sequence labeling BiLSTM CRF
1.0.0
Eine Tensorflow -Implementierung des BILSTM+CRF -Modells für Sequenzmarkierungsaufgaben.
Sequential labeling ist eine typische Methodik, die die Sequenzvorhersageaufgaben in NLP modelliert. Häufige sequentielle Kennzeichnungsaufgaben umfassen z. B., z.
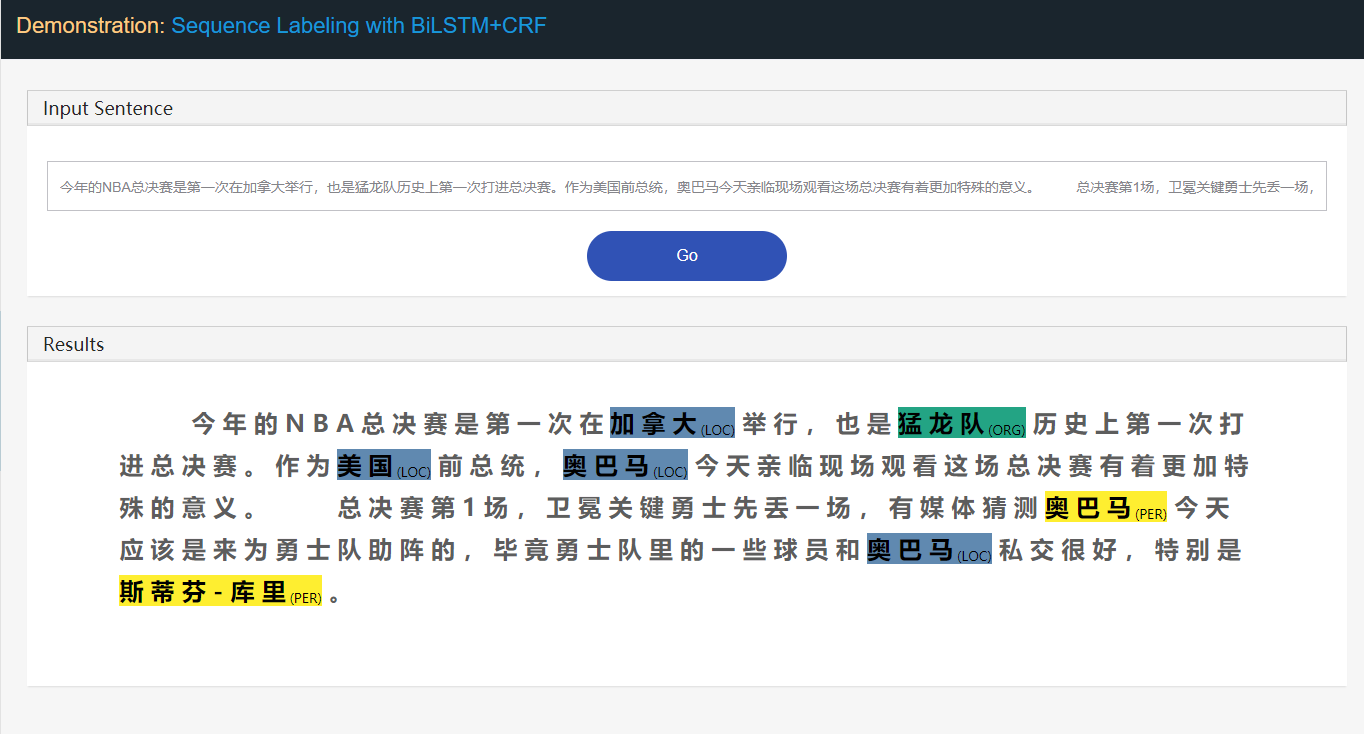
NER -Aufgabe der genannten Entitätserkennung (NER) als Beispiel:
Stanford University located at California .
B-ORG I-ORG O O B-LOC O Hier sollen zwei Einheiten, Stanford University und California extrahiert werden. Und speziell wird jedes token im Text mit einer entsprechenden label markiert. EG, { token : Stanford , label : B-org }. Das Sequenzmarkierungsmodell zielt darauf ab, die Label -Sequenz bei einer Token -Sequenz vorherzusagen.
