sequence labeling BiLSTM CRF
1.0.0
การใช้งาน TensorFlow ของโมเดล BILSTM+CRF สำหรับงานการติดฉลากลำดับ
Sequential labeling เป็นวิธีการทั่วไปวิธีการสร้างแบบจำลองงานการทำนายลำดับใน NLP งานการติดฉลากตามลำดับทั่วไป ได้แก่ เช่น
รับงาน การจดจำเอนทิตี (NER) เป็นตัวอย่าง:
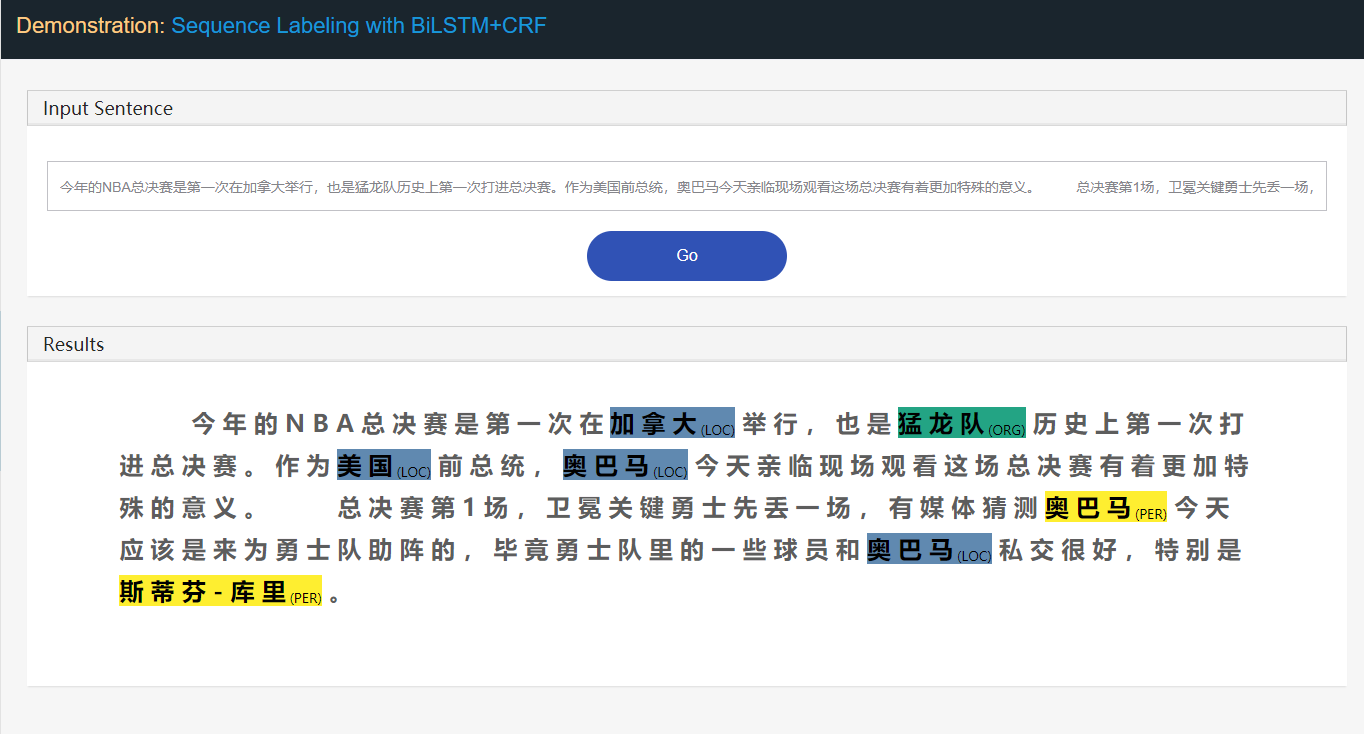
Stanford University located at California .
