sequence labeling BiLSTM CRF
1.0.0
Uma implementação do tensorflow do modelo BILSTM+CRF, para tarefas de rotulagem de sequência.
Sequential labeling é uma metodologia típica que modela as tarefas de previsão de sequência na PNL. Tarefas de rotulagem seqüenciais comuns incluem, por exemplo,
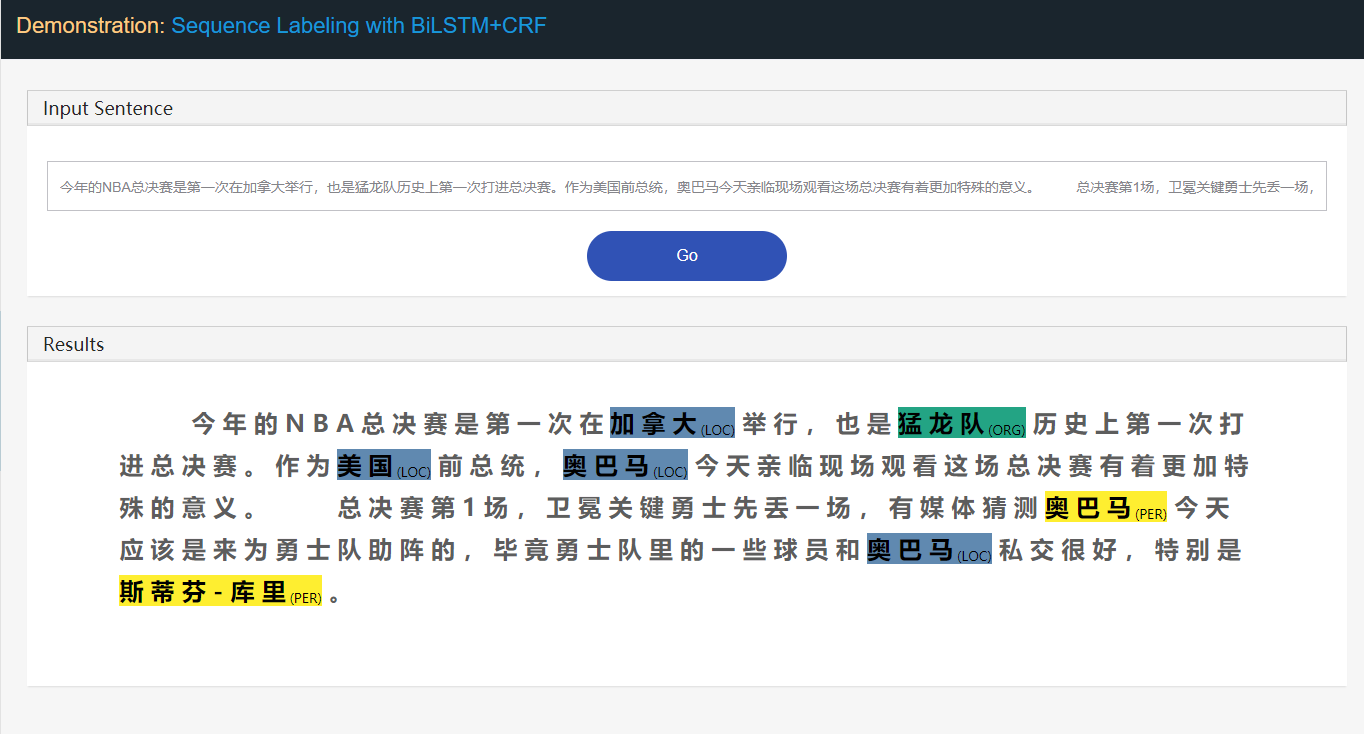
Tomando a tarefa de reconhecimento de entidade nomeado (NER) como exemplo:
Stanford University located at California .
B-ORG I-ORG O O B-LOC O Aqui, duas entidades, Stanford University e California devem ser extraídas. E especificamente, cada token no texto é marcado com um label correspondente. Por exemplo, { token : Stanford , label : B-Org }. O modelo de marcação de sequência visa prever a sequência do rótulo, dada uma sequência de token.