BiLSTM+CRF von Lample et al., 2016 vorgeschlagen, ist bisher das klassischste und stabilste Neuralmodell für sequentielle Kennzeichnungsaufgaben. 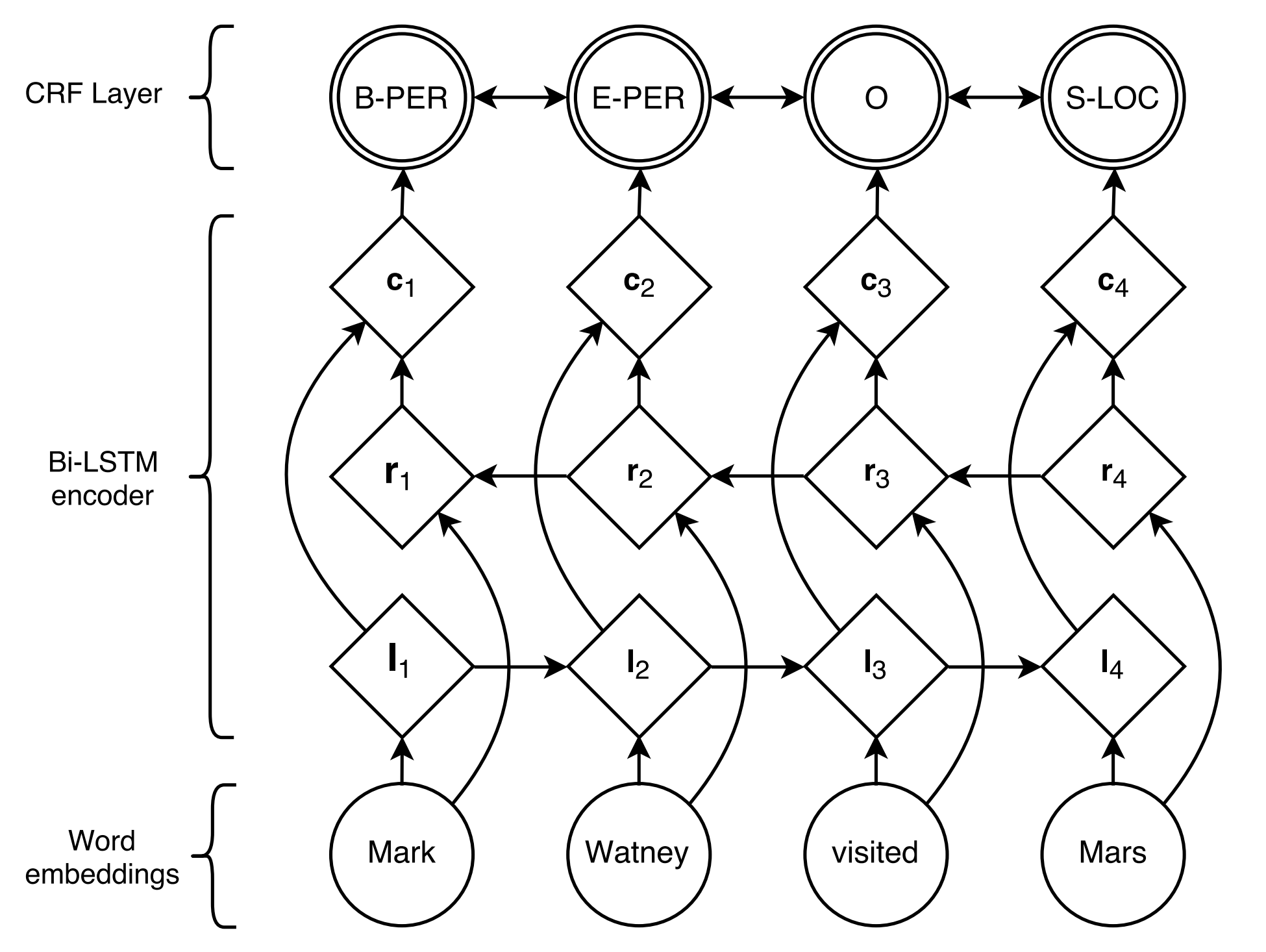
Konfigurieren aller Einstellungen
train / test / interactive_predict / api_service ]BIO / BIESO ]PER | LOC | ORG ]alles protokollieren
Web -App -Demo für einfache Demonstration
objektorientiert: bilstm_crf, Datensätze, Kondition, Utils
Modularisiert mit klarer Struktur, einfach für DIY.
