sequence labeling BiLSTM CRF
1.0.0
Une implémentation TensorFlow du modèle BILSTM + CRF, pour les tâches d'étiquetage des séquences.
Sequential labeling est une méthodologie typique modélisant les tâches de prédiction de séquence dans la PNL. Les tâches de marquage séquentielles courantes incluent, par exemple,
Prendre une tâche de reconnaissance d'entité nommée (NER) comme exemple:
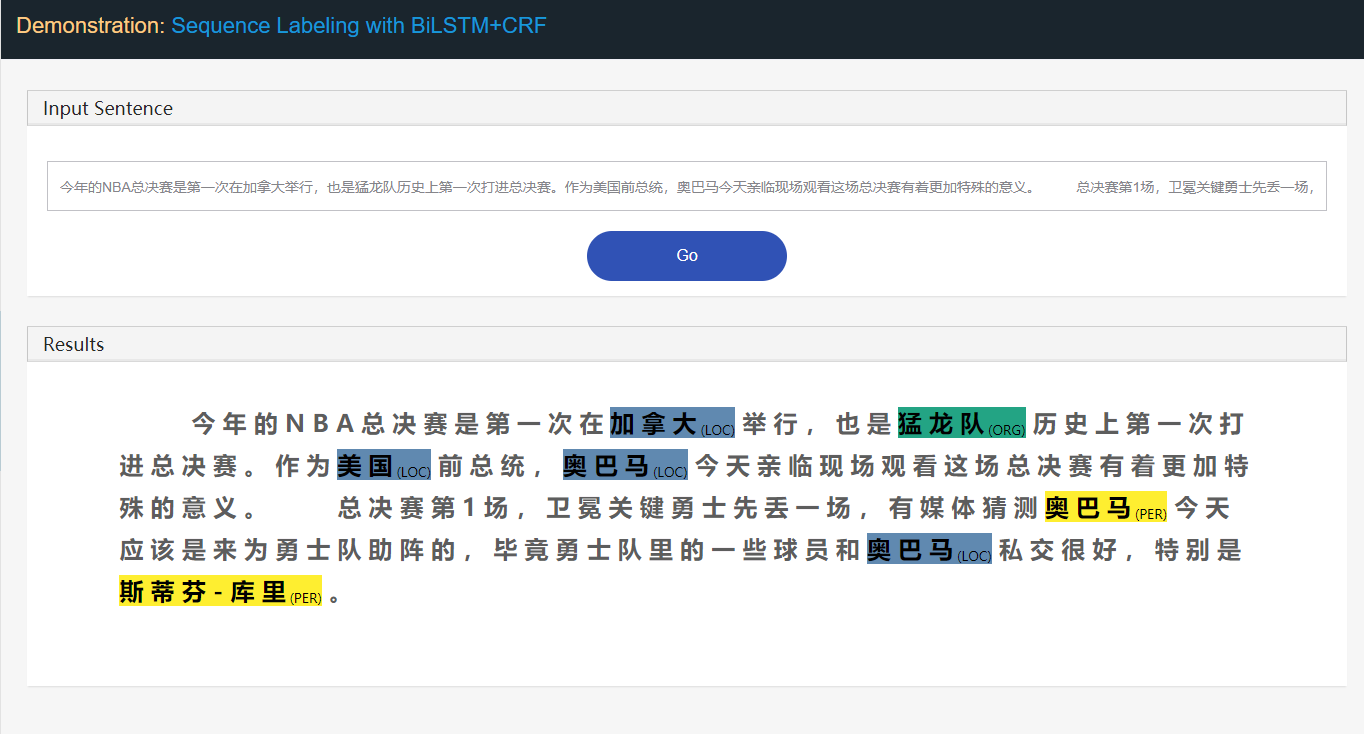
Stanford University located at California .
B-ORG I-ORG O O B-LOC O Ici, deux entités, Stanford University et California doivent être extraites. Et spécifiquement, chaque token dans le texte est tagué avec une label correspondante. Par exemple, { token : stanford , label : b-org }. Le modèle de marquage de séquence vise à prédire la séquence d'étiquettes, étant donné une séquence de jeton.
