sequence labeling BiLSTM CRF
1.0.0
シーケンスラベルのタスク用のbilstm+CRFモデルのTensorflow実装。
Sequential labeling 、NLPのシーケンス予測タスクをモデル化する典型的な方法論の1つです。一般的なシーケンシャルラベリングタスクには、
例として指定されたエンティティ認識(NER)タスクを取得します。
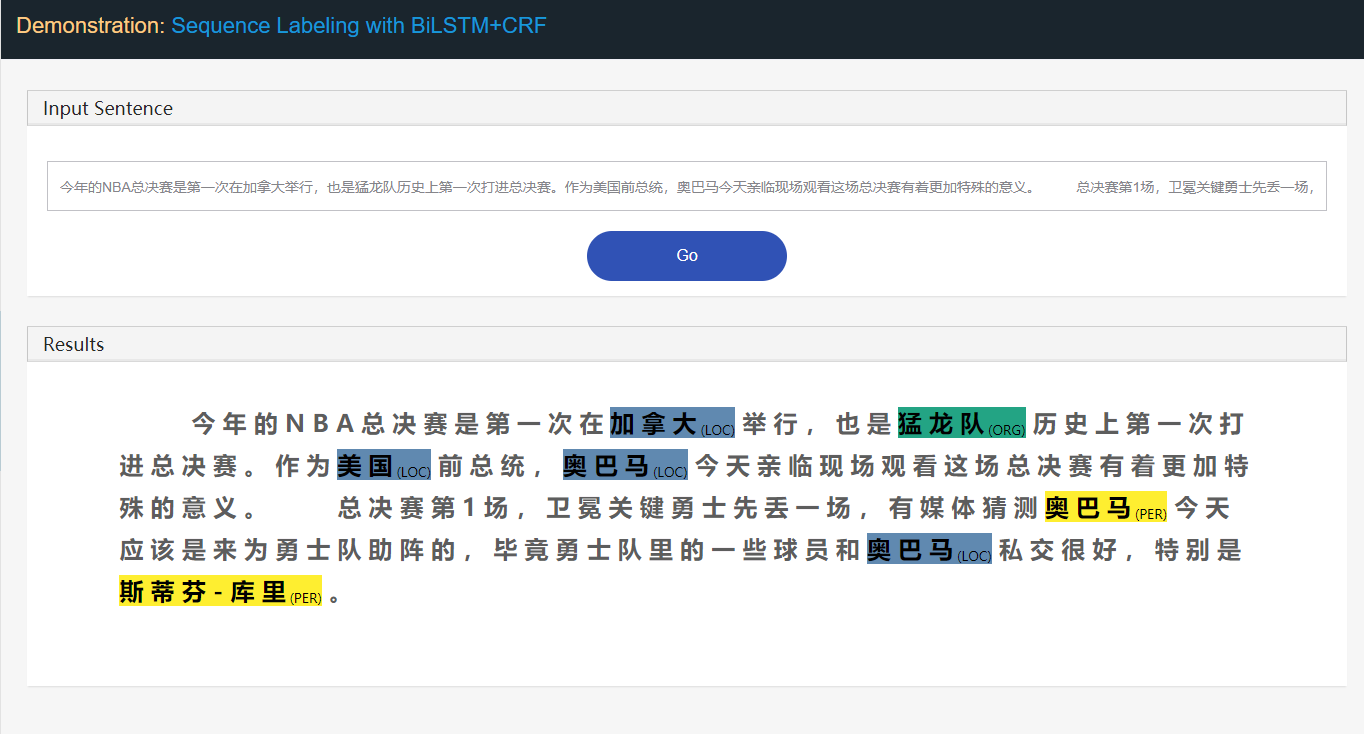
Stanford University located at California .
