sequence labeling BiLSTM CRF
1.0.0
Una implementación de TensorFlow del modelo BILSTM+CRF, para tareas de etiquetado de secuencia.
Sequential labeling es una metodología típica que modela las tareas de predicción de secuencia en PNL. Las tareas de etiquetado secuencial comunes incluyen, por ejemplo,
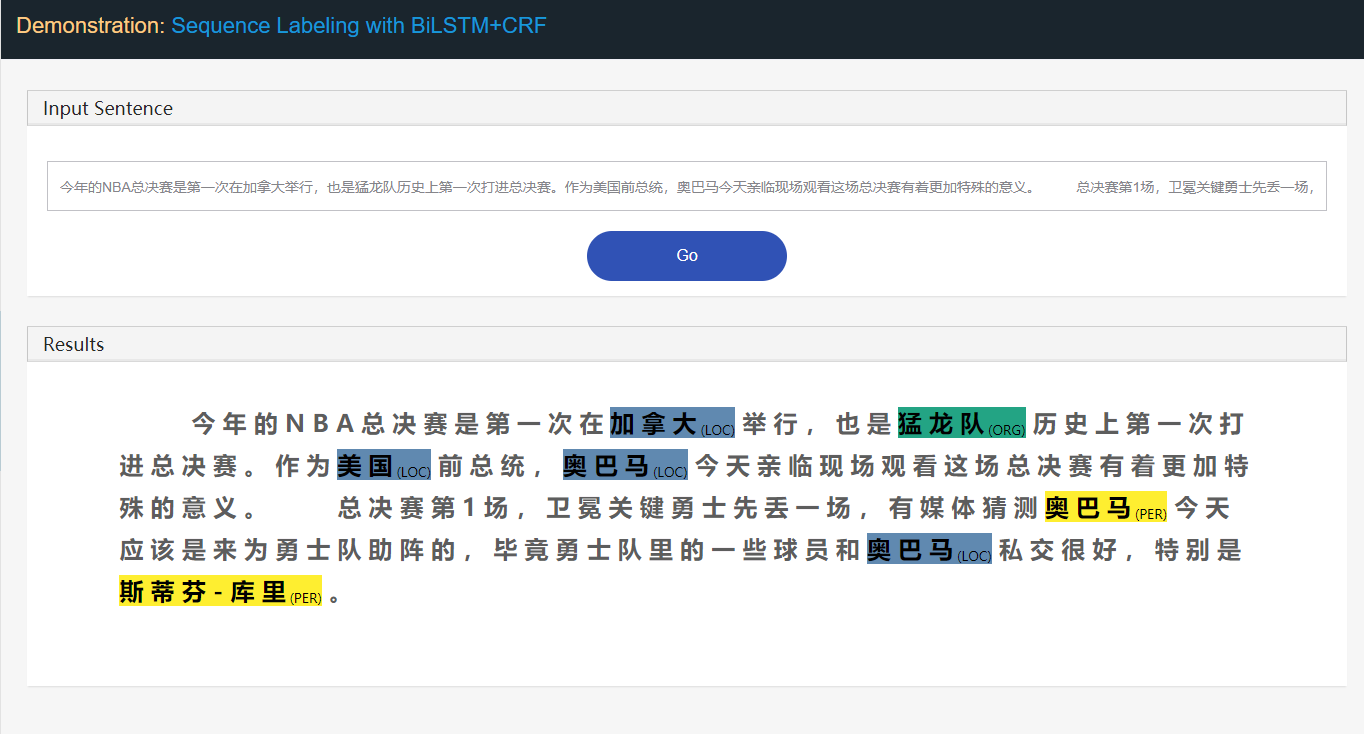
Tomar la tarea de reconocimiento de entidad nombrada (NER) como ejemplo:
Stanford University located at California .
B-ORG I-ORG O O B-LOC O Aquí, se extraerán dos entidades, Stanford University y California . Y específicamente, cada token en el texto está etiquetado con una label correspondiente. Por ejemplo, { token : Stanford , label : B-ORG }. El modelo de etiquetado de secuencia tiene como objetivo predecir la secuencia de la etiqueta, dada una secuencia de token.