BiLSTM+CRF proposto por Lample et al., 2016, é até agora o modelo neural mais clássico e estável para tarefas de marcação seqüencial. 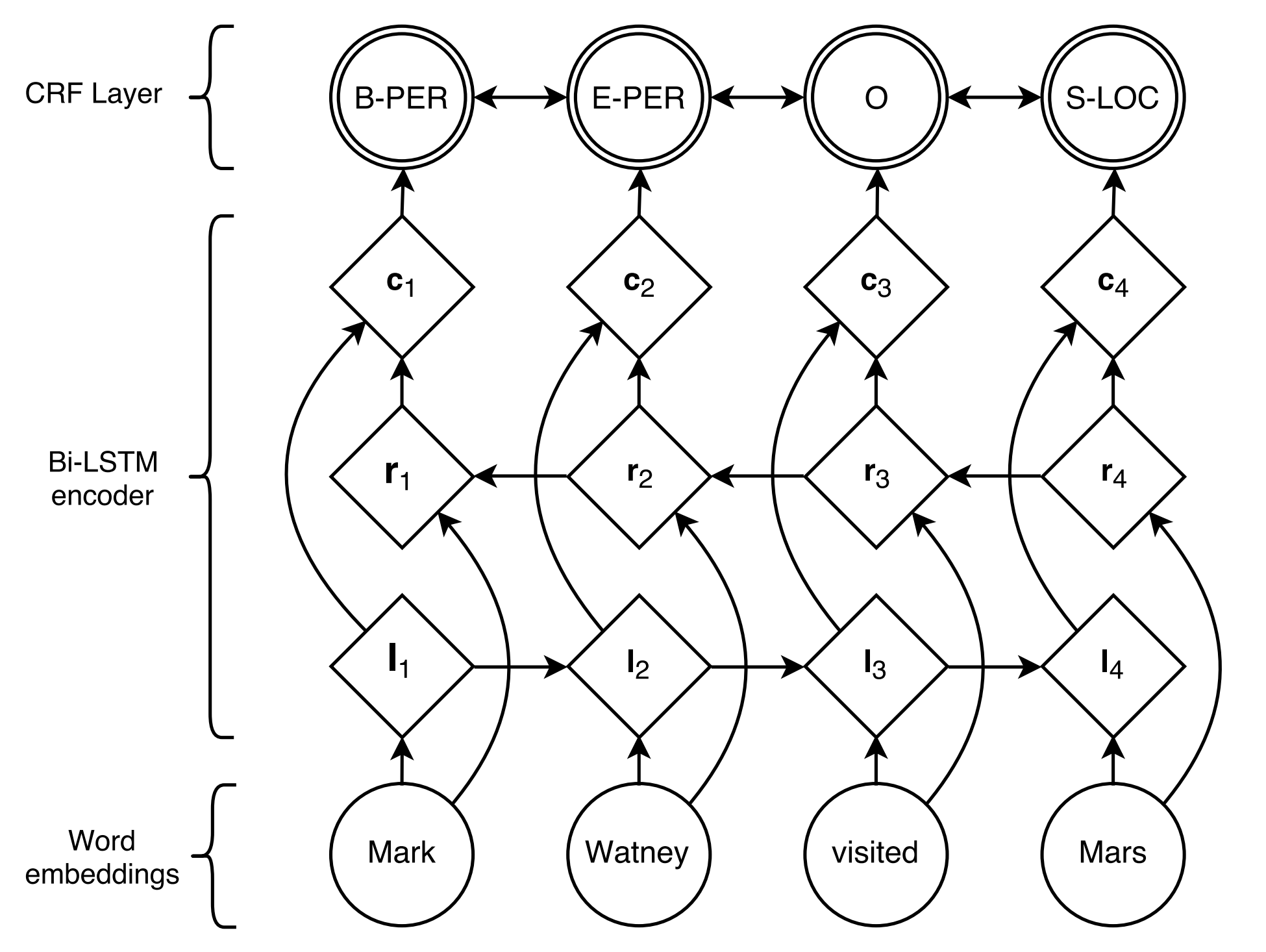
definindo todas as configurações
train / test / interactive_predict / api_service ]BIO / BIESO ]PER | LOC | ORG ]registrando tudo
demonstração de aplicativos da web para facilitar a demonstração
Orientado para objetos: bilstm_crf, conjuntos de dados, configer, utils
Modularizado com estrutura clara, fácil para DIY.