B-ORG I-ORG O O B-LOC Oここでは、 Stanford UniversityとCalifornia 2つのエンティティが抽出されます。具体的には、テキスト内の各tokenには、対応するlabelがタグ付けされています。 Eg、{ token : Stanford 、 label : B-Org }。シーケンス標識モデルは、トークンシーケンスが与えられた場合、ラベルシーケンスを予測することを目的としています。
Lample et al。、2016によって提案されたBiLSTM+CRFは、これまでのところ、連続標識タスクの最も古典的で安定した神経モデルです。 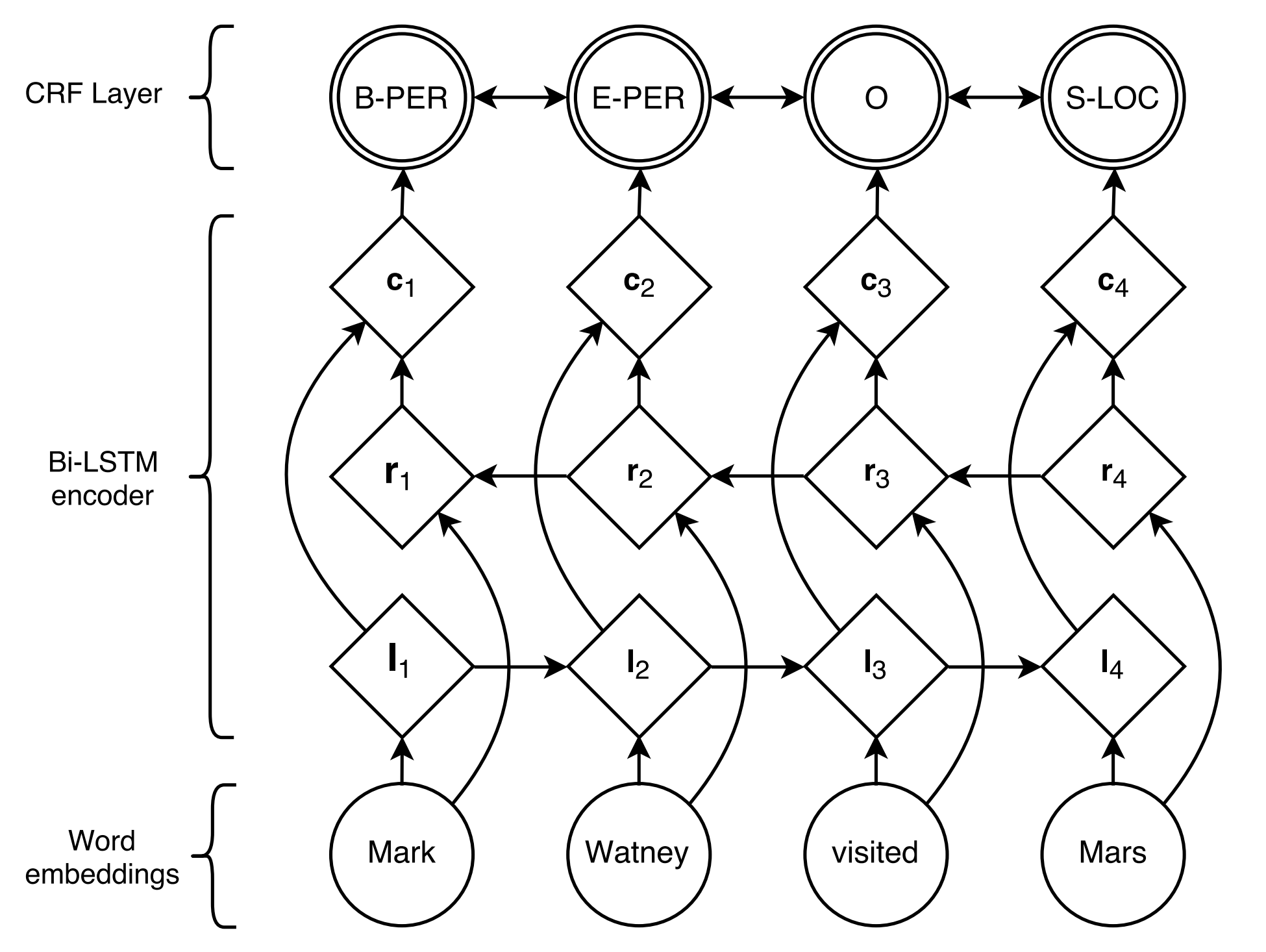
すべての設定の構成
train / test / interactive_predict / api_service ]BIO / BIESO ]PER | LOC | ORG ]すべてを記録します
簡単なデモンストレーションのためのWebアプリのデモ
オブジェクト指向:bilstm_crf、データセット、コンフィガー、utils
明確な構造でモジュール化され、DIYにとって簡単です。
ハンドブックの詳細をご覧ください。
直接使用するためにリポジトリをダウンロードしてください。
git clone https://github.com/scofield7419/sequence-labeling-BiLSTM-CRF.git
pip install -r requirements.txt
bilstm-crfパッケージをモジュールとしてインストールします。
pip install BiLSTM-CRF
使用法:
from BiLSTM-CRF.engines.BiLSTM_CRFs import BiLSTM_CRFs as BC
from BiLSTM-CRF.engines.DataManager import DataManager
from BiLSTM-CRF.engines.Configer import Configer
from BiLSTM-CRF.engines.utils import get_logger
...