BiLSTM+CRF proposé par Lample et al., 2016, est jusqu'à présent le modèle neuronal le plus classique et le plus stable pour les tâches de marquage séquentielles. 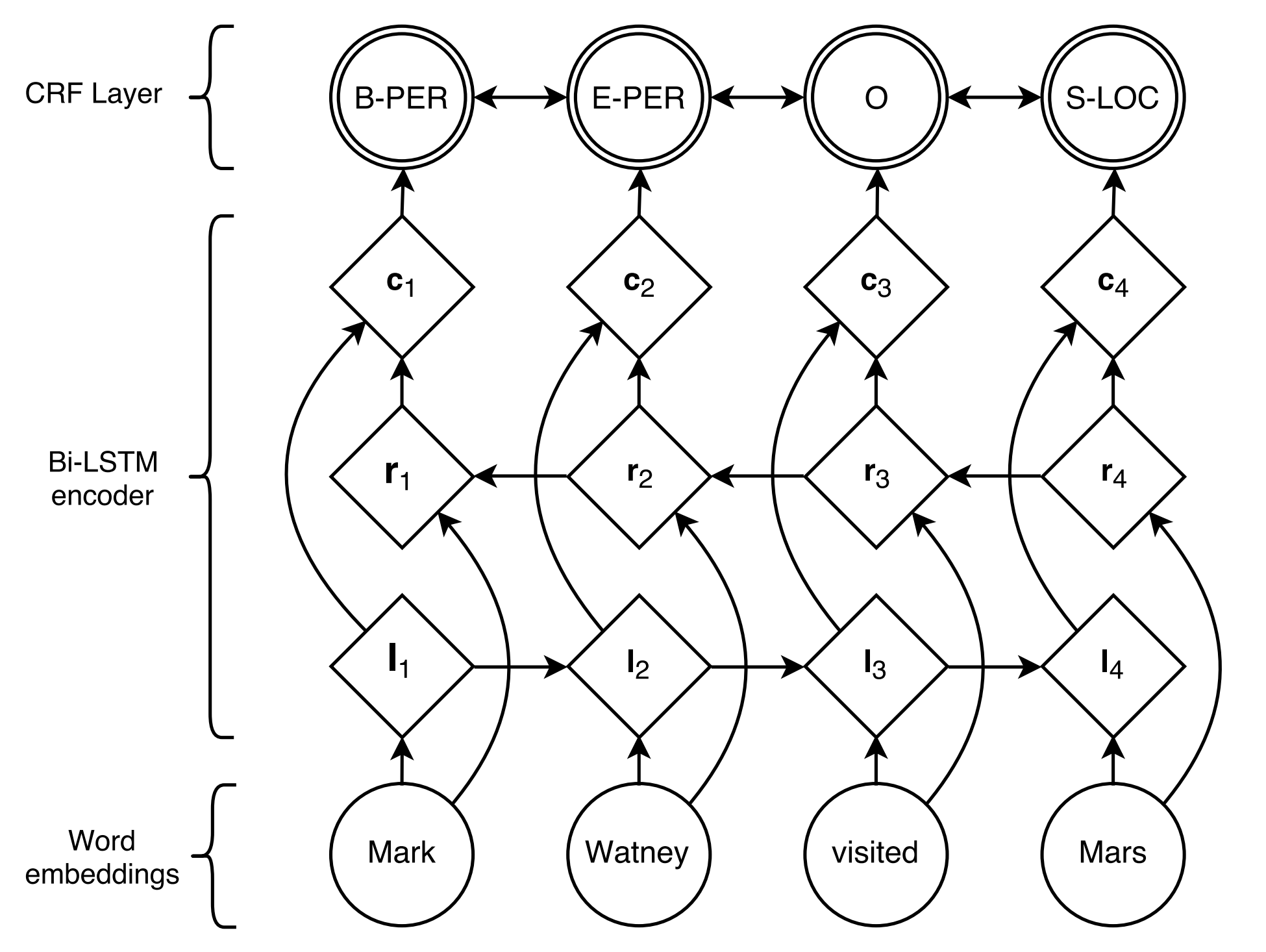
Configuration de tous les paramètres
train / test / interactive_predict / api_service ]BIO / BIESO ]PER | LOC | ORG ]Enregistrant tout
Demo d'application Web pour une démonstration facile
orienté objet: bilstm_crf, ensembles de données, configer, utils
Modularisé avec une structure claire, facile pour le bricolage.