Veja mais no manual.
Faça o download do repo para uso diretamente.
git clone https://github.com/scofield7419/sequence-labeling-BiLSTM-CRF.git
pip install -r requirements.txt
Instale o pacote BILSTM-CRF como um módulo.
pip install BiLSTM-CRF
uso:
from BiLSTM-CRF.engines.BiLSTM_CRFs import BiLSTM_CRFs as BC
from BiLSTM-CRF.engines.DataManager import DataManager
from BiLSTM-CRF.engines.Configer import Configer
from BiLSTM-CRF.engines.utils import get_logger
...
config_file = r'/home/projects/system.config'
configs = Configer(config_file)
logger = get_logger(configs.log_dir)
configs.show_data_summary(logger) # optional
dataManager = DataManager(configs, logger)
model = BC(configs, logger, dataManager)
###### mode == 'train':
model.train()
###### mode == 'test':
model.test()
###### mode == 'single predicting':
sentence_tokens, entities, entities_type, entities_index = model.predict_single(sentence)
if configs.label_level == 1:
print("nExtracted entities:n %snn" % ("n".join(entities)))
elif configs.label_level == 2:
print("nExtracted entities:n %snn" % ("n".join([a + "t(%s)" % b for a, b in zip(entities, entities_type)])))
###### mode == 'api service webapp':
cmd_new = r'cd demo_webapp; python manage.py runserver %s:%s' % (configs.ip, configs.port)
res = os.system(cmd_new)
open `ip:port` in your browser.
├── main.py
├── system.config
├── HandBook.md
├── README.md
│
├── checkpoints
│ ├── BILSTM-CRFs-datasets1
│ │ ├── checkpoint
│ │ └── ...
│ └── ...
├── data
│ ├── example_datasets1
│ │ ├── logs
│ │ ├── vocabs
│ │ ├── test.csv
│ │ ├── train.csv
│ │ └── dev.csv
│ └── ...
├── demo_webapp
│ ├── demo_webapp
│ ├── interface
│ └── manage.py
├── engines