config_file = r'/home/projects/system.config'
configs = Configer(config_file)
logger = get_logger(configs.log_dir)
configs.show_data_summary(logger) # optional
dataManager = DataManager(configs, logger)
model = BC(configs, logger, dataManager)
###### mode == 'train':
model.train()
###### mode == 'test':
model.test()
###### mode == 'single predicting':
sentence_tokens, entities, entities_type, entities_index = model.predict_single(sentence)
if configs.label_level == 1:
print("nExtracted entities:n %snn" % ("n".join(entities)))
elif configs.label_level == 2:
print("nExtracted entities:n %snn" % ("n".join([a + "t(%s)" % b for a, b in zip(entities, entities_type)])))
###### mode == 'api service webapp':
cmd_new = r'cd demo_webapp; python manage.py runserver %s:%s' % (configs.ip, configs.port)
res = os.system(cmd_new)
open `ip:port` in your browser.
├── main.py
├── system.config
├── HandBook.md
├── README.md
│
├── checkpoints
│ ├── BILSTM-CRFs-datasets1
│ │ ├── checkpoint
│ │ └── ...
│ └── ...
├── data
│ ├── example_datasets1
│ │ ├── logs
│ │ ├── vocabs
│ │ ├── test.csv
│ │ ├── train.csv
│ │ └── dev.csv
│ └── ...
├── demo_webapp
│ ├── demo_webapp
│ ├── interface
