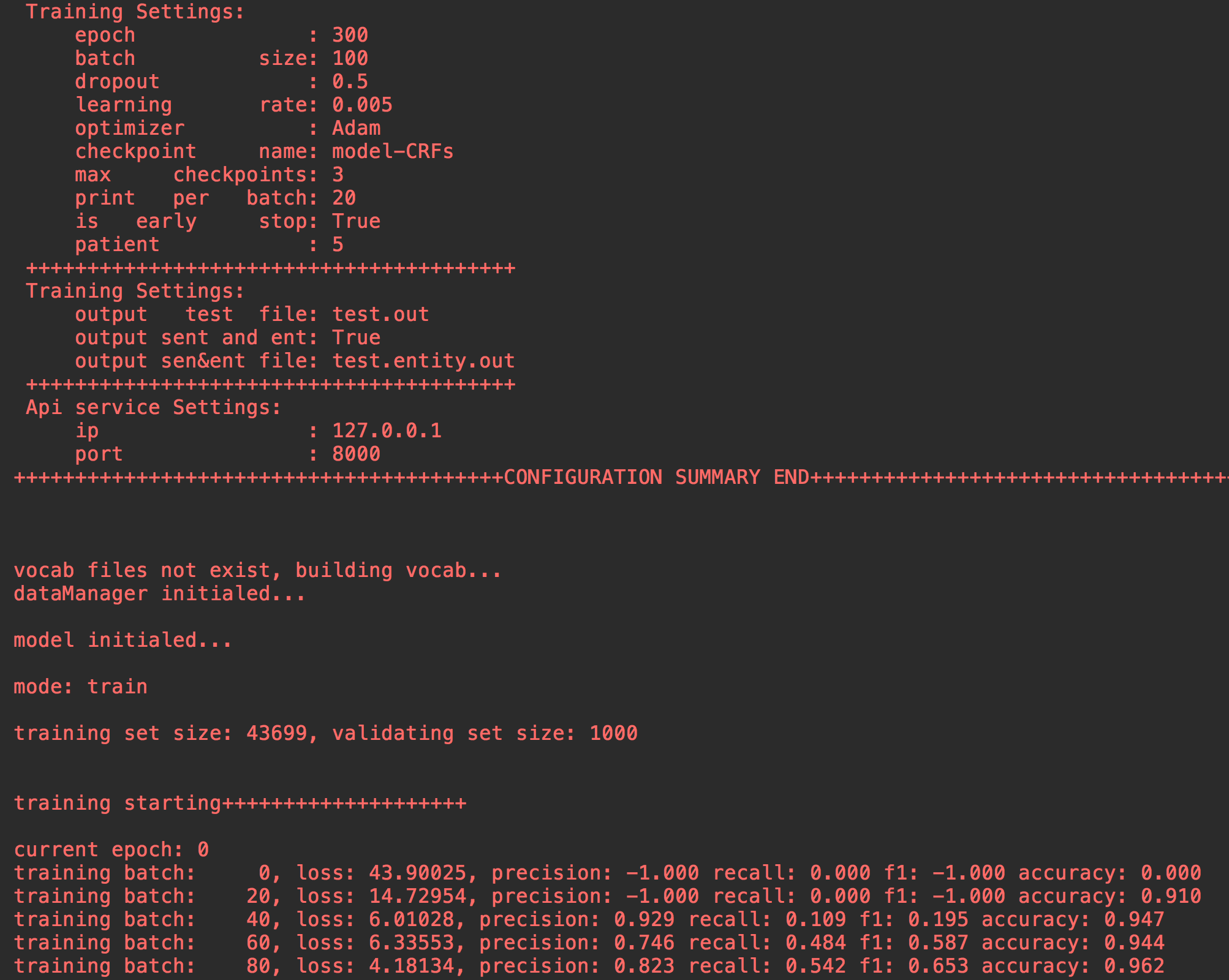
main.py 실행하십시오. main.py 실행하십시오.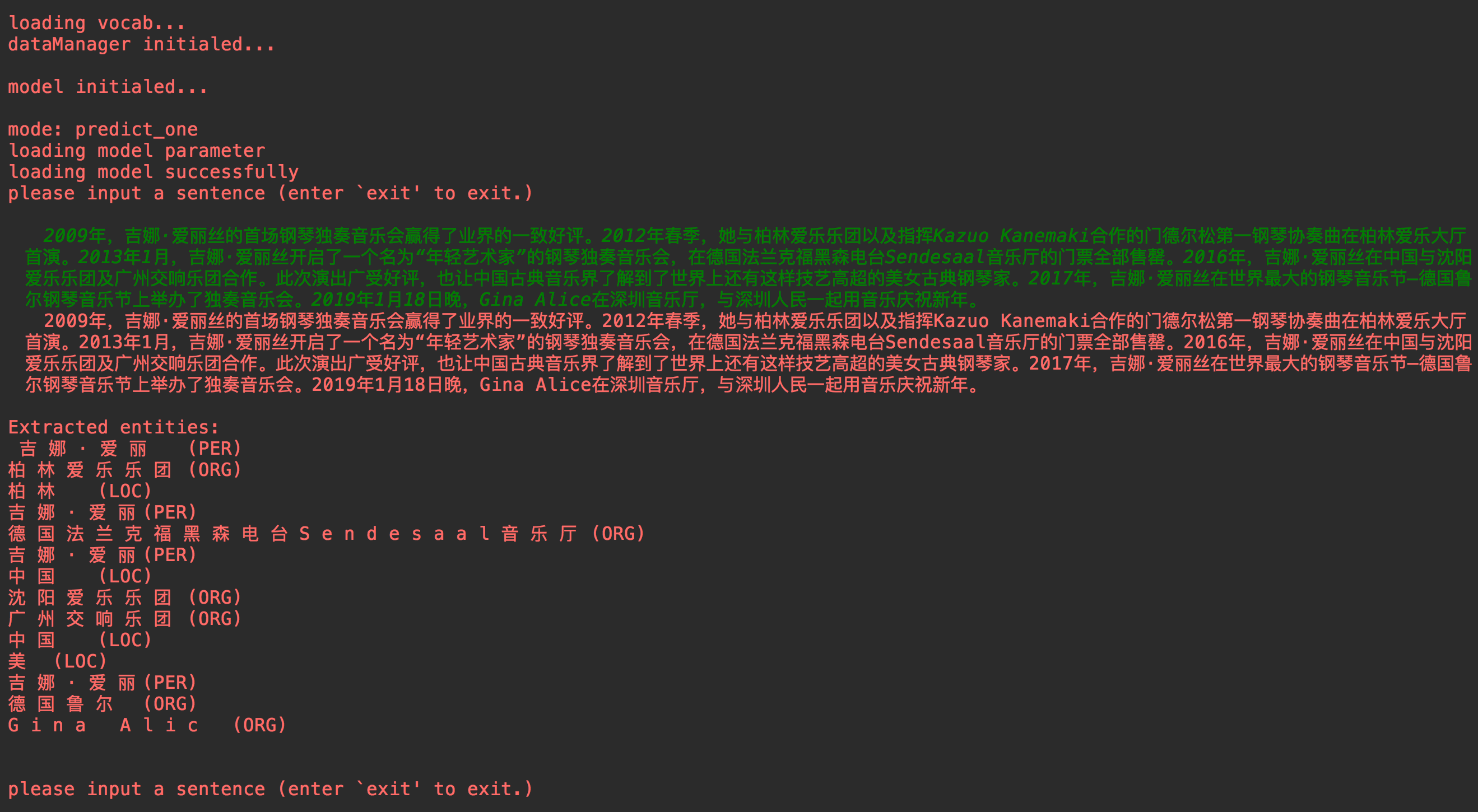
main.py 실행하십시오.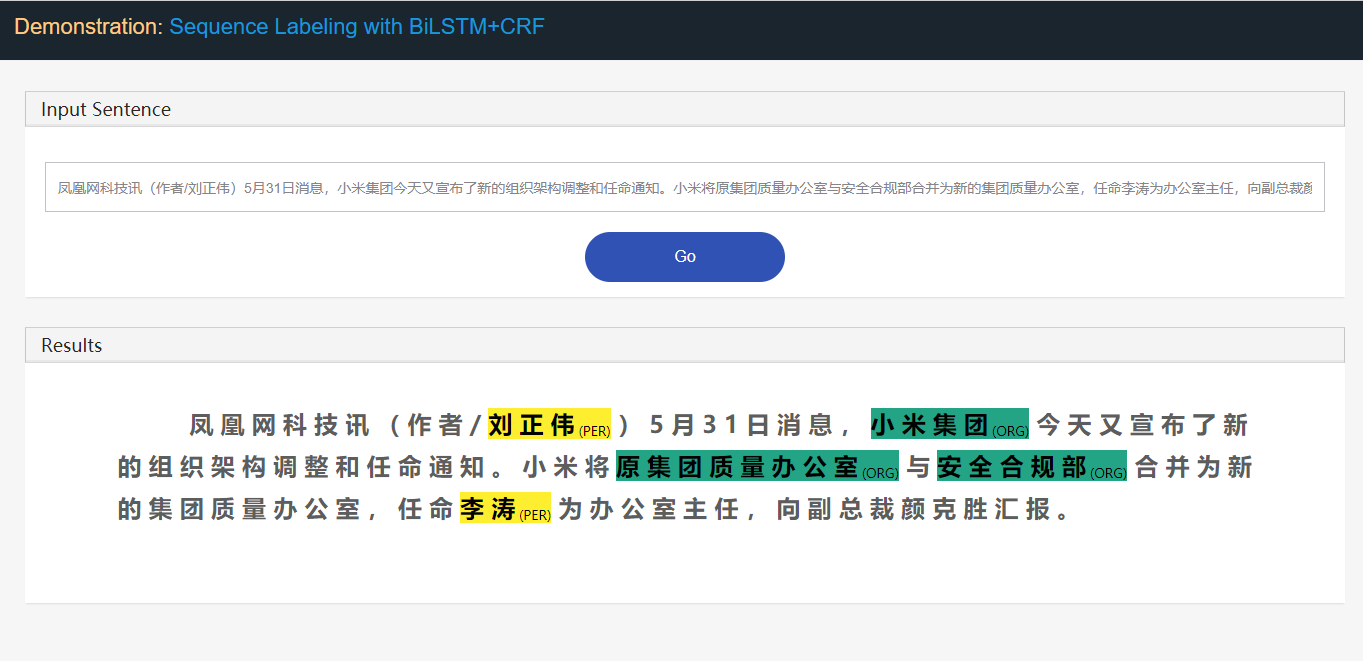
Trainset, Testset, Devset을 포함한 데이터 세트는 전체 사용에 필요합니다. 그러나 오프라인으로 사용하는 모델 만 훈련하고 싶습니까? Trainset 만 필요합니다. 교육 후 저장된 모델 체크 포인트 파일을 추론 할 수 있습니다. 테스트를 원한다면해야합니다