B-ORG I-ORG O O B-LOC O ที่นี่สองหน่วยงาน Stanford University และ California จะถูกสกัด และโดยเฉพาะอย่างยิ่ง token แต่ละรายการในข้อความจะถูกแท็กด้วย label ที่เกี่ยวข้อง เช่น { token : สแตนฟอร์ด , label : b-org } รูปแบบการติดฉลากลำดับมีจุดมุ่งหมายเพื่อทำนายลำดับฉลากตามลำดับโทเค็น
BiLSTM+CRF ที่เสนอโดย Lample et al., 2016 เป็นแบบจำลองระบบประสาทคลาสสิกและเสถียรที่สุดสำหรับงานการติดฉลากตามลำดับ 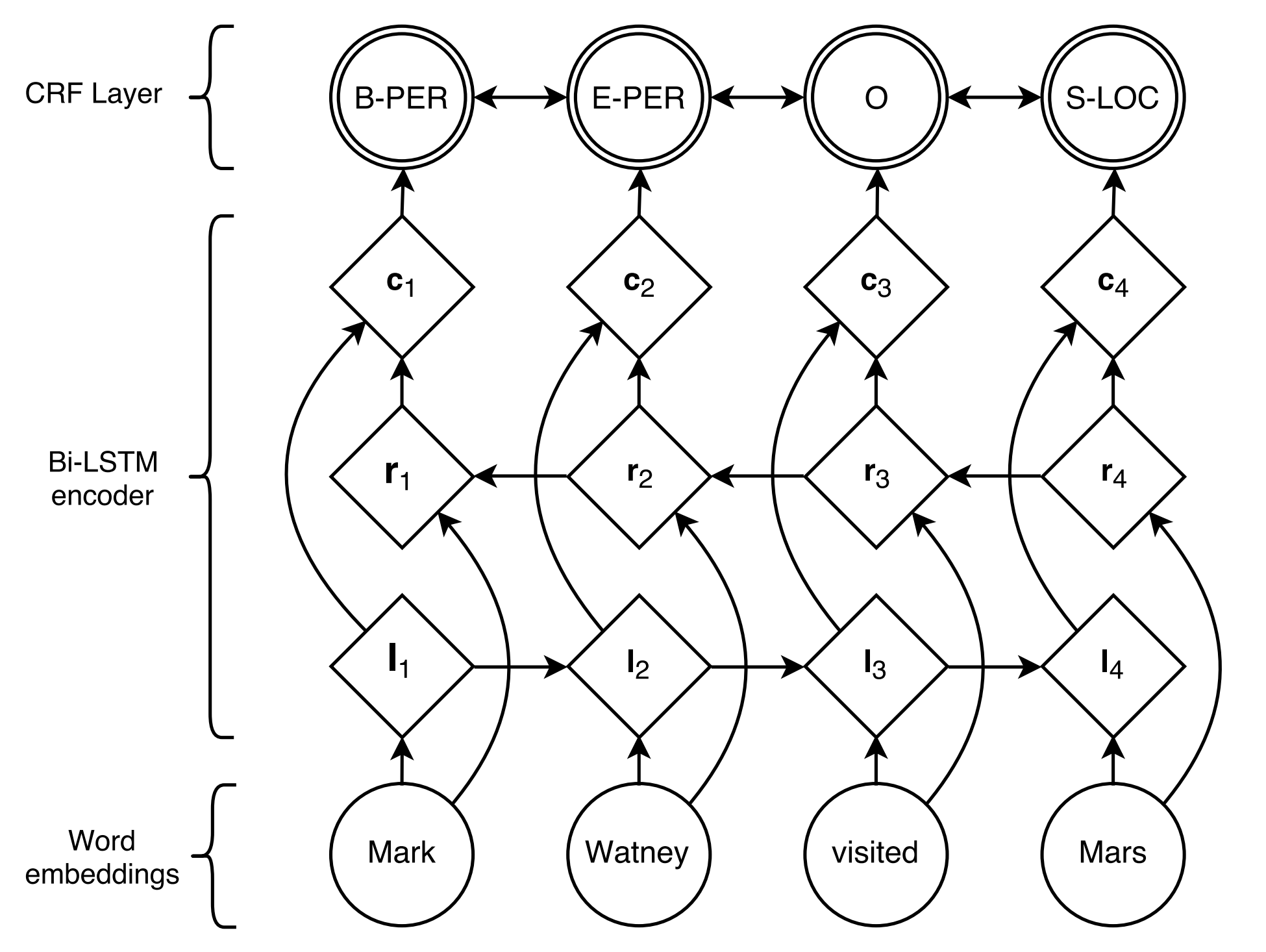
การกำหนดค่าการตั้งค่าทั้งหมด
train / test / interactive_predict / api_service ]BIO / BIESO ]PER | LOC | ORG ]เข้าสู่ระบบทุกอย่าง
การสาธิตเว็บแอปสำหรับการสาธิตง่ายๆ
Object มุ่งเน้น: bilstm_crf, ชุดข้อมูล, configer, utils
แบบแยกส่วนด้วยโครงสร้างที่ชัดเจนง่ายสำหรับ DIY
ดูเพิ่มเติมในคู่มือ
ดาวน์โหลด repo สำหรับใช้โดยตรง