│ └── manage.py
├── engines
│ ├── BiLSTM_CRFs.py
│ ├── Configer.py
│ ├── DataManager.py
│ └── utils.py
└── tools
├── calcu_measure_testout.py
└── statis.py
折りたたみ
enginesでは、コア機能を提供します。data-subfoldフォールドでは、データセットが配置されます。checkpoints-subfold式では、モデルチェックポイントが保存されます。demo_webapp foldでは、Webでシステムを実証し、APIを提供できます。toolsで折りたたみ、いくつかのオフラインのユーティルを提供します。ファイル
main.pyは、システムのエントリPythonファイルです。system.configは、すべてのシステム設定の構成ファイルです。HandBook.mdいくつかの使用手順を提供します。BiLSTM_CRFs.pyがメインモデルです。Configer.py system.configを解析します。DataManager.py 、データセットとスケジューリングを管理します。utils.pyフライツールを提供します。 以下の手順:
system.config構成ファイルを作成します。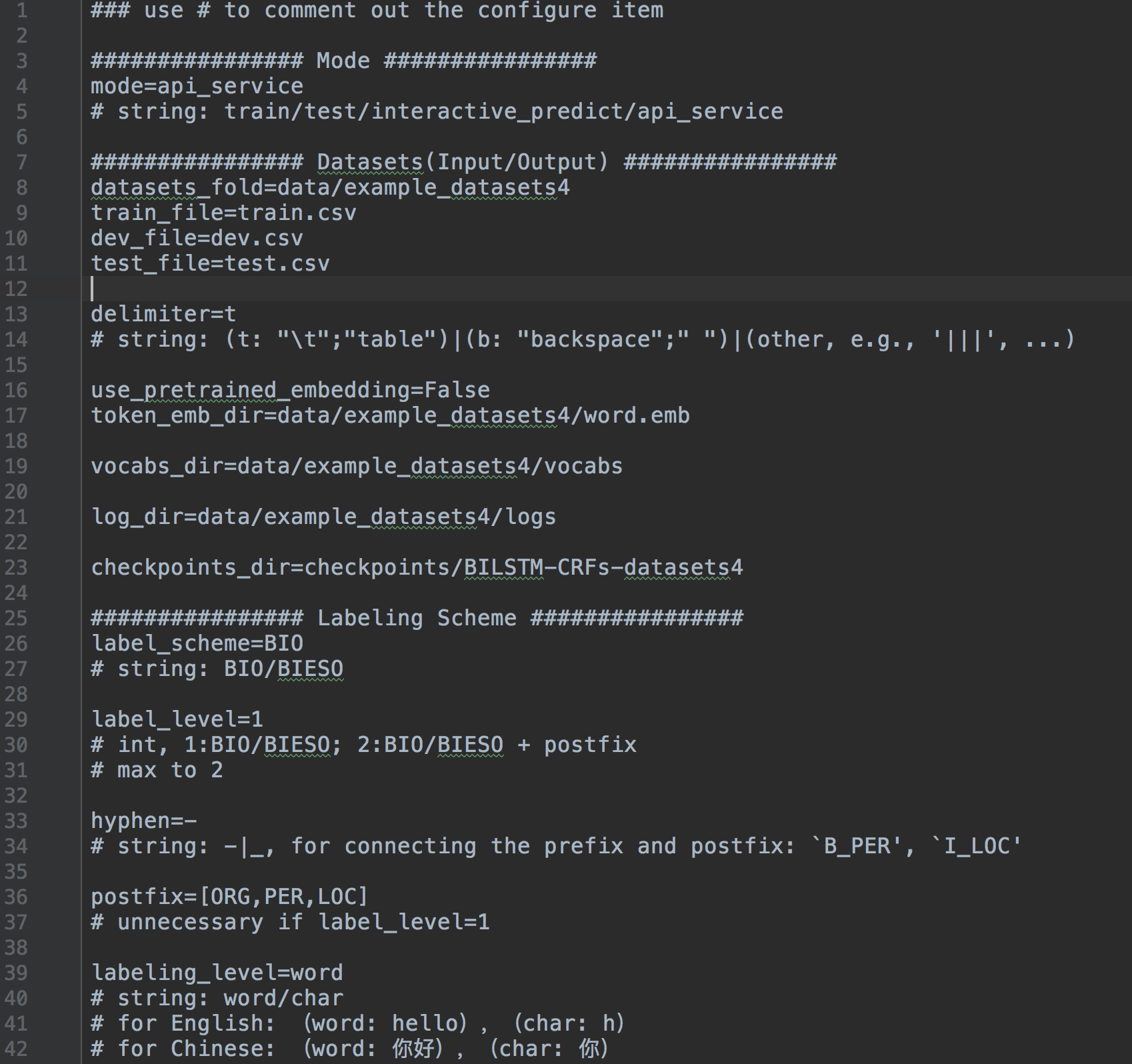