│ ├── BiLSTM_CRFs.py
│ ├── Configer.py
│ ├── DataManager.py
│ └── utils.py
└── tools
├── calcu_measure_testout.py
└── statis.py
Dobras
engines , fornecendo o núcleo que funcionava.data-subfold , os conjuntos de dados são colocados.checkpoints-subfold , os pontos de verificação do modelo são armazenados.demo_webapp Fold, podemos demonstrar o sistema na Web e fornecer API.tools dobradas, fornecendo alguns utilitários offline.Arquivos
main.py é o arquivo python de entrada para o sistema.system.config é o arquivo de configuração de todas as configurações do sistema.HandBook.md fornece algumas instruções de uso.BiLSTM_CRFs.py é o modelo principal.Configer.py analisa o system.config .DataManager.py gerencia os conjuntos de dados e agendamento.utils.py fornece nas ferramentas de mosca. Sob as seguintes etapas:
system.config .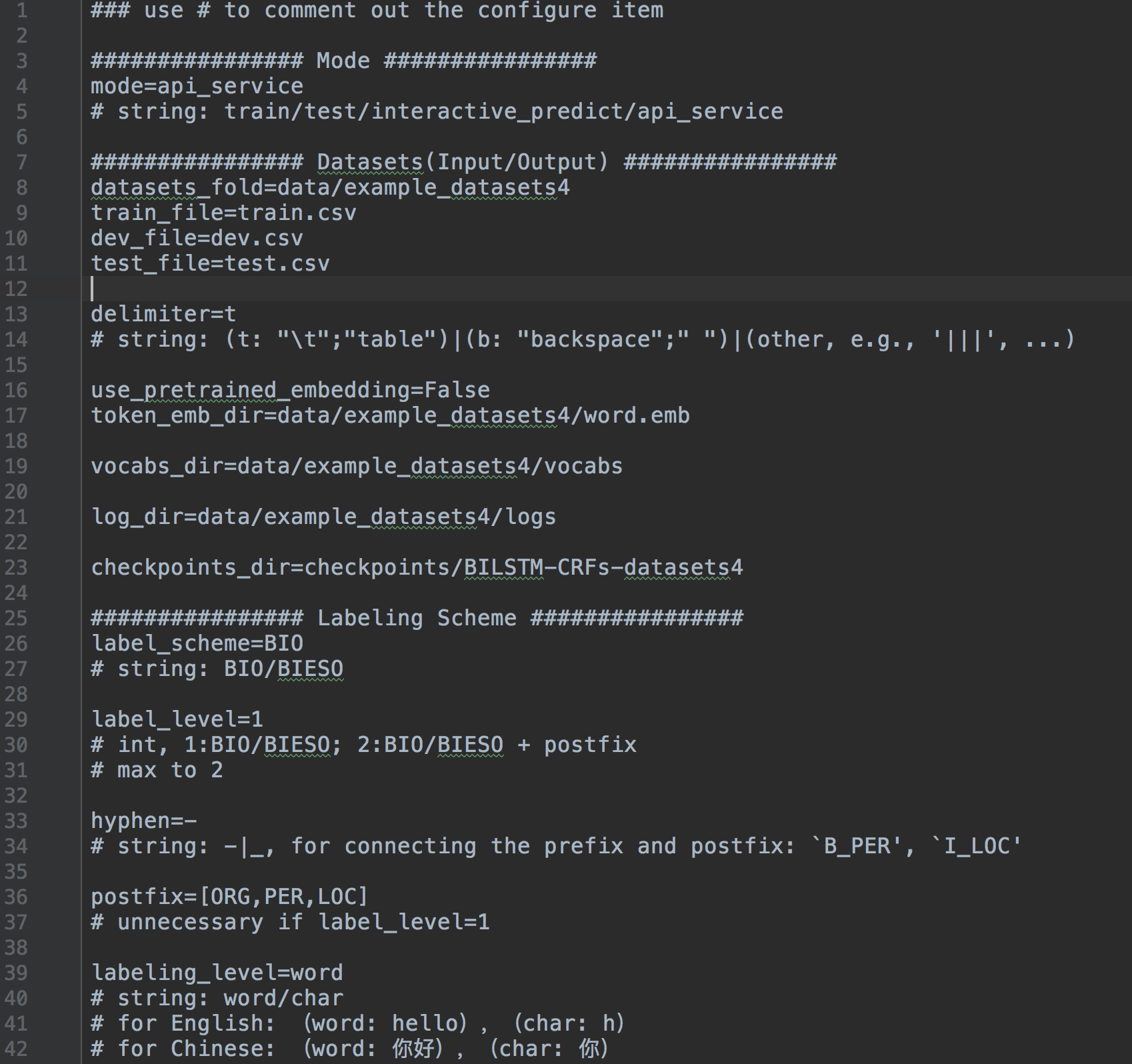
main.py 
main.py main.py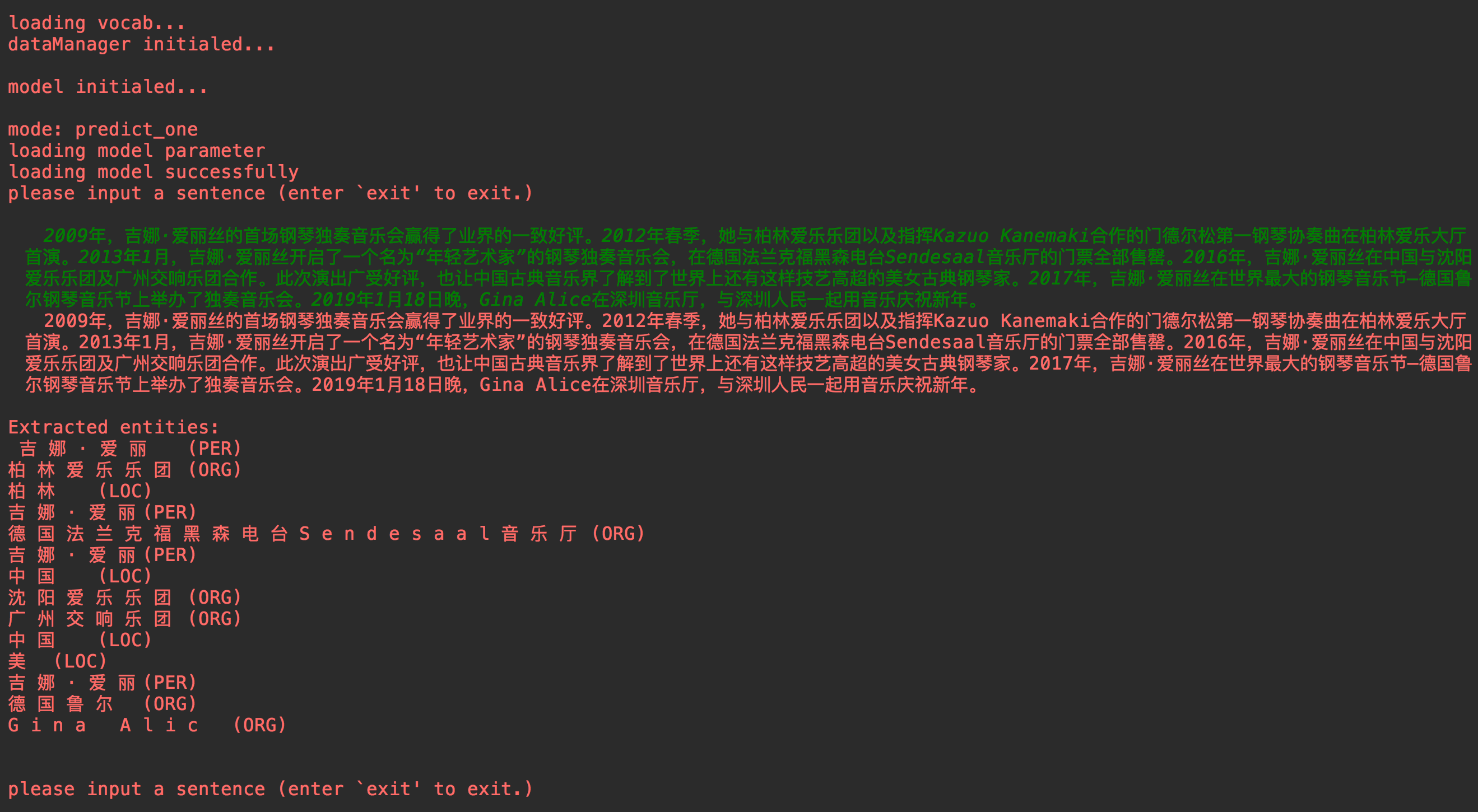
main.py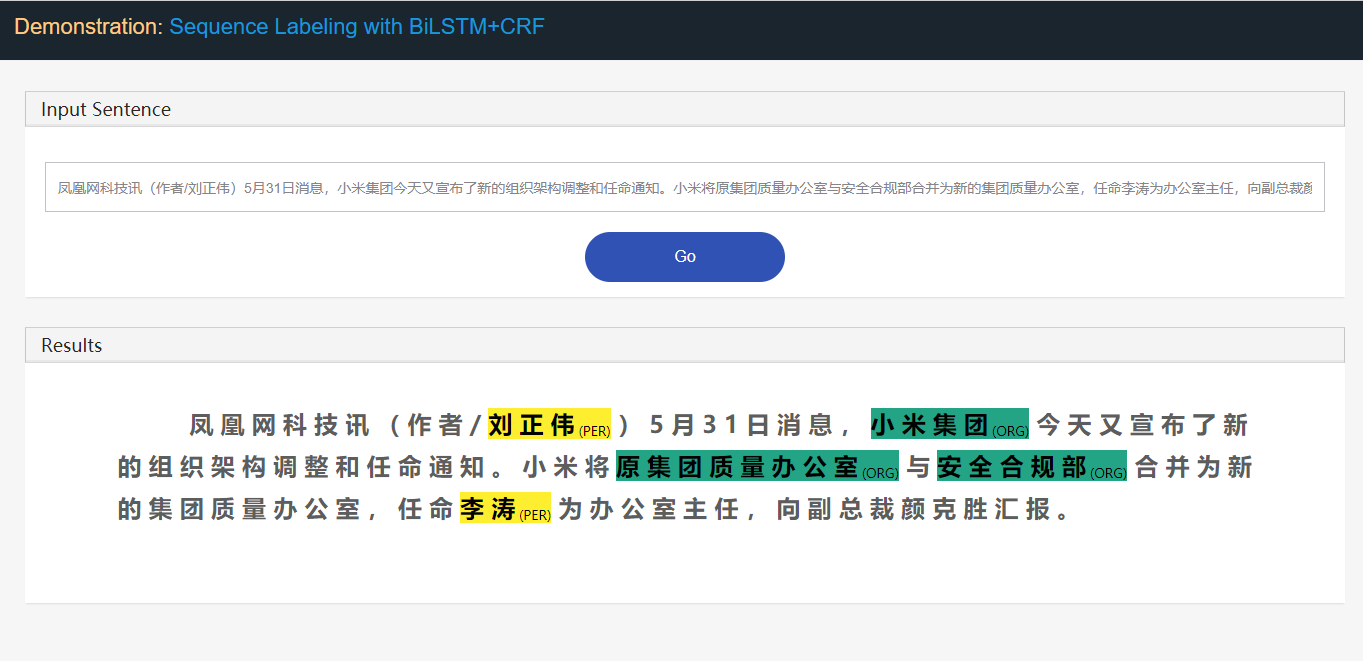
Os conjuntos de dados, incluindo Trainset, TestSet, Devset, são necessários para o uso geral. No entanto, você só quer treinar o modelo o usá -lo offline, apenas o trem é necessário. Após o treinamento, você pode ingerir os arquivos de ponto de verificação do modelo salvo. Se você quiser fazer um teste, você deveria
Para trainset , testset , devset , o formato comum é o seguinte:
(Token) (Label)
for O
the O
lattice B_TAS
QCD I_TAS
computation I_TAS
of I_TAS
nucleon–nucleon I_TAS
low-energy I_TAS
interactions E_TAS
. O
It O
consists O
in O
simulating B_PRO
...
(Token) (Label)
马 B-LOC
来 I-LOC
西 I-LOC
亚 I-LOC
副 O
总 O
理 O
。 O
他 O
兼 O
任 O
财 B-ORG
政 I-ORG
部 I-ORG
长 O
...