BiLSTM+CRF propuesto por Lampra et al., 2016, es hasta ahora el modelo neuronal más clásico y estable para tareas de etiquetado secuencial. 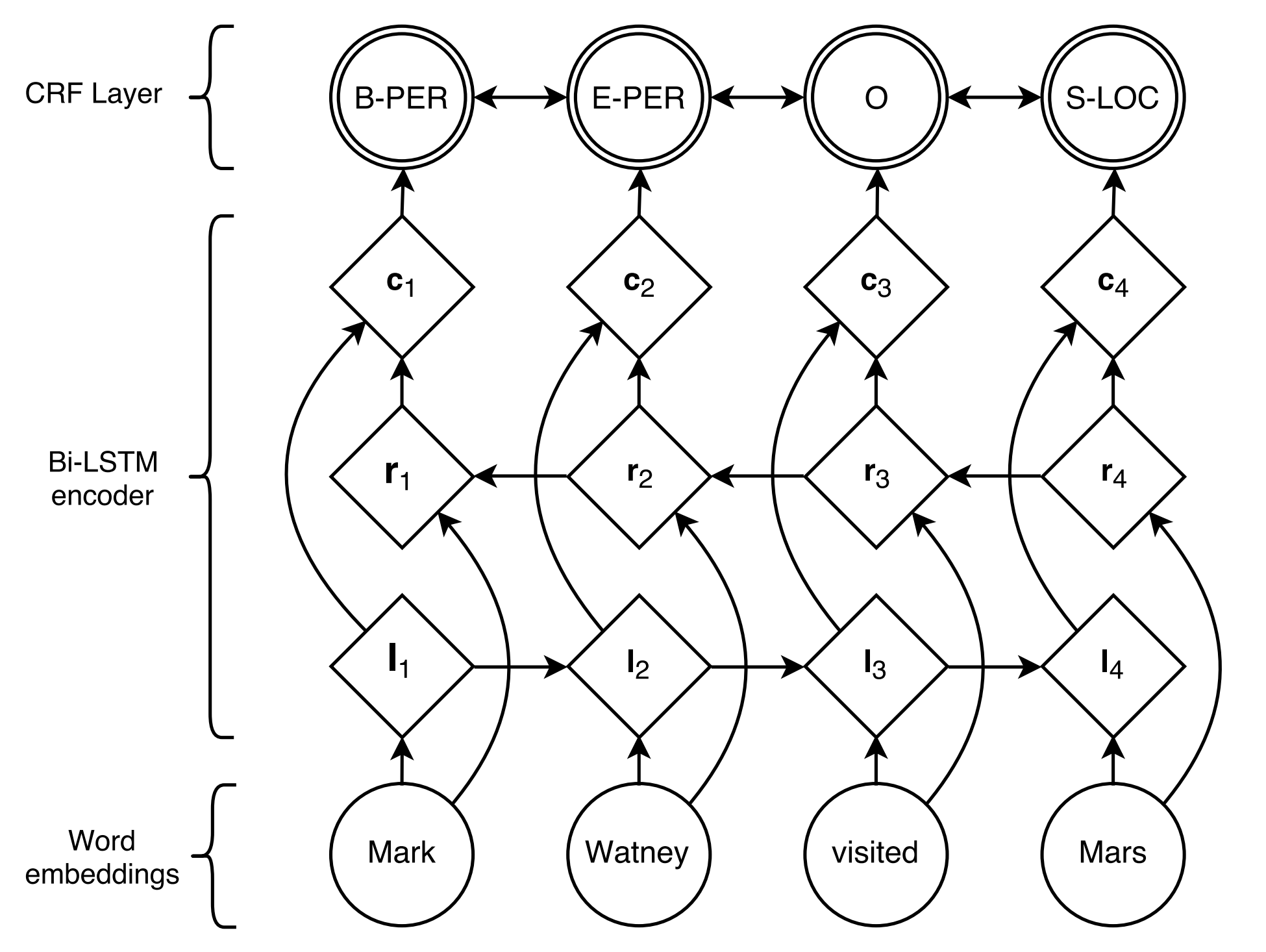
Configuración de todas las configuraciones
train / test / interactive_predict / api_service ]BIO / BIESO ]PER | LOC | ORG ]Registro de todo
demostración de la aplicación web para fácil demostración
Orientado a objetos: bilstm_crf, conjuntos de datos, configra, utiliza
modularizado con estructura clara, fácil para bricolaje.