main.pyを実行します。 
main.pyを実行します。 main.pyを実行します。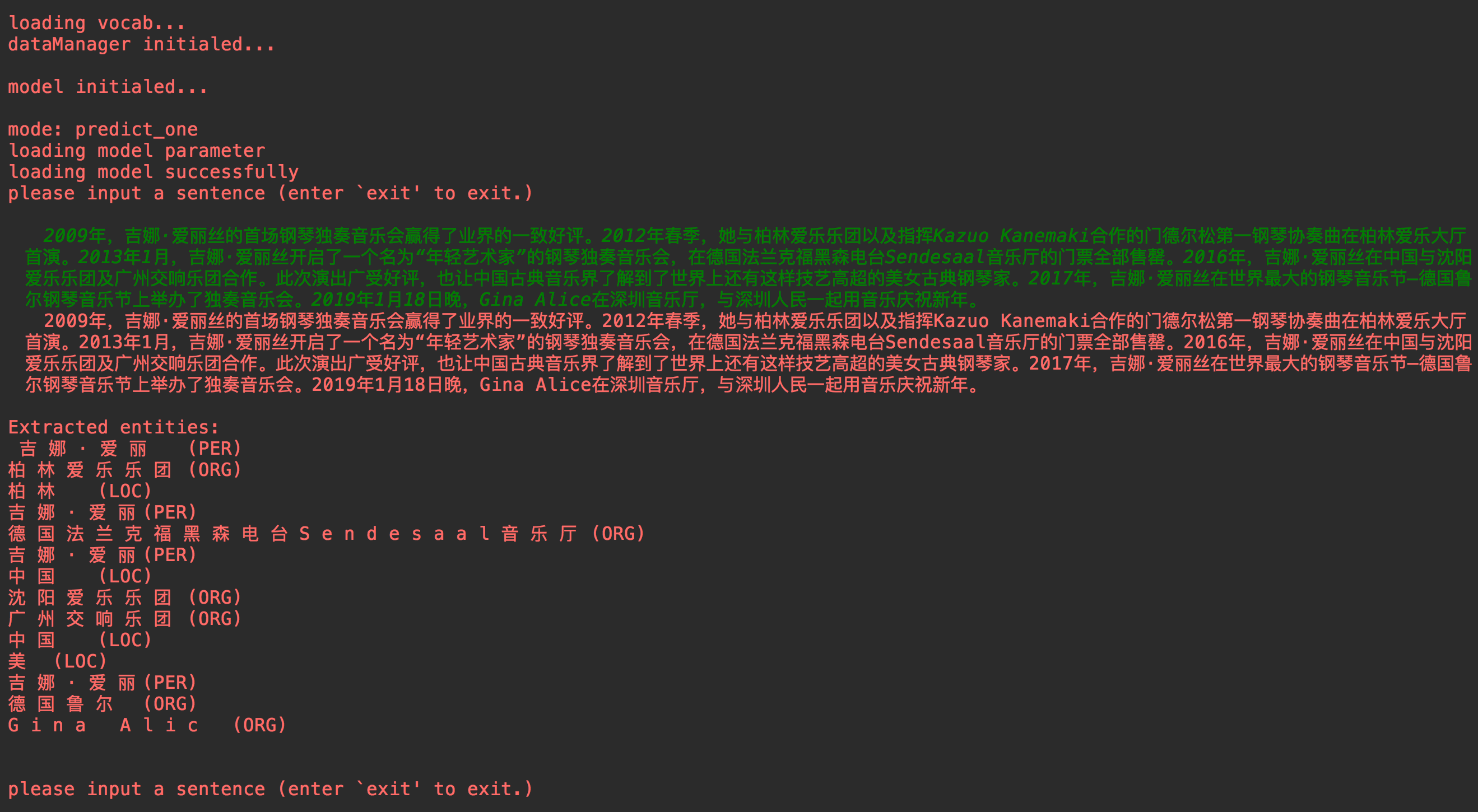
main.pyを実行します。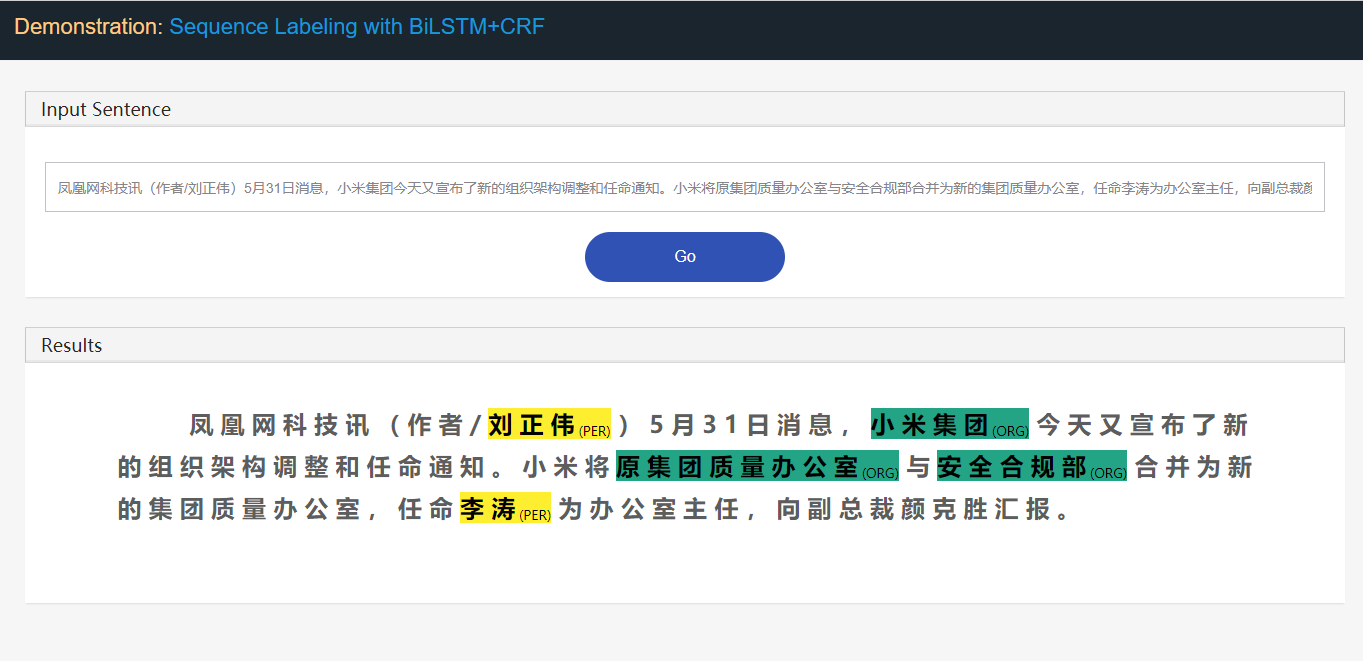
全体的な使用には、Trainset、Testset、Devsetを含むデータセットが必要です。ただし、モデルをオフラインで使用するだけで、トレインセットのみが必要です。トレーニング後、保存されたモデルチェックポイントファイルに推論を行うことができます。あなたがテストしたいなら、あなたはすべきです
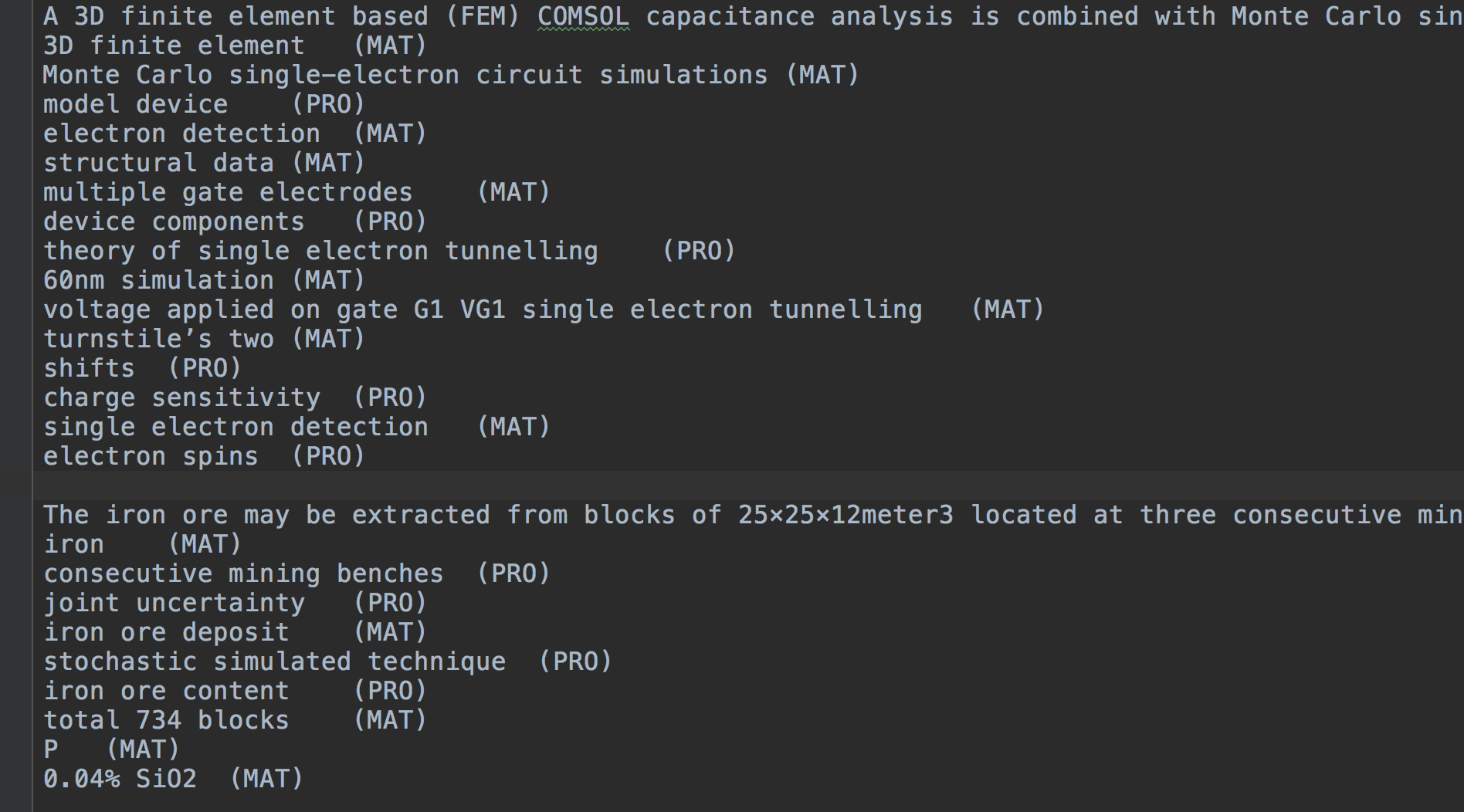
trainset 、 testset 、 devset 、共通形式は次のとおりです。
(Token) (Label)
for O
the O
lattice B_TAS
QCD I_TAS
computation I_TAS
of I_TAS
nucleon–nucleon I_TAS
low-energy I_TAS
interactions E_TAS
. O
It O
consists O
in O
simulating B_PRO
...
(Token) (Label)
马 B-LOC
来 I-LOC
西 I-LOC
亚 I-LOC
副 O
总 O
理 O
。 O
他 O
兼 O
任 O
财 B-ORG
政 I-ORG
部 I-ORG
长 O
...
ご了承ください:
testset 、 Token行でのみ存在します。テスト中、モデルはtest.csvに基づいて予測されるエンティティを出力します。出力ファイルには、 test.out 、 test.entity.out (オプション)の2つが含まれます。
test.out
入力test.csvと同じ形成。
test.entity.out
Sentence
entity1 (Type)
entity2 (Type)
entity3 (Type)
...
このプロジェクトを独自の特定のシーケンスラベル付けタスクに適応させたい場合は、次のヒントが必要になる場合があります。
レポソースをダウンロードします。
ラベル付けスキーム(最も重要)
B_PER', i_loc'モデル: BiLSTM_CRFs.pyで、モデルアーキテクチャを必要なものに変更します。
データセット:正しいフォーメーションでデータセットに適応します。
トレーニング
より多くのユーザーの詳細については、ハンドブックを参照してください
何か間違ったことを発行することを歓迎しています。


