sequence labeling BiLSTM CRF
1.0.0
Implementasi TensorFlow model BILSTM+CRF, untuk tugas pelabelan urutan.
Sequential labeling adalah salah satu pemodelan metodologi khas Tugas prediksi urutan di NLP. Tugas pelabelan berurutan umum termasuk, misalnya,
Mengambil tugas Entity Recognition (NER) sebagai contoh:
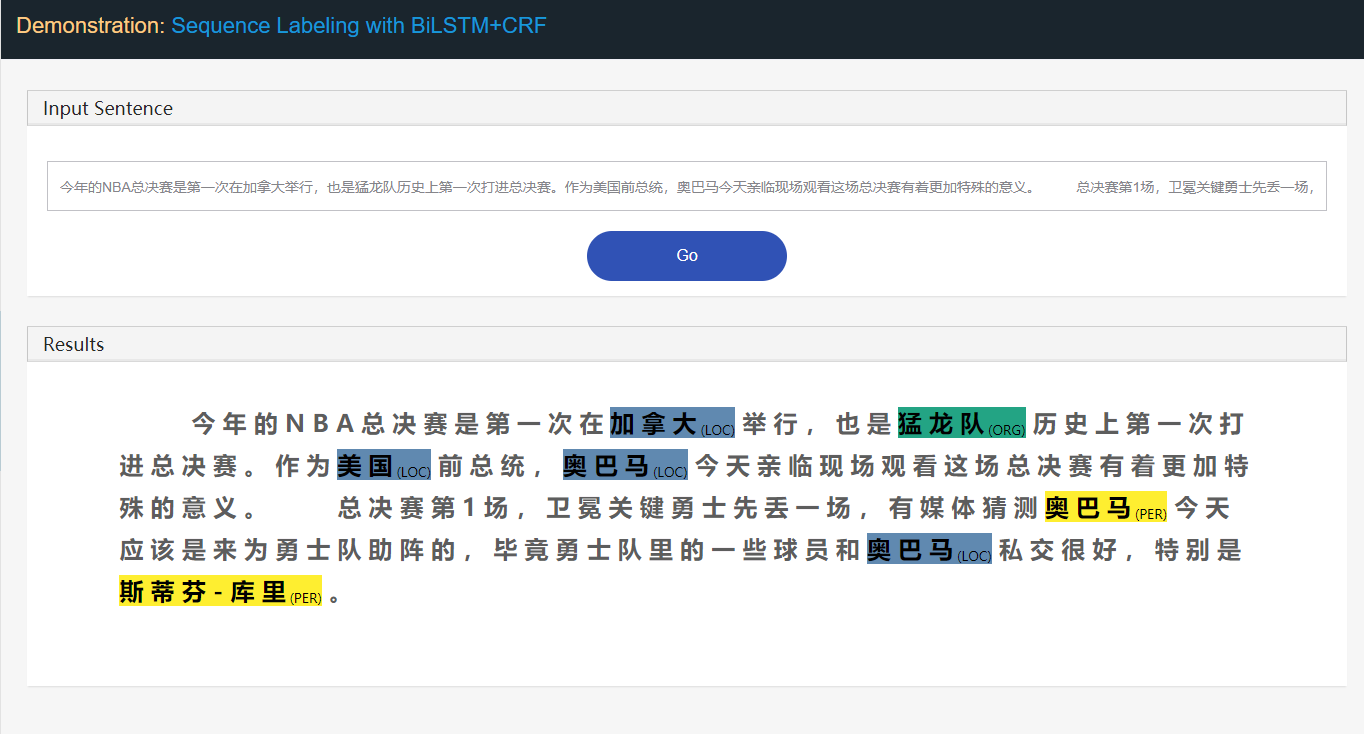
Stanford University located at California .
B-ORG I-ORG O O B-LOC O Di sini, dua entitas, Stanford University dan California harus diekstraksi. Dan secara khusus, setiap token dalam teks ditandai dengan label yang sesuai. Misalnya, { token : stanford , label : b-org }. Model pelabelan urutan bertujuan untuk memprediksi urutan label, diberikan urutan token.