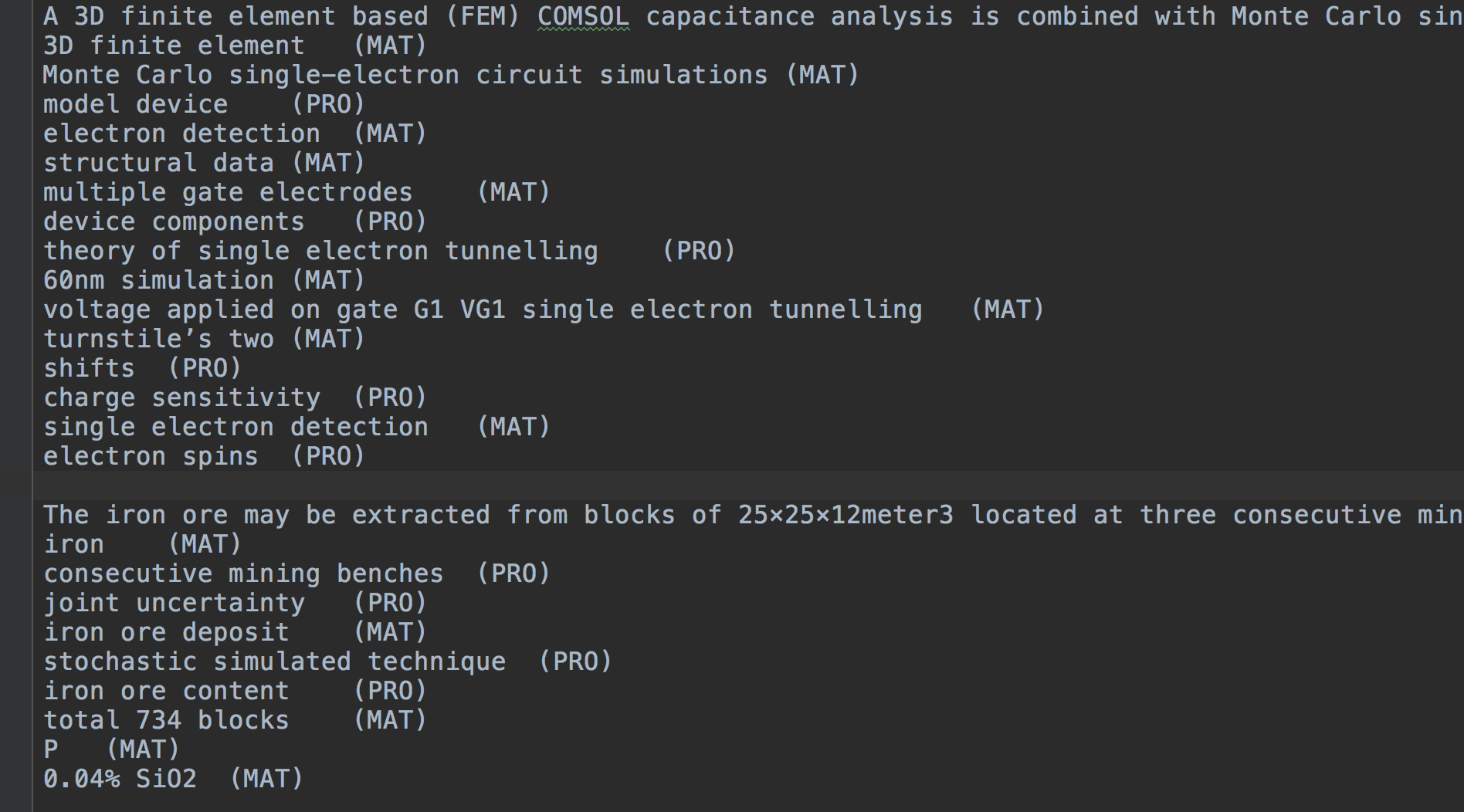
trainset , testset , devset 의 경우 공통 형식은 다음과 같습니다.
(Token) (Label)
for O
the O
lattice B_TAS
QCD I_TAS
computation I_TAS
of I_TAS
nucleon–nucleon I_TAS
low-energy I_TAS
interactions E_TAS
. O
It O
consists O
in O
simulating B_PRO