git clone https://github.com/scofield7419/sequence-labeling-BiLSTM-CRF.git
pip install -r requirements.txt
ติดตั้งแพ็คเกจ BILSTM-CRF เป็นโมดูล
pip install BiLSTM-CRF
การใช้งาน:
from BiLSTM-CRF.engines.BiLSTM_CRFs import BiLSTM_CRFs as BC
from BiLSTM-CRF.engines.DataManager import DataManager
from BiLSTM-CRF.engines.Configer import Configer
from BiLSTM-CRF.engines.utils import get_logger
...
config_file = r'/home/projects/system.config'
configs = Configer(config_file)
logger = get_logger(configs.log_dir)
configs.show_data_summary(logger) # optional
dataManager = DataManager(configs, logger)
model = BC(configs, logger, dataManager)
###### mode == 'train':
model.train()
###### mode == 'test':
model.test()
###### mode == 'single predicting':
sentence_tokens, entities, entities_type, entities_index = model.predict_single(sentence)
if configs.label_level == 1:
print("nExtracted entities:n %snn" % ("n".join(entities)))
elif configs.label_level == 2:
print("nExtracted entities:n %snn" % ("n".join([a + "t(%s)" % b for a, b in zip(entities, entities_type)])))
###### mode == 'api service webapp':
cmd_new = r'cd demo_webapp; python manage.py runserver %s:%s' % (configs.ip, configs.port)
res = os.system(cmd_new)
open `ip:port` in your browser.
├── main.py
├── system.config
├── HandBook.md
├── README.md
│
├── checkpoints
│ ├── BILSTM-CRFs-datasets1
│ │ ├── checkpoint
│ │ └── ...
│ └── ...
├── data
│ ├── example_datasets1
│ │ ├── logs
│ │ ├── vocabs
│ │ ├── test.csv
│ │ ├── train.csv