Voir plus dans le manuel.
Téléchargez le dépôt pour une utilisation directe.
git clone https://github.com/scofield7419/sequence-labeling-BiLSTM-CRF.git
pip install -r requirements.txt
Installez le package BILSTM-CRF en tant que module.
pip install BiLSTM-CRF
usage:
from BiLSTM-CRF.engines.BiLSTM_CRFs import BiLSTM_CRFs as BC
from BiLSTM-CRF.engines.DataManager import DataManager
from BiLSTM-CRF.engines.Configer import Configer
from BiLSTM-CRF.engines.utils import get_logger
...
config_file = r'/home/projects/system.config'
configs = Configer(config_file)
logger = get_logger(configs.log_dir)
configs.show_data_summary(logger) # optional
dataManager = DataManager(configs, logger)
model = BC(configs, logger, dataManager)
###### mode == 'train':
model.train()
###### mode == 'test':
model.test()
###### mode == 'single predicting':
sentence_tokens, entities, entities_type, entities_index = model.predict_single(sentence)
if configs.label_level == 1:
print("nExtracted entities:n %snn" % ("n".join(entities)))
elif configs.label_level == 2:
print("nExtracted entities:n %snn" % ("n".join([a + "t(%s)" % b for a, b in zip(entities, entities_type)])))
###### mode == 'api service webapp':
cmd_new = r'cd demo_webapp; python manage.py runserver %s:%s' % (configs.ip, configs.port)
res = os.system(cmd_new)
open `ip:port` in your browser.
├── main.py
├── system.config
├── HandBook.md
├── README.md
│
├── checkpoints
│ ├── BILSTM-CRFs-datasets1
│ │ ├── checkpoint
│ │ └── ...
│ └── ...
├── data
│ ├── example_datasets1
│ │ ├── logs
│ │ ├── vocabs
│ │ ├── test.csv
│ │ ├── train.csv
│ │ └── dev.csv
│ └── ...
├── demo_webapp
│ ├── demo_webapp
│ ├── interface
│ └── manage.py
├── engines
│ ├── BiLSTM_CRFs.py
│ ├── Configer.py
│ ├── DataManager.py
│ └── utils.py
└── tools
├── calcu_measure_testout.py
└── statis.py
Plis