Ver más en el manual.
Descargue el repositorio para usar directamente.
git clone https://github.com/scofield7419/sequence-labeling-BiLSTM-CRF.git
pip install -r requirements.txt
Instale el paquete BILSTM-CRF como un módulo.
pip install BiLSTM-CRF
uso:
from BiLSTM-CRF.engines.BiLSTM_CRFs import BiLSTM_CRFs as BC
from BiLSTM-CRF.engines.DataManager import DataManager
from BiLSTM-CRF.engines.Configer import Configer
from BiLSTM-CRF.engines.utils import get_logger
...
config_file = r'/home/projects/system.config'
configs = Configer(config_file)
logger = get_logger(configs.log_dir)
configs.show_data_summary(logger) # optional
dataManager = DataManager(configs, logger)
model = BC(configs, logger, dataManager)
###### mode == 'train':
model.train()
###### mode == 'test':
model.test()
###### mode == 'single predicting':
sentence_tokens, entities, entities_type, entities_index = model.predict_single(sentence)
if configs.label_level == 1:
print("nExtracted entities:n %snn" % ("n".join(entities)))
elif configs.label_level == 2:
print("nExtracted entities:n %snn" % ("n".join([a + "t(%s)" % b for a, b in zip(entities, entities_type)])))
###### mode == 'api service webapp':
cmd_new = r'cd demo_webapp; python manage.py runserver %s:%s' % (configs.ip, configs.port)
res = os.system(cmd_new)
open `ip:port` in your browser.
├── main.py
├── system.config
├── HandBook.md
├── README.md
│
├── checkpoints
│ ├── BILSTM-CRFs-datasets1
│ │ ├── checkpoint
│ │ └── ...