│ │ └── dev.csv
│ └── ...
├── demo_webapp
│ ├── demo_webapp
│ ├── interface
│ └── manage.py
├── engines
│ ├── BiLSTM_CRFs.py
│ ├── Configer.py
│ ├── DataManager.py
│ └── utils.py
└── tools
├── calcu_measure_testout.py
└── statis.py
รอยพับ
engines ให้การทำงานหลักdata-subfold ข้อมูลจะถูกวางไว้checkpoints-subfold จุดตรวจสอบจะถูกเก็บไว้demo_webapp Fold เราสามารถแสดงระบบในเว็บและให้ APItools พับให้การใช้งานออฟไลน์ไฟล์
main.py เป็นไฟล์ Python รายการสำหรับระบบsystem.config เป็นไฟล์กำหนดค่าสำหรับการตั้งค่าระบบทั้งหมดHandBook.md ให้คำแนะนำการใช้งานบางอย่างBiLSTM_CRFs.py เป็นรุ่นหลักConfiger.py แยกวิเคราะห์ system.configDataManager.py จัดการชุดข้อมูลและการกำหนดเวลาutils.py นำเสนอเครื่องมือบิน ภายใต้ขั้นตอนต่อไปนี้:
system.config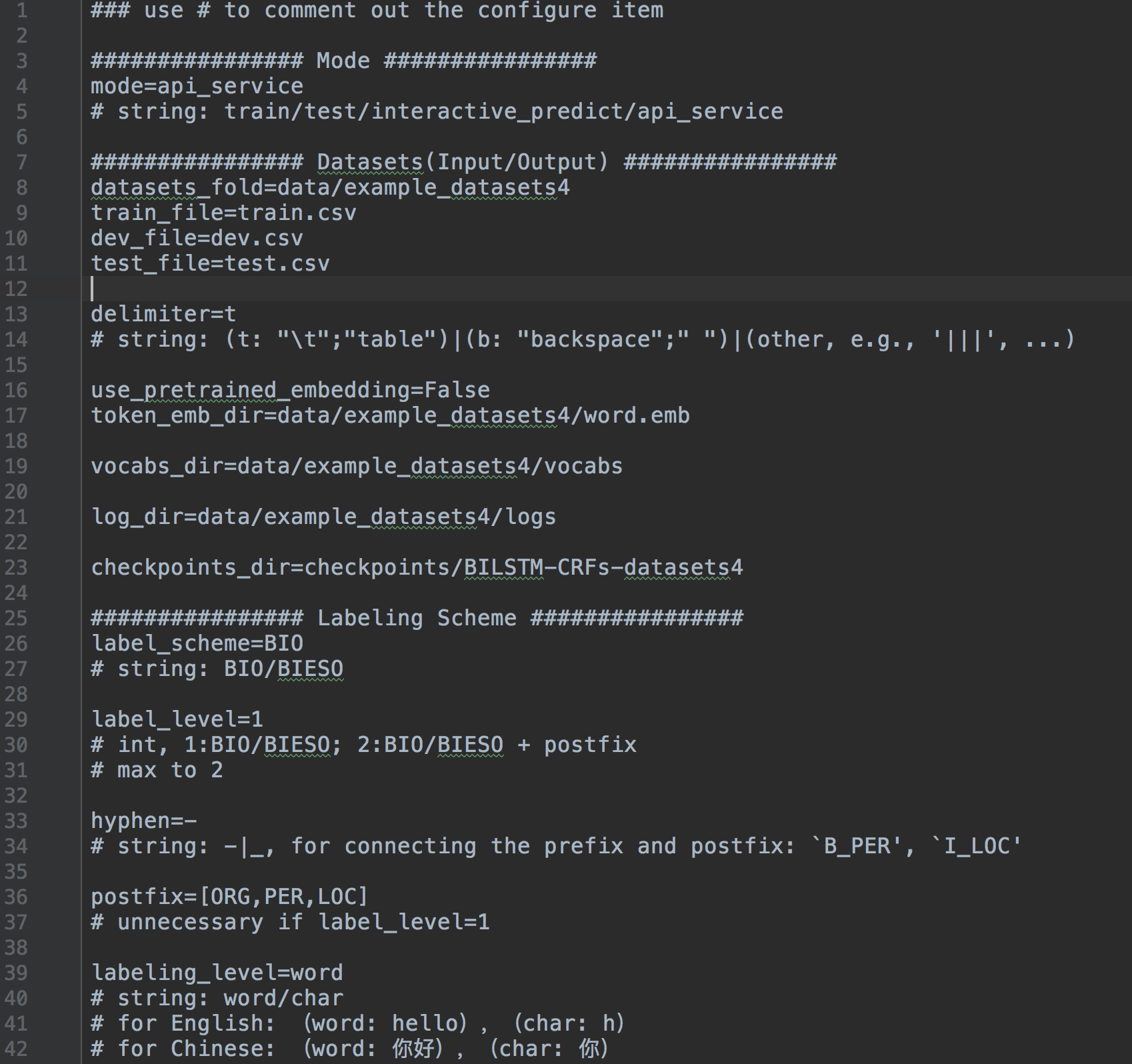