engines se replient, fournissant le PY fonctionnant de base.data-subfold de données sont placés.checkpoints-subfold , les points de contrôle du modèle sont stockés.demo_webapp Pold, nous pouvons démontrer le système dans le Web et fournir une API.tools se replient, fournissant des utils hors ligne.Fichiers
main.py est le fichier Python d'entrée du système.system.config est le fichier de configuration de tous les paramètres du système.HandBook.md fournit quelques instructions d'utilisation.BiLSTM_CRFs.py est le modèle principal.Configer.py analyse le system.config .DataManager.py gère les ensembles de données et la planification.utils.py fournit des outils sur la volée. Sous les étapes suivantes:
system.config .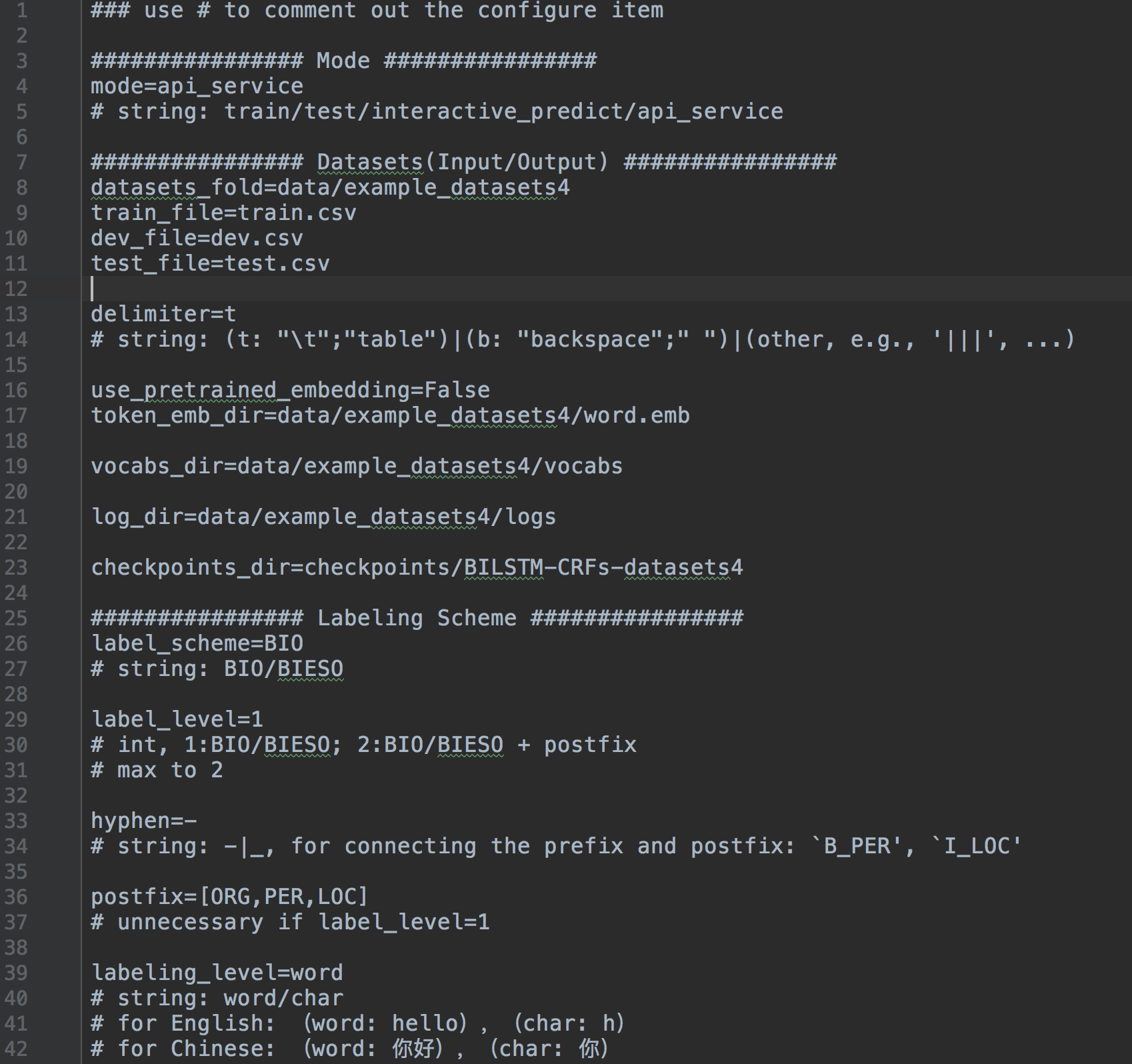
main.py 
main.py main.py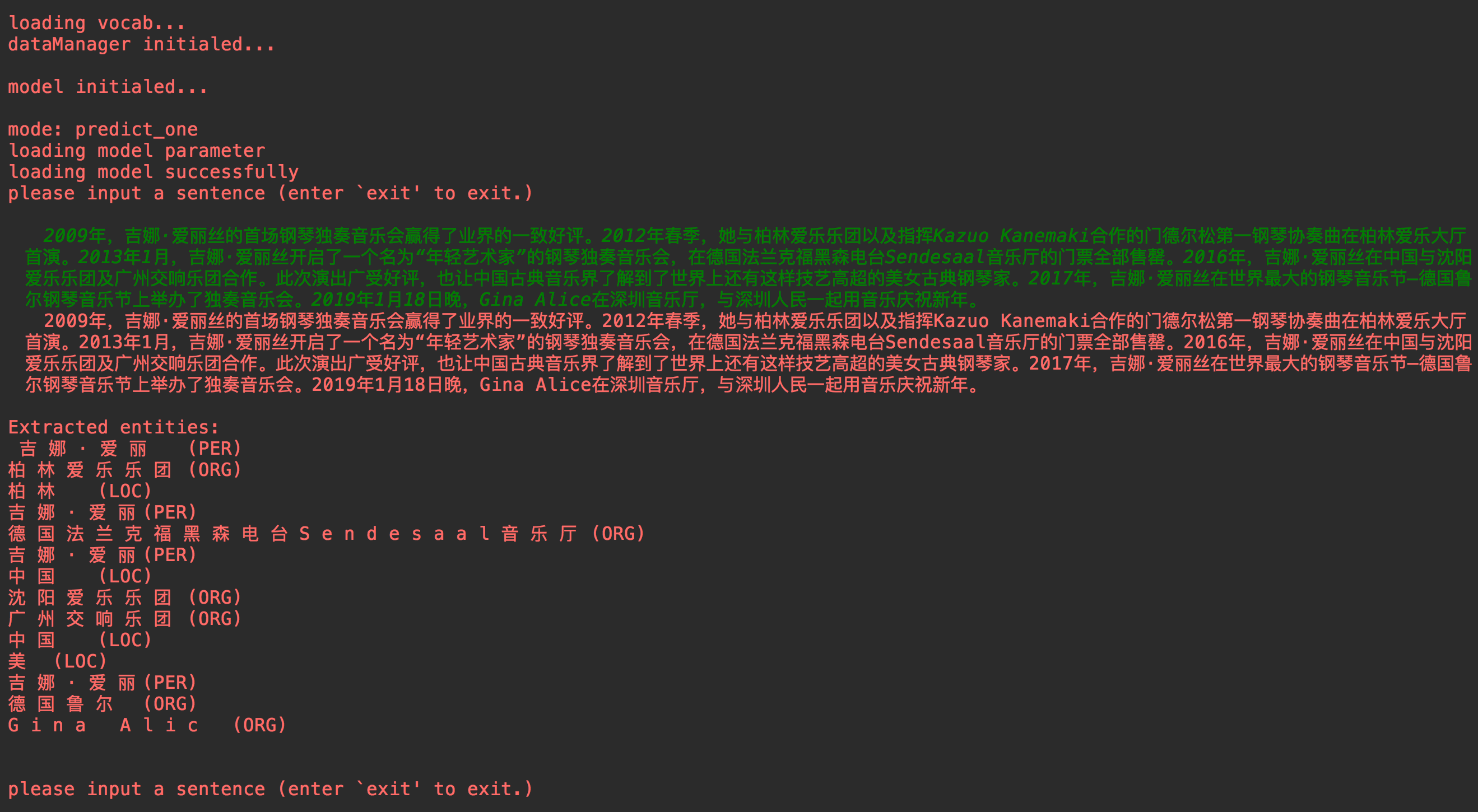
main.py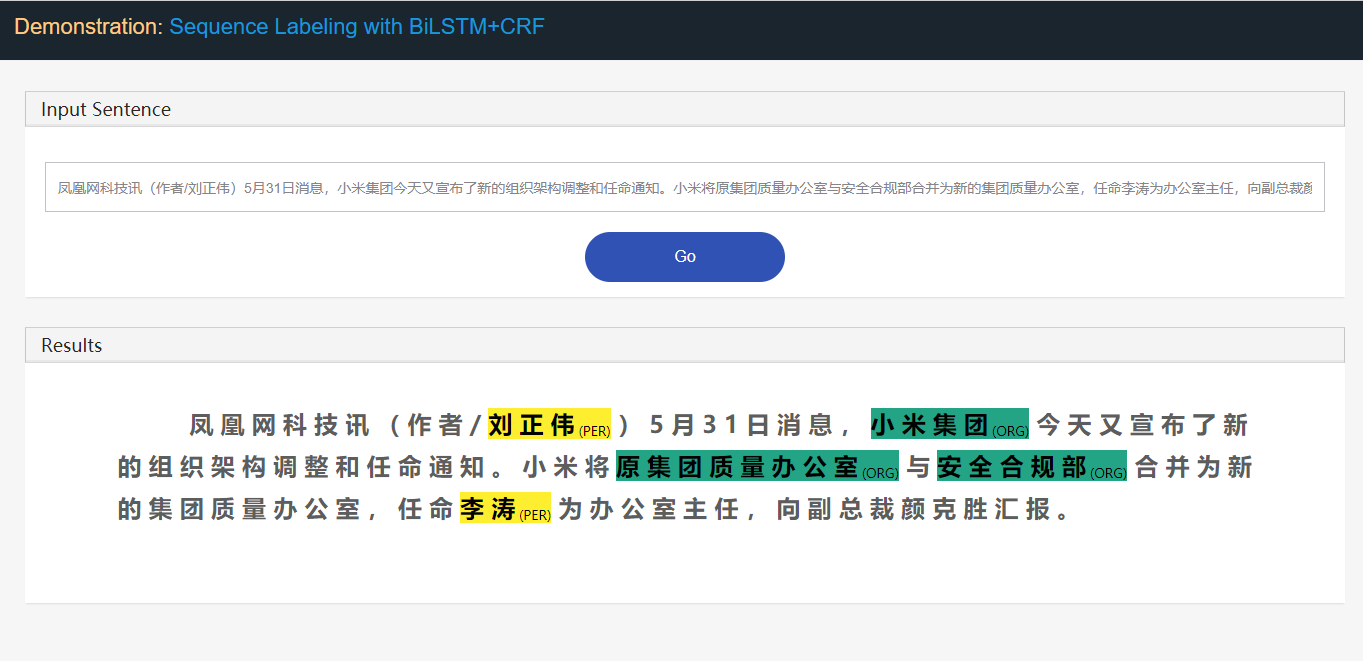
Des ensembles de données, notamment Trainset, TestSet, Devset sont nécessaires pour l'utilisation globale. Cependant, c'est que vous voulez seulement former le modèle l'utilisation hors ligne, seul le train est nécessaire. Après l'entraînement, vous pouvez faire une inférence avec les fichiers de point de contrôle du modèle enregistré. Si tu veux faire un test, tu devrais
Pour trainset , testset , devset , le format commun est le suivant:
(Token) (Label)
for O
the O
lattice B_TAS
QCD I_TAS
computation I_TAS
of I_TAS
nucleon–nucleon I_TAS
low-energy I_TAS
interactions E_TAS
. O
It O
consists O
in O
simulating B_PRO
...
(Token) (Label)
马 B-LOC
来 I-LOC
西 I-LOC
亚 I-LOC
副 O
总 O
理 O
。 O
他 O
兼 O
任 O
财 B-ORG
政 I-ORG
部 I-ORG
长 O
...
Noter que:
testset ne peut exister qu'avec la ligne Token . Pendant les tests, le modèle sortira les entités prévues en fonction du test.csv . Les fichiers de sortie incluent deux: test.out , test.entity.out (facultatif).
test.out
avec la même formation que test.csv entrée.csv.