│ └── ...
├── data
│ ├── example_datasets1
│ │ ├── logs
│ │ ├── vocabs
│ │ ├── test.csv
│ │ ├── train.csv
│ │ └── dev.csv
│ └── ...
├── demo_webapp
│ ├── demo_webapp
│ ├── interface
│ └── manage.py
├── engines
│ ├── BiLSTM_CRFs.py
│ ├── Configer.py
│ ├── DataManager.py
│ └── utils.py
└── tools
├── calcu_measure_testout.py
└── statis.py
Pliegues
engines pliegue, proporcionando el núcleo funcionando PY.data-subfold , se colocan los conjuntos de datos.checkpoints-subfold pliegue, los puntos de control del modelo se almacenan.demo_webapp Fold, podemos demostrar el sistema en la web y proporciona API.tools pliegue, proporcionando algunos utilizados fuera de línea.Archivos
main.py es el archivo de entrada de Python para el sistema.system.config es el archivo Configurar para todas las configuraciones del sistema.HandBook.md proporciona algunas instrucciones de uso.BiLSTM_CRFs.py es el modelo principal.Configer.py analiza el system.config .DataManager.py administra los conjuntos de datos y la programación.utils.py proporciona en las herramientas de moscas. En los siguientes pasos:
system.config .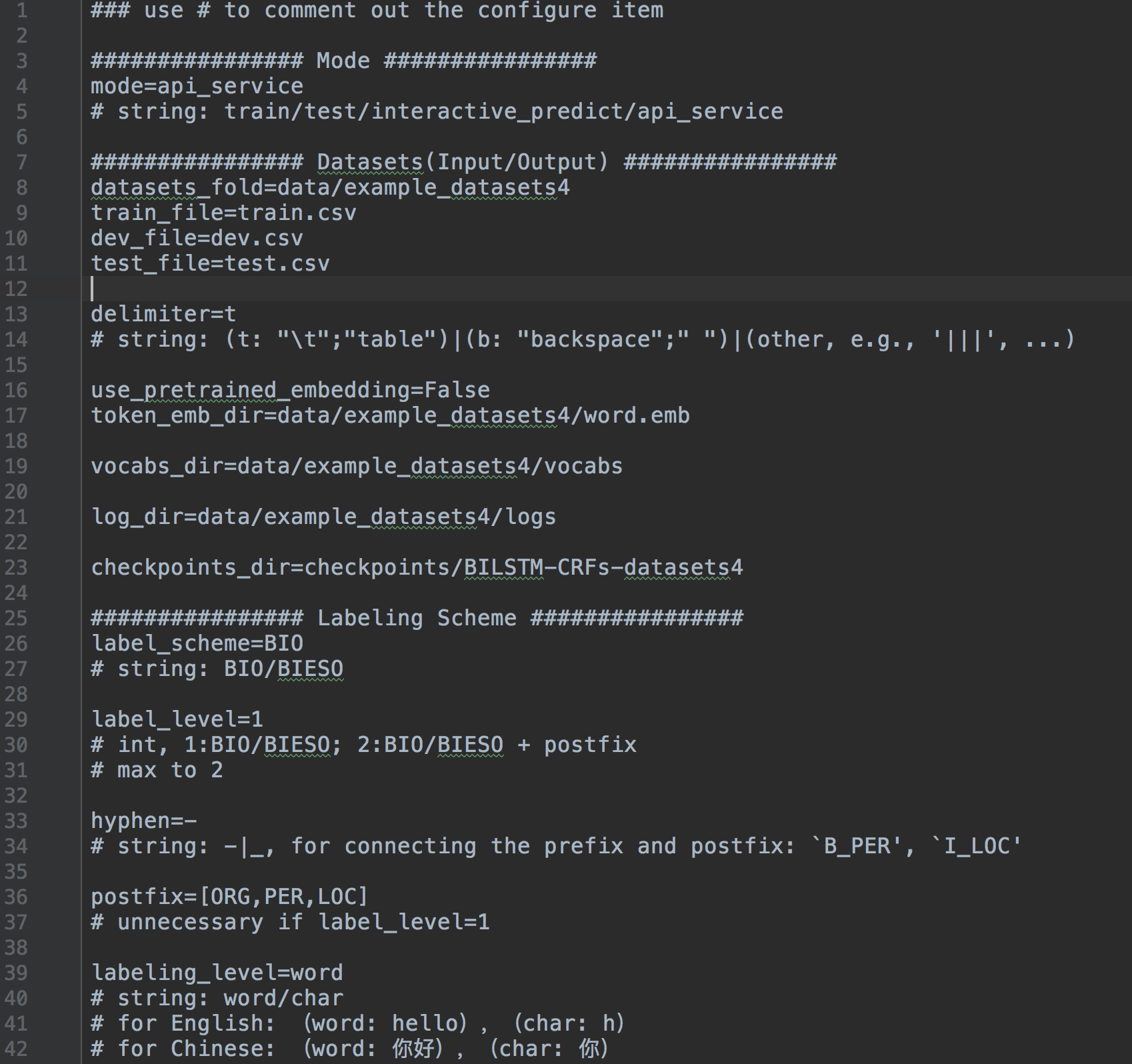
main.py 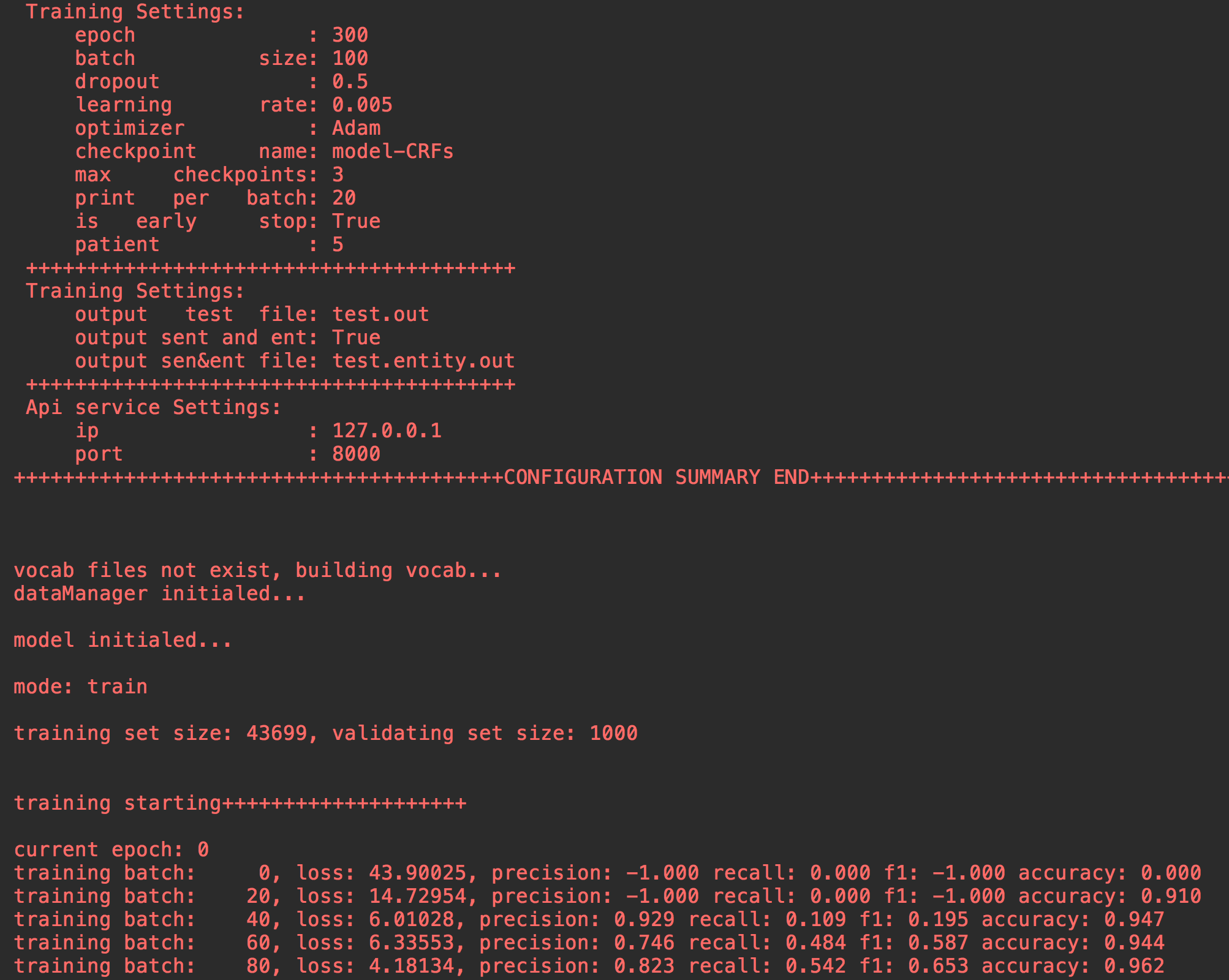
main.py main.py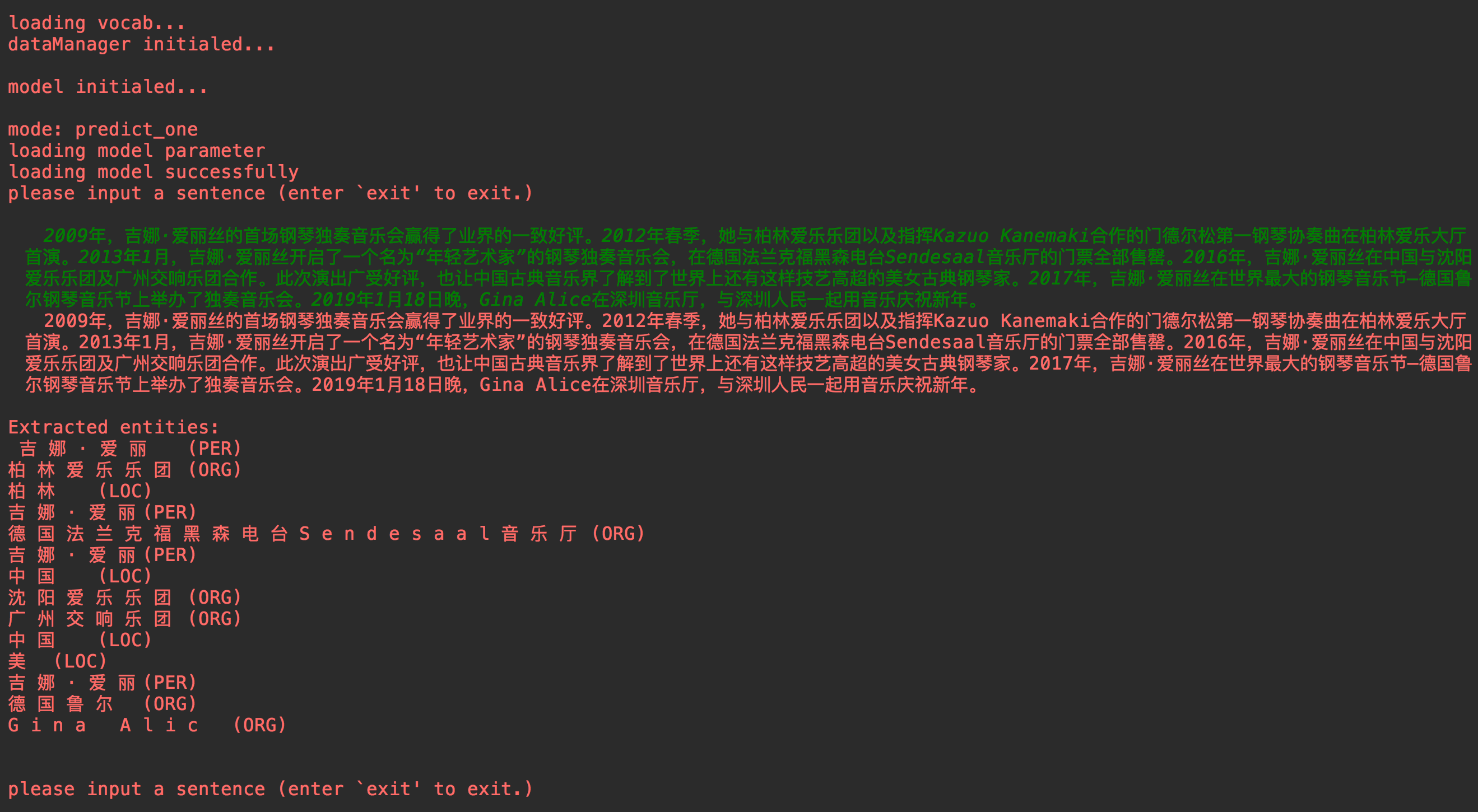
main.py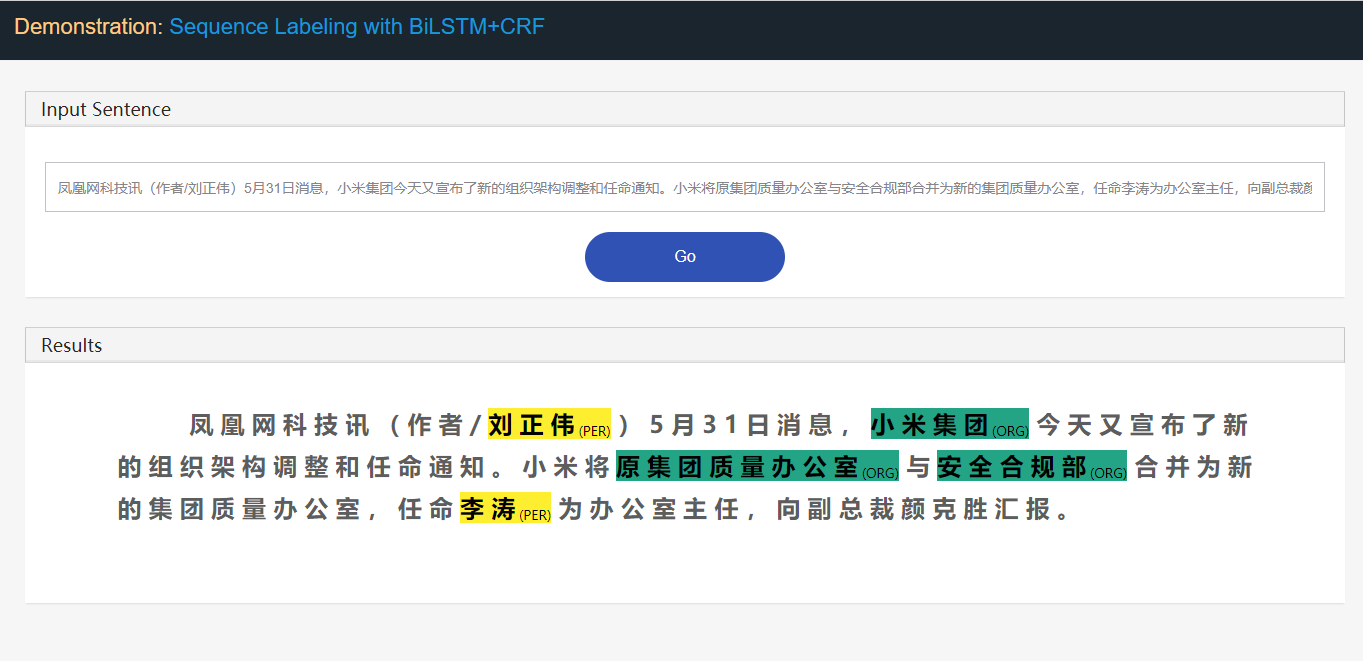
Los conjuntos de datos que incluyen TrainSet, TestSet, Devset son necesarios para el uso general. Sin embargo, ¿solo quieres entrenar al modelo el uso fuera de