Siehe mehr im Handbuch.
Laden Sie das Repo für direkte Verwendung herunter.
git clone https://github.com/scofield7419/sequence-labeling-BiLSTM-CRF.git
pip install -r requirements.txt
Installieren Sie das BILSTM-CRF-Paket als Modul.
pip install BiLSTM-CRF
Verwendung:
from BiLSTM-CRF.engines.BiLSTM_CRFs import BiLSTM_CRFs as BC
from BiLSTM-CRF.engines.DataManager import DataManager
from BiLSTM-CRF.engines.Configer import Configer
from BiLSTM-CRF.engines.utils import get_logger
...
config_file = r'/home/projects/system.config'
configs = Configer(config_file)
logger = get_logger(configs.log_dir)
configs.show_data_summary(logger) # optional
dataManager = DataManager(configs, logger)
model = BC(configs, logger, dataManager)
###### mode == 'train':
model.train()
###### mode == 'test':
model.test()
###### mode == 'single predicting':
sentence_tokens, entities, entities_type, entities_index = model.predict_single(sentence)
if configs.label_level == 1:
print("nExtracted entities:n %snn" % ("n".join(entities)))
elif configs.label_level == 2:
print("nExtracted entities:n %snn" % ("n".join([a + "t(%s)" % b for a, b in zip(entities, entities_type)])))
###### mode == 'api service webapp':
cmd_new = r'cd demo_webapp; python manage.py runserver %s:%s' % (configs.ip, configs.port)
res = os.system(cmd_new)
open `ip:port` in your browser.
├── main.py
├── system.config
├── HandBook.md
├── README.md
│
├── checkpoints
│ ├── BILSTM-CRFs-datasets1
│ │ ├── checkpoint
│ │ └── ...
│ └── ...
├── data
│ ├── example_datasets1
│ │ ├── logs
│ │ ├── vocabs
│ │ ├── test.csv
│ │ ├── train.csv
│ │ └── dev.csv
│ └── ...
├── demo_webapp
│ ├── demo_webapp
│ ├── interface
│ └── manage.py
├── engines
│ ├── BiLSTM_CRFs.py
│ ├── Configer.py