test.entity.out
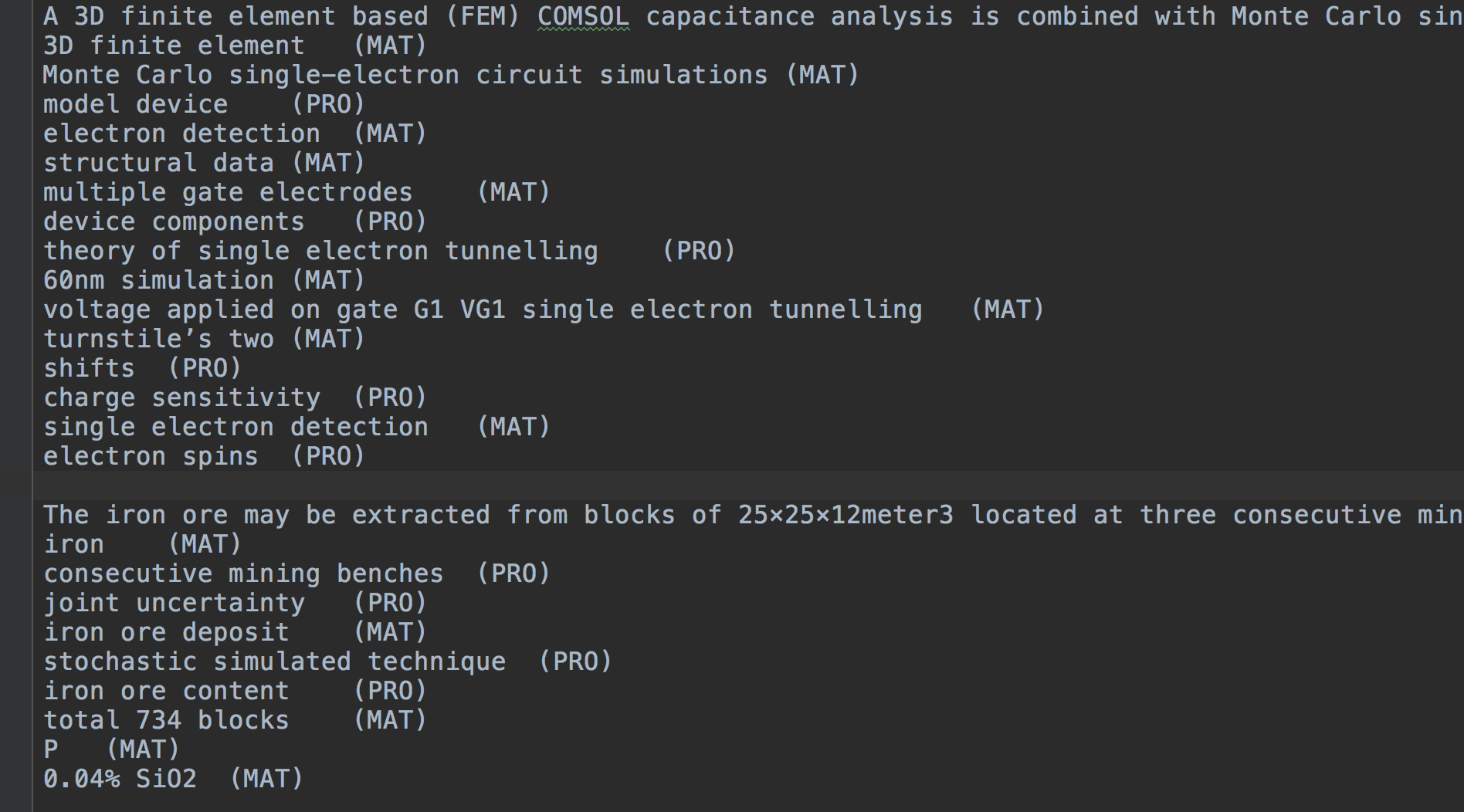
Sentence
entity1 (Type)
entity2 (Type)
entity3 (Type)
...
Si vous voulez adapter ce projet à votre propre tâche d'étiquetage de séquence spécifique, vous pouvez avoir besoin des conseils suivants.
Téléchargez les sources de dépôt.
Schéma d'étiquetage (le plus important)
B_PER', i_loc' Modèle: modifiez l'architecture du modèle dans celle que vous vouliez, dans BiLSTM_CRFs.py .
Ensemble de données: s'adaptez à votre ensemble de données, dans la formation correcte.
Entraînement
Pour plus de détails d'utilisation, veuillez se référer au manuel
Vous êtes accueilli pour émettre quelque chose de mal.