línea? Solo se necesita el conjunto de trenes. Después de la capacitación, puede hacer una inferencia con los archivos de punto de control de modelo guardado. Si quieres hacer una prueba, deberías
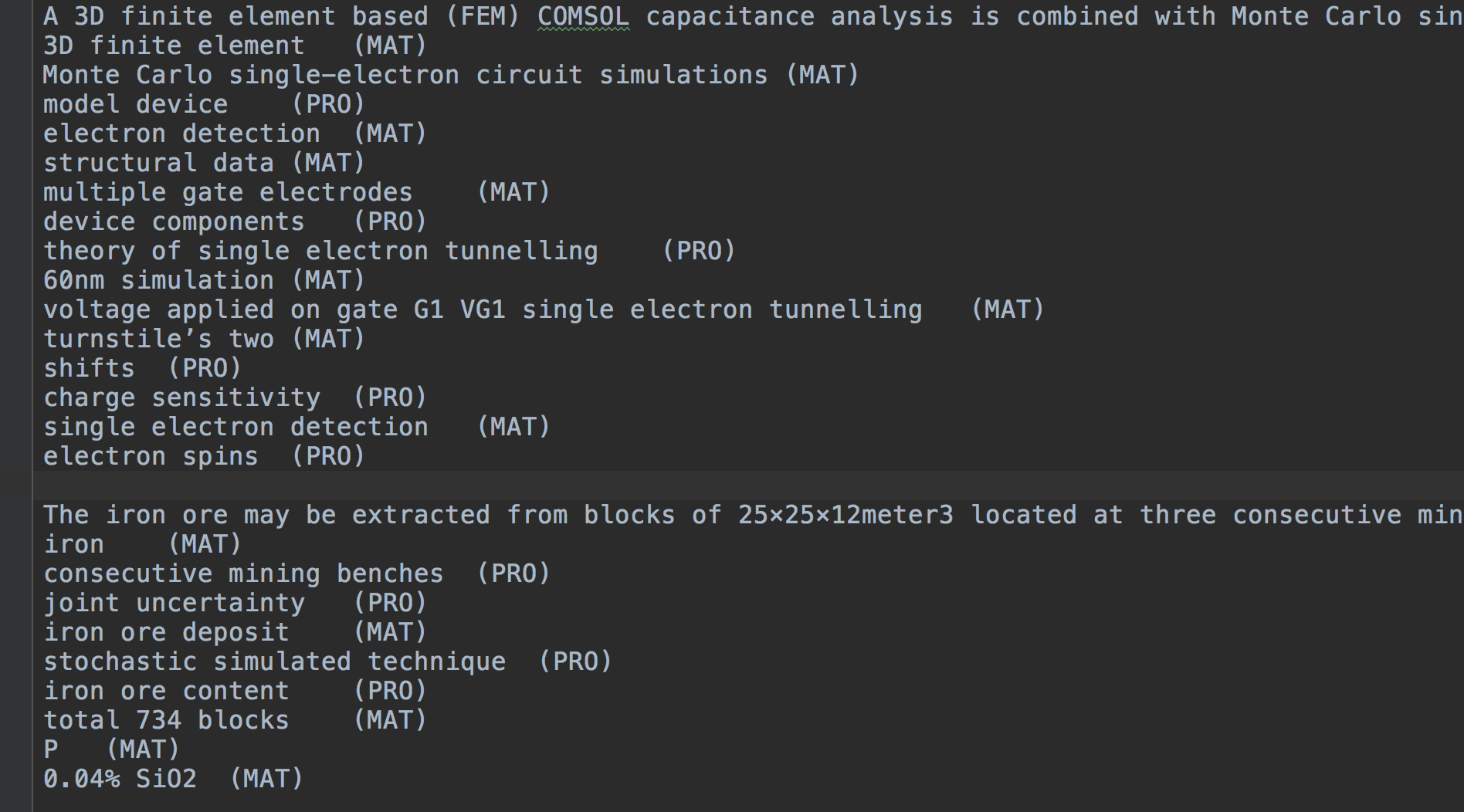
Para trainset , testset , devset , el formato común es el siguiente:
(Token) (Label)
for O
the O
lattice B_TAS
QCD I_TAS
computation I_TAS
of I_TAS
nucleon–nucleon I_TAS
low-energy I_TAS
interactions E_TAS
. O
It O
consists O
in O
simulating B_PRO
...
(Token) (Label)
马 B-LOC
来 I-LOC
西 I-LOC
亚 I-LOC
副 O
总 O
理 O
。 O
他 O
兼 O
任 O
财 B-ORG
政 I-ORG
部 I-ORG
长 O
...
Tenga en cuenta que:
testset solo puede existe con la fila Token . Durante las pruebas, el modelo generará las entidades predichas basadas en la test.csv . Los archivos de salida incluyen dos: test.out , test.entity.out (opcional).
test.out
con la misma formación que test.csv de entrada.csv.
test.entity.out
Sentence
entity1 (Type)
entity2 (Type)
entity3 (Type)
...
Si desea adaptar este proyecto a su propia tarea de etiquetado de secuencia específica, es posible que necesite los siguientes consejos.
Descargue las fuentes de repo.
Esquema de etiquetado (lo más importante)
B_PER', i_loc' Modelo: Modifique la arquitectura del modelo en la que deseaba, en BiLSTM_CRFs.py .
Conjunto de datos: adaptar a su conjunto de datos, en la formación correcta.
Capacitación
Para obtener más detalles de uso, se refiere al manual
Eres bienvenido para emitir algo mal.