main.py 
main.py main.py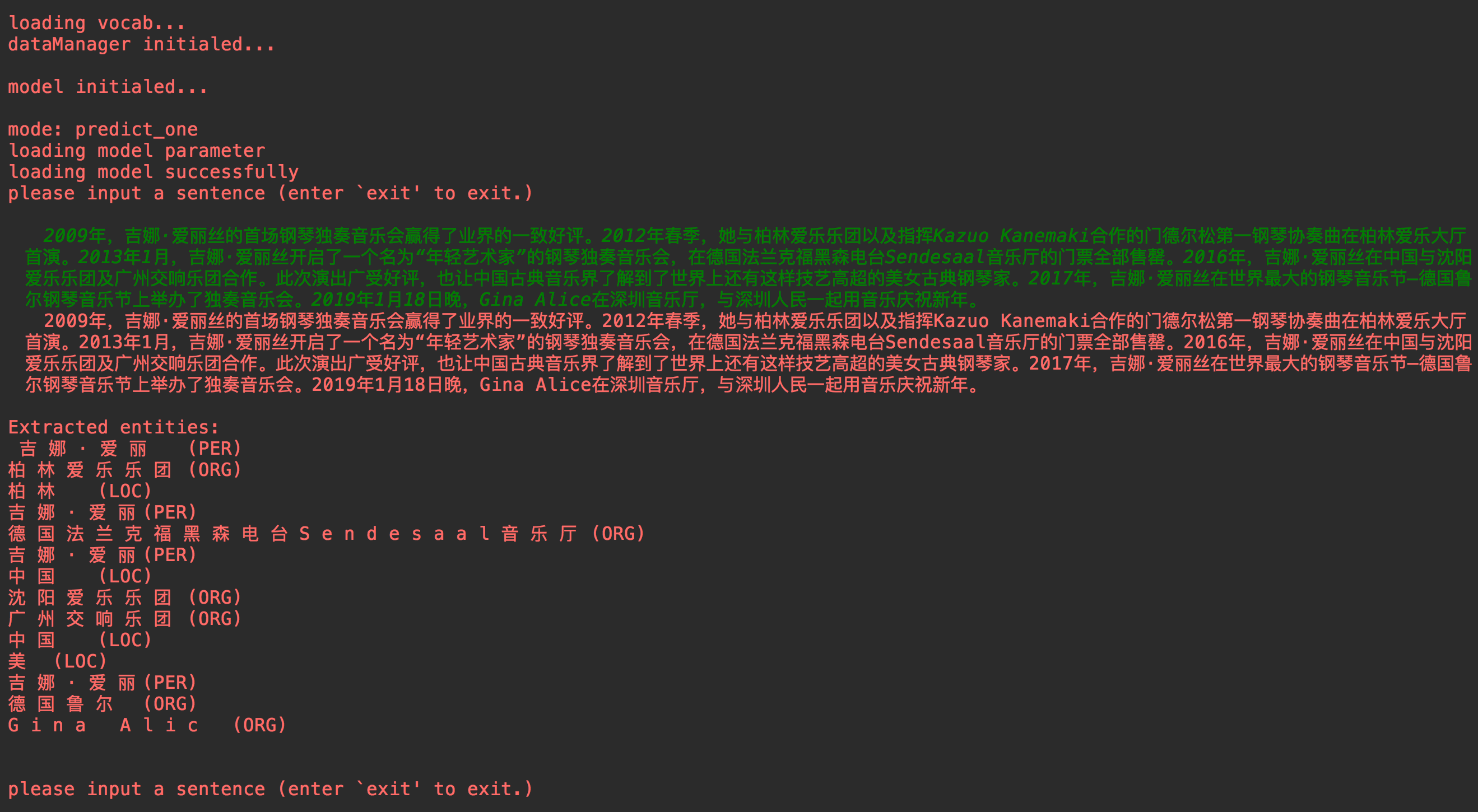
main.py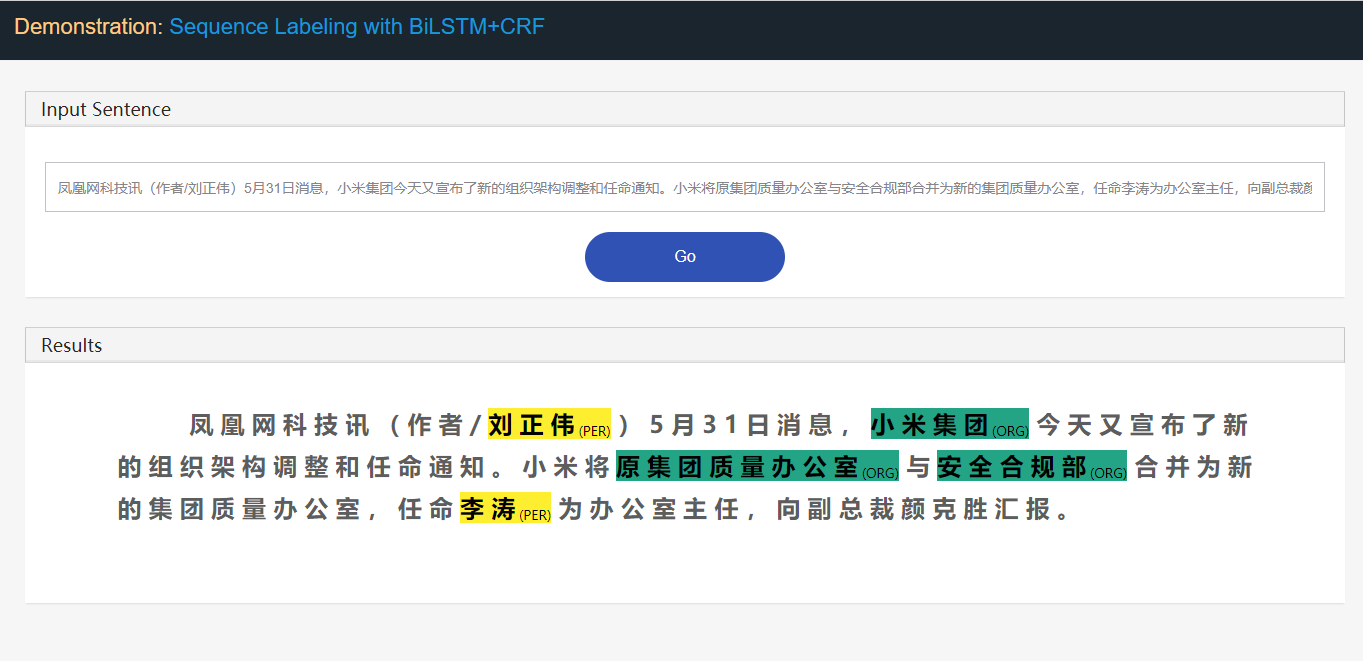
ชุดข้อมูลรวมถึง trainset, testset, devset เป็นสิ่งจำเป็นสำหรับการใช้งานโดยรวม อย่างไรก็ตามคุณเพียงต้องการฝึกอบรมแบบจำลองการใช้งานแบบออฟไลน์จำเป็นต้องใช้เฉพาะ Trainset เท่านั้น หลังจากการฝึกอบรมคุณสามารถอนุมานได้กับไฟล์จุดตรวจสอบรุ่นที่บันทึกไว้ หากคุณต้องการทำการทดสอบคุณควร
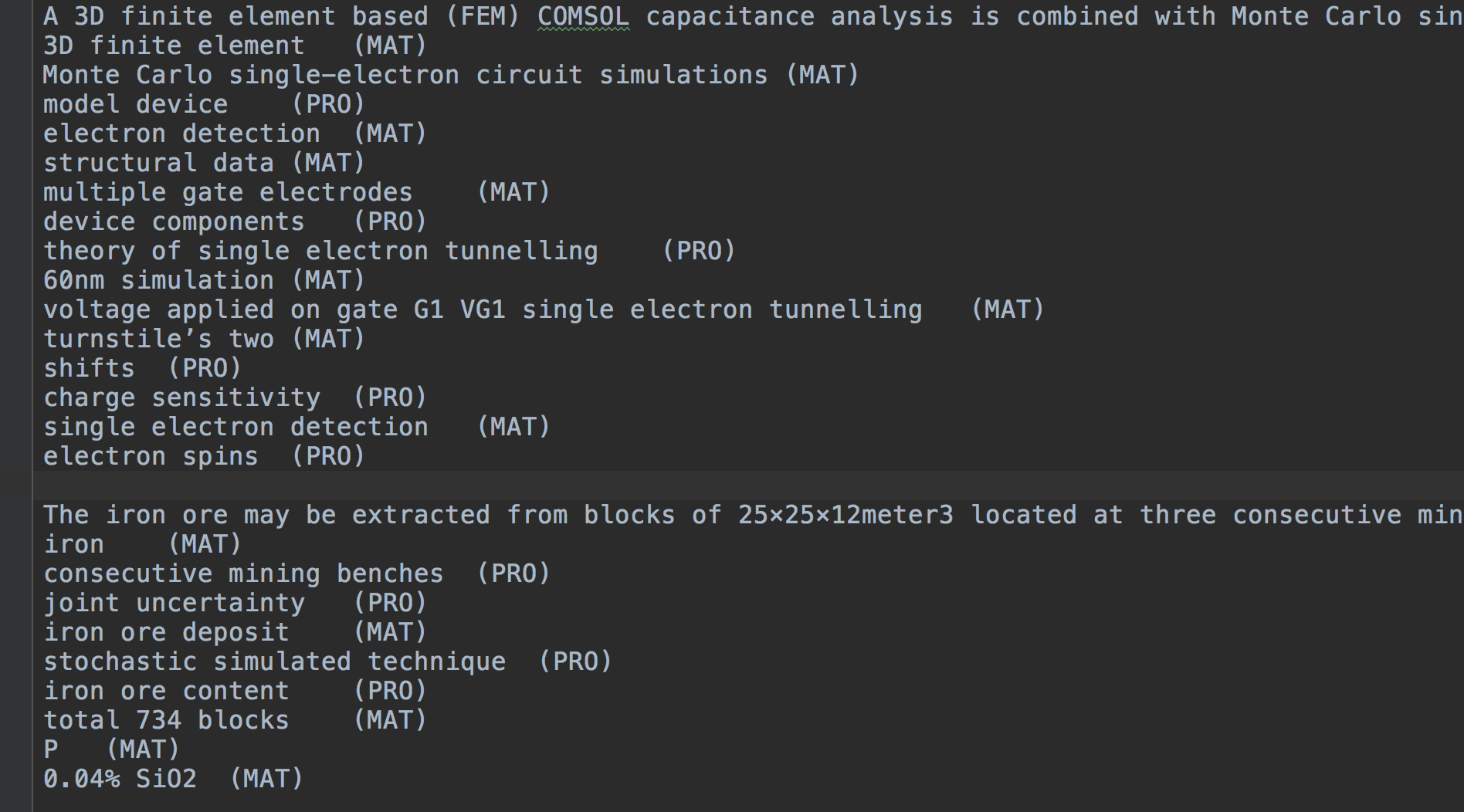
สำหรับ trainset , testset , devset , รูปแบบทั่วไปมีดังนี้:
(Token) (Label)
for O
the O
lattice B_TAS
QCD I_TAS
computation I_TAS
of I_TAS
nucleon–nucleon I_TAS
low-energy I_TAS
interactions E_TAS
. O
It O
consists O
in O
simulating B_PRO
...
(Token) (Label)
马 B-LOC
来 I-LOC
西 I-LOC
亚 I-LOC
副 O
总 O