│ ├── DataManager.py
│ └── utils.py
└── tools
├── calcu_measure_testout.py
└── statis.py
Falten
engines falten Sie den Kernfunktions -Py.data-subfold Faltung werden die Datensätze platziert.checkpoints-subfold Falten werden Modell-Checkpoints gespeichert.demo_webapp -FALD können wir das System im Web demonstrieren und API bereitstellen.tools falten Sie einige Offline -Utils.Dateien
main.py ist die Eintragspython -Datei für das System.system.config ist die Konfiguration von Datei für alle Systemeinstellungen.HandBook.md bietet einige Verwendungsanweisungen.BiLSTM_CRFs.py ist das Hauptmodell.Configer.py analysiert das system.config .DataManager.py verwaltet die Datensätze und die Planung.utils.py bietet in den Fliegenwerkzeugen. Unter den folgenden Schritten:
system.config .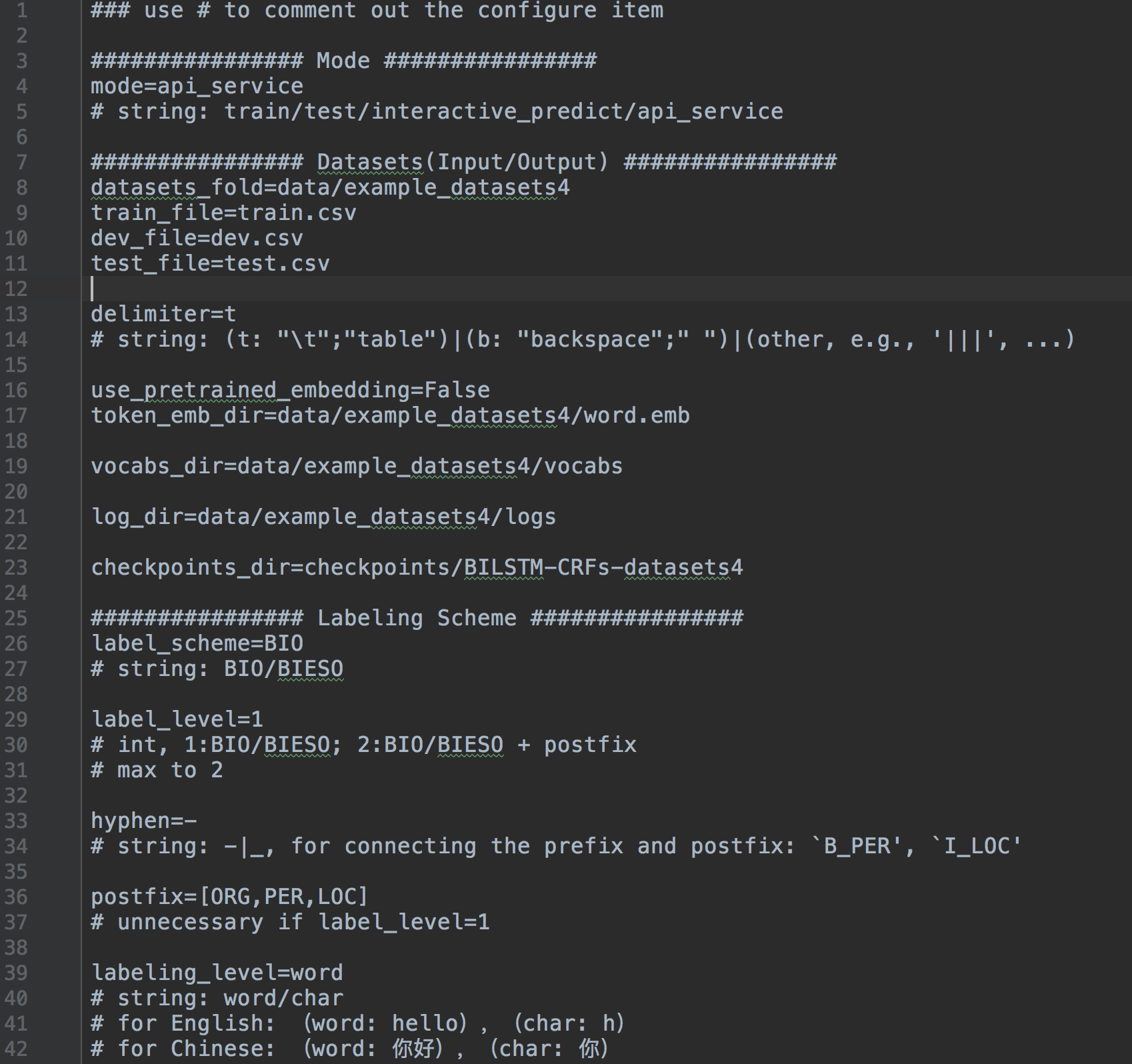
main.py 