...
(Token) (Label)
马 B-LOC
来 I-LOC
西 I-LOC
亚 I-LOC
副 O
总 O
理 O
。 O
他 O
兼 O
任 O
财 B-ORG
政 I-ORG
部 I-ORG
长 O
...
주목하십시오 :
testset Token Row에서만 존재할 수 있습니다. 테스트 중에 모델은 test.csv 기반으로 예측 된 엔티티를 출력합니다. 출력 파일에는 test.out , test.entity.out (선택 사항) 두 가지가 포함됩니다.
test.out
입력 test.csv 와 동일한 형성으로.
test.entity.out
Sentence
entity1 (Type)
entity2 (Type)
entity3 (Type)
...
이 프로젝트를 자신의 특정 시퀀스 라벨링 작업에 조정하려면 다음 팁이 필요할 수 있습니다.
리포 소스를 다운로드하십시오.
라벨링 체계 (가장 중요한)
B_PER', i_loc' 모델 : BiLSTM_CRFs.py 에서 원하는 모델 아키텍처를 원하는 모델로 수정하십시오.
데이터 세트 : 올바른 형식으로 데이터 세트에 적응합니다.
훈련
자세한 내용은 핸드북을 참조하십시오
당신은 잘못된 것을 발행하는 것을 환영합니다.