理 O
。 O
他 O
兼 O
任 O
财 B-ORG
政 I-ORG
部 I-ORG
长 O
...
โปรดทราบว่า:
testset สามารถมีได้เฉพาะกับแถว Token ในระหว่างการทดสอบแบบจำลองจะส่งออกเอนทิตีที่คาดการณ์ไว้ตาม test.csv ไฟล์เอาท์พุทประกอบด้วยสอง: test.out , test.entity.out (ไม่บังคับ)
test.out
ด้วยการก่อตัวเดียวกันกับ test.csv อินพุต csv
test.entity.out
Sentence
entity1 (Type)
entity2 (Type)
entity3 (Type)
...
หากคุณต้องการปรับโครงการนี้ให้เข้ากับงานการติดฉลากลำดับเฉพาะของคุณเองคุณอาจต้องการเคล็ดลับต่อไปนี้
ดาวน์โหลดแหล่ง repo
รูปแบบการติดฉลาก (สำคัญที่สุด)
B_PER', i_loc' โมเดล: แก้ไขสถาปัตยกรรมโมเดลเป็นสิ่งที่คุณต้องการใน BiLSTM_CRFs.py
ชุดข้อมูล: ปรับให้เข้ากับชุดข้อมูลของคุณในรูปแบบที่ถูกต้อง
การฝึกอบรม
สำหรับรายละเอียดการใช้งานเพิ่มเติมโปรดอ้างถึงคู่มือ
คุณยินดีที่จะออกสิ่งผิดพลาด