main.py main.py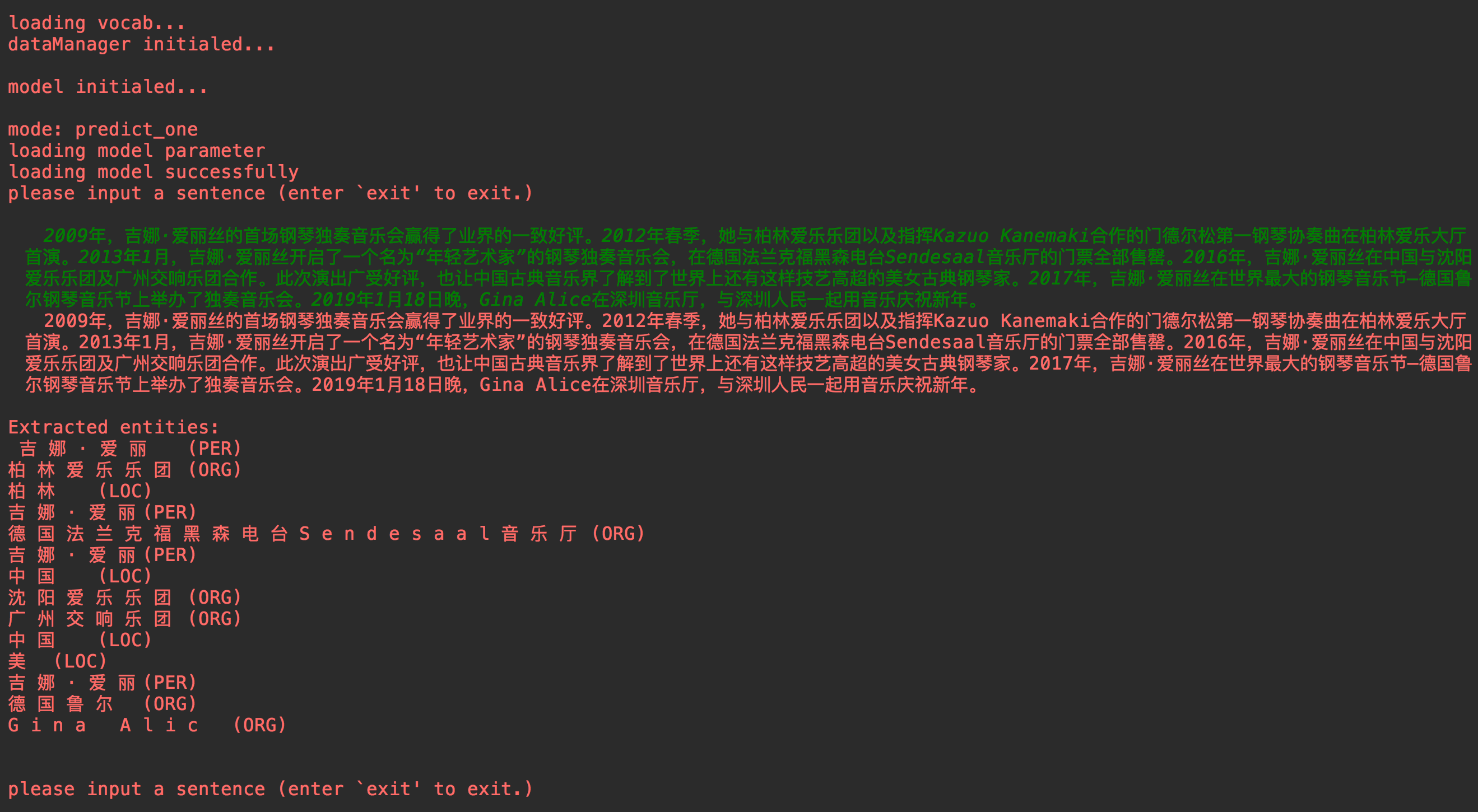
main.py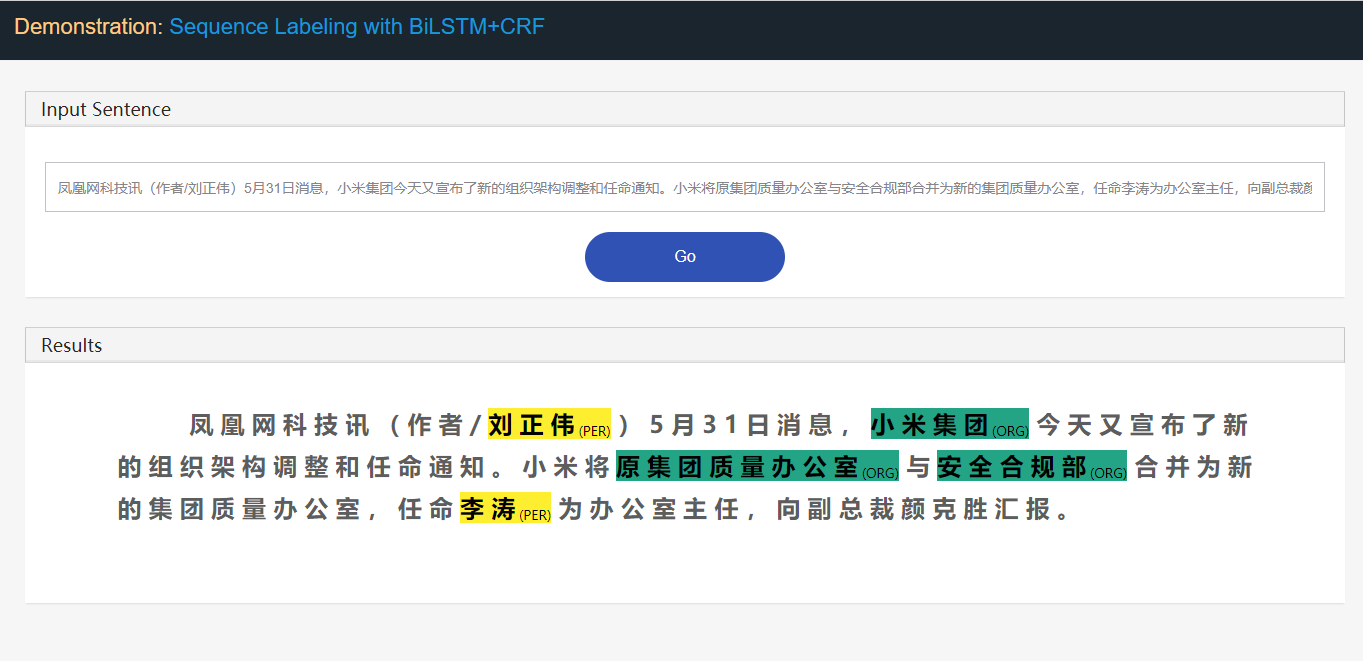
Datensätze, einschließlich Trainset, Testset, DevSet, sind für die Gesamtnutzung erforderlich. Ist es jedoch nur, dass Sie das Modell nur dann trainieren möchten, sondern nur das Trainset benötigt. Nach dem Training können Sie die Sparenmodell -Checkpoint -Dateien inferenzieren. Wenn Sie Test machen möchten, sollten Sie es sollten
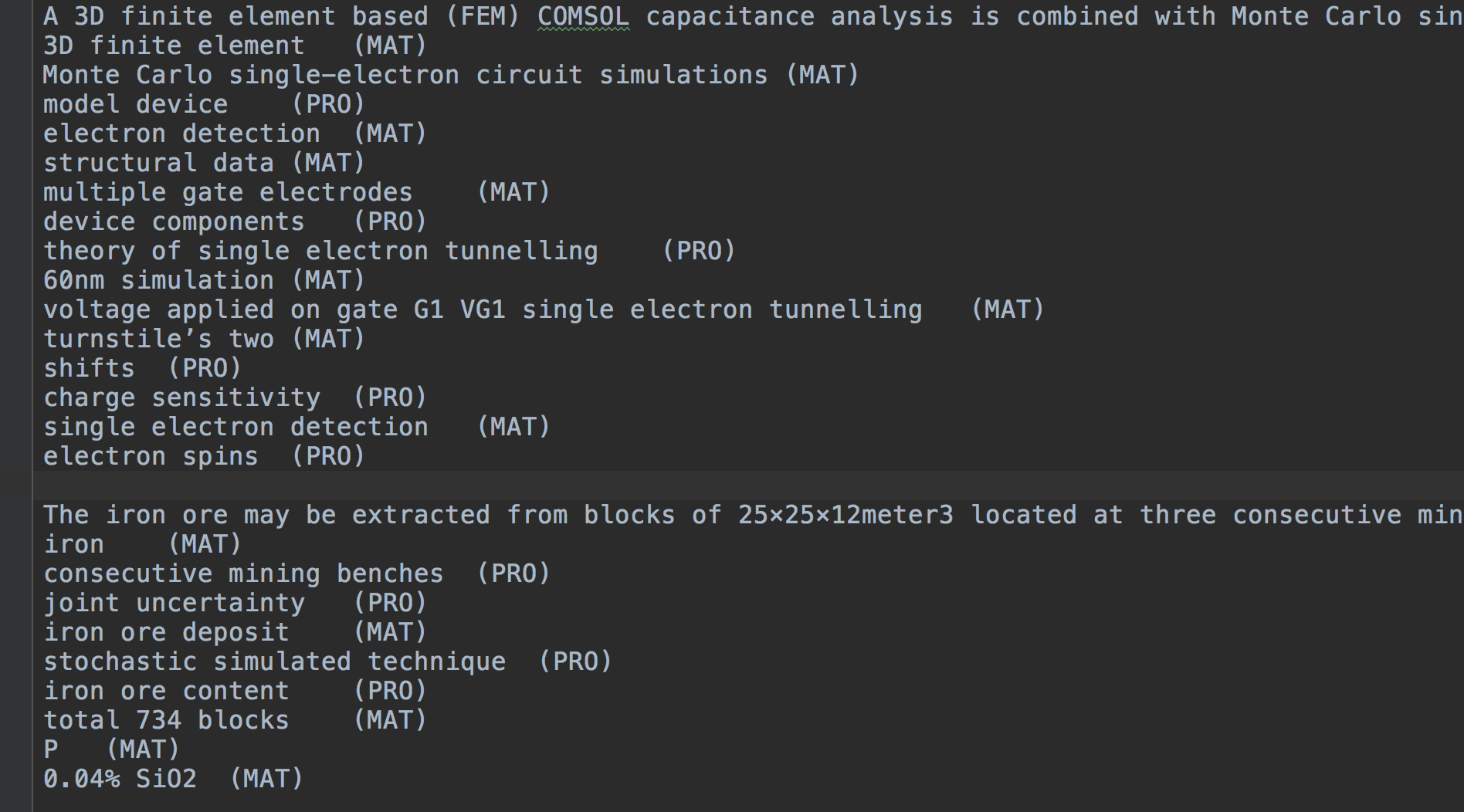
Für trainset , testset , devset , lautet das gemeinsame Format wie folgt:
(Token) (Label)
for O
the O
lattice B_TAS
QCD I_TAS
computation I_TAS
of I_TAS
nucleon–nucleon I_TAS
low-energy I_TAS
interactions E_TAS
. O
It O
consists O
in O
simulating B_PRO
...
(Token) (Label)
马 B-LOC
来 I-LOC
西 I-LOC
亚 I-LOC
副 O
总 O
理 O
。 O
他 O
兼 O
任 O
财 B-ORG
政 I-ORG
部 I-ORG
长 O
...
Beachten Sie, dass:
testset kann nur mit der Token -Reihe existieren. Während des Tests gibt das Modell die vorhergesagten Entitäten basierend auf dem test.csv aus. Die Ausgabedateien umfassen zwei: test.out , test.entity.out (optional).
test.out
mit der gleichen Formation wie test.csv .
test.entity.out
Sentence
entity1 (Type)
entity2 (Type)
entity3 (Type)
...
Wenn Sie dieses Projekt an Ihre eigene Sequenz -Kennzeichnungsaufgabe anpassen möchten, benötigen Sie möglicherweise die folgenden Tipps.
Laden Sie die Repo -Quellen herunter.
Etikettierungsschema (am wichtigsten)
B_PER', i_loc' Modell: Ändern Sie die Modellarchitektur in die, die Sie gewünscht haben, in BiLSTM_CRFs.py .
Datensatz: Passen Sie Ihren Datensatz in der richtigen Formation an.
Ausbildung
Weitere Informationen zum Gebrauchsgebrauch beziehen sich bitte auf das Handbuch
Sie sind begrüßt, um etwas falsch zu machen.