Observe que:
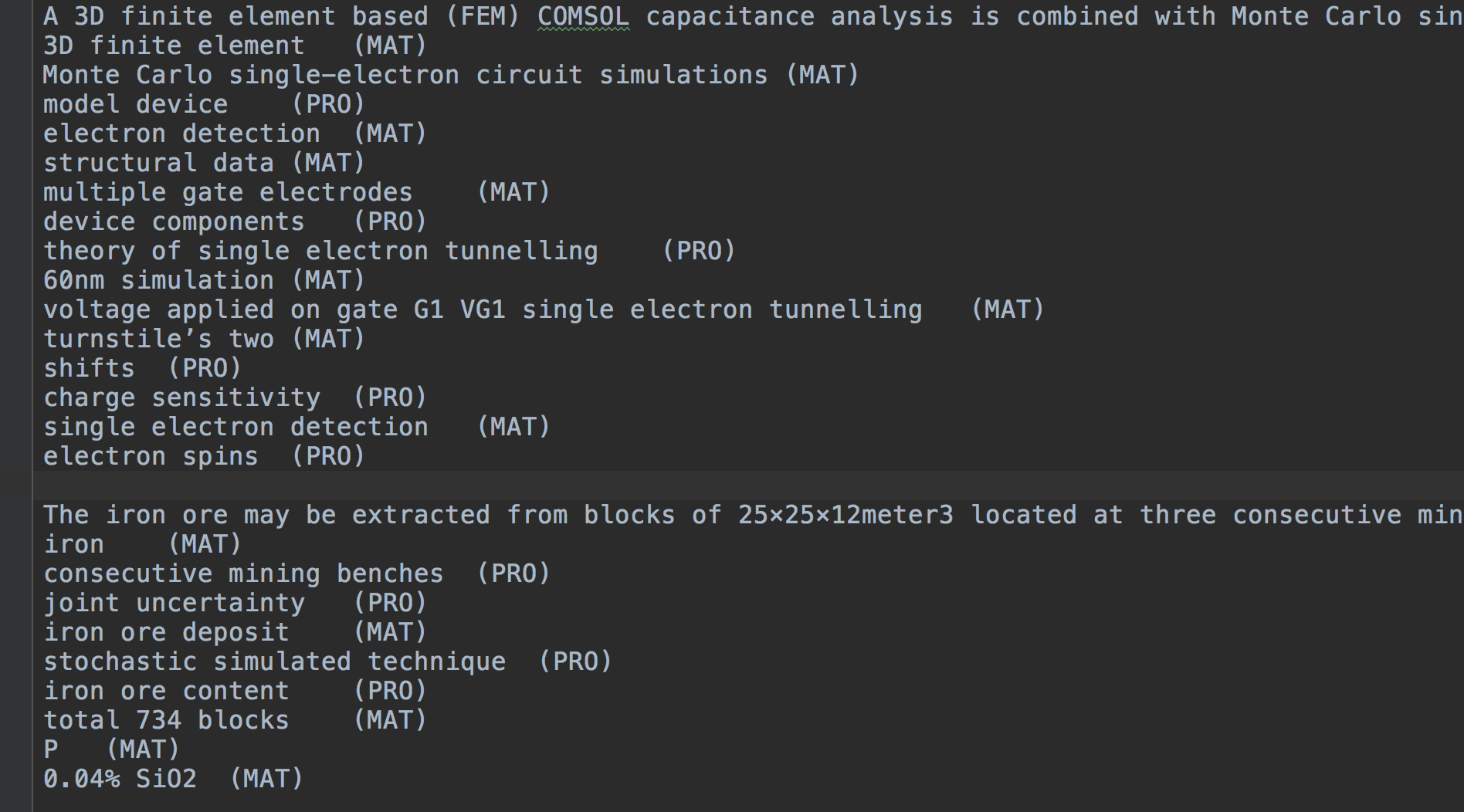
testset só pode existir com a linha Token . Durante o teste, o modelo produzirá as entidades previstas com base no test.csv . Os arquivos de saída incluem dois: test.out , test.entity.out (opcional).
test.out
com a mesma formação que test.csv de entrada.csv.
test.entity.out
Sentence
entity1 (Type)
entity2 (Type)
entity3 (Type)
...
Se você deseja adaptar este projeto à sua própria tarefa de rotulagem de sequência específica, pode precisar das seguintes dicas.
Faça o download das fontes de repo.
Esquema de rotulagem (mais importante)
B_PER', i_loc' Modelo: modifique a arquitetura do modelo naquele que você queria, em BiLSTM_CRFs.py .
Conjunto de dados: adapte -se ao seu conjunto de dados, na formação correta.
Treinamento
Para mais detalhes de uso, refere -se ao manual
Você é bem -vindo para emitir algo errado.