BiLSTM+CRF yang diusulkan oleh Lample et al., 2016, sejauh ini merupakan model saraf yang paling klasik dan stabil untuk tugas pelabelan berurutan. 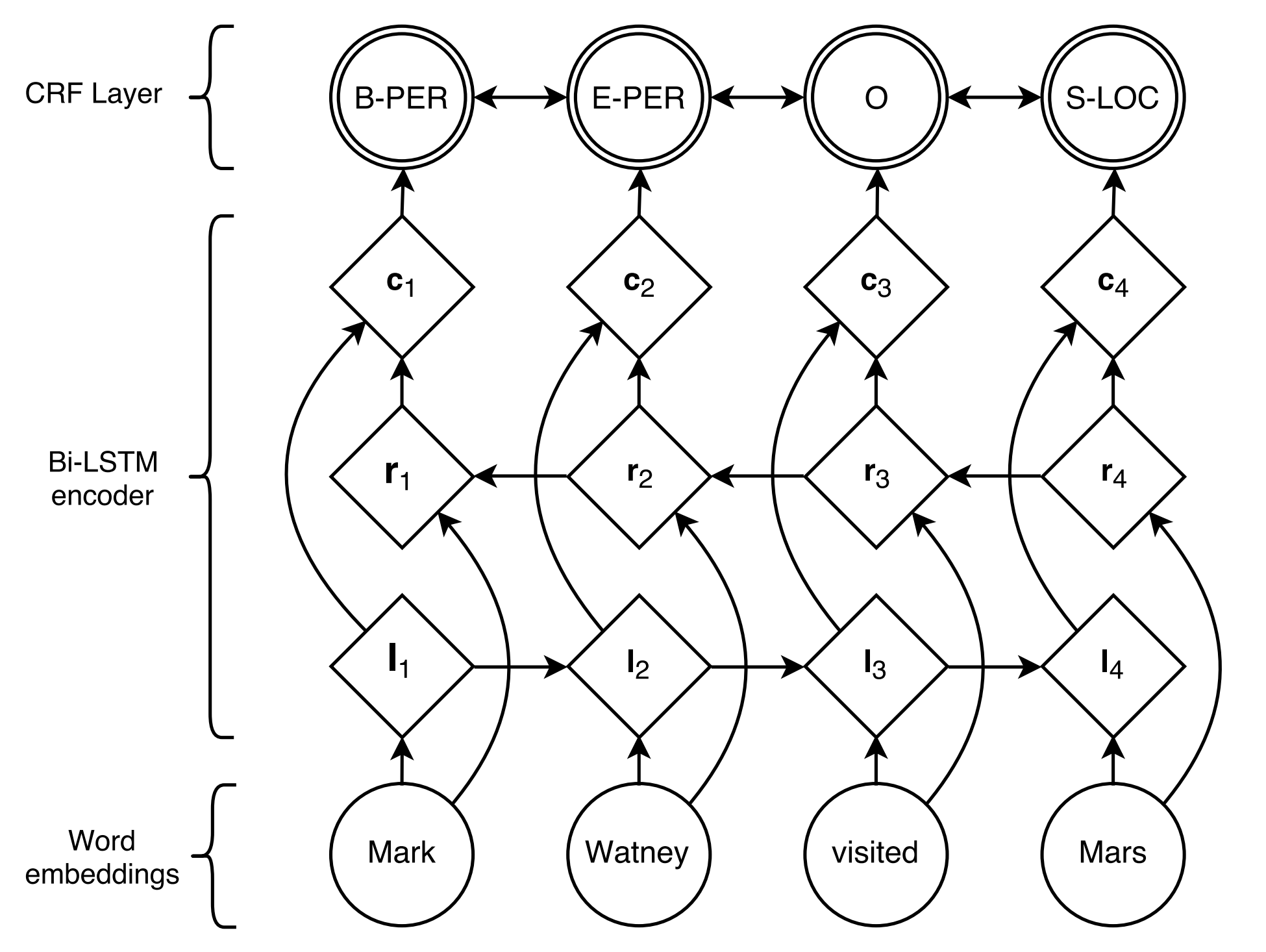
Mengkonfigurasi semua pengaturan
train / test / interactive_predict / api_service ]BIO / BIESO ]PER | LOC | ORG ]mencatat semuanya
demo aplikasi web untuk demonstrasi mudah
Berorientasi objek: bilstm_crf, dataset, configer, utils
Modularisasi dengan struktur yang jelas, mudah untuk DIY.
Lihat lebih banyak di Buku Pegangan.
Unduh repo untuk digunakan langsung.
git clone https://github.com/scofield7419/sequence-labeling-BiLSTM-CRF.git
pip install -r requirements.txt
Instal paket BILSTM-CRF sebagai modul.
pip install BiLSTM-CRF
penggunaan:
from BiLSTM-CRF.engines.BiLSTM_CRFs import BiLSTM_CRFs as BC
from BiLSTM-CRF.engines.DataManager import DataManager
from BiLSTM-CRF.engines.Configer import Configer
from BiLSTM-CRF.engines.utils import get_logger
...
config_file = r'/home/projects/system.config'
configs = Configer(config_file)
logger = get_logger(configs.log_dir)
configs.show_data_summary(logger) # optional
dataManager = DataManager(configs, logger)
model = BC(configs, logger, dataManager)
###### mode == 'train':
model.train()
###### mode == 'test':
model.test()
###### mode == 'single predicting':
sentence_tokens, entities, entities_type, entities_index = model.predict_single(sentence)
if configs.label_level == 1:
print("nExtracted entities:n %snn" % ("n".join(entities)))
elif configs.label_level == 2:
print("nExtracted entities:n %snn" % ("n".join([a + "t(%s)" % b for a, b in zip(entities, entities_type)])))
###### mode == 'api service webapp':
cmd_new = r'cd demo_webapp; python manage.py runserver %s:%s' % (configs.ip, configs.port)
res = os.system(cmd_new)
open `ip:port` in your browser.
├── main.py
├── system.config
├── HandBook.md
├── README.md
│
├── checkpoints
│ ├── BILSTM-CRFs-datasets1
│ │ ├── checkpoint
│ │ └── ...
│ └── ...
├── data
│ ├── example_datasets1
│ │ ├── logs
│ │ ├── vocabs
│ │ ├── test.csv
│ │ ├── train.csv
│ │ └── dev.csv
│ └── ...
├── demo_webapp
│ ├── demo_webapp
│ ├── interface
│ └── manage.py
├── engines
│ ├── BiLSTM_CRFs.py
│ ├── Configer.py
│ ├── DataManager.py
│ └── utils.py
└── tools
├── calcu_measure_testout.py
└── statis.py
Lipatan
engines , menyediakan PY yang berfungsi inti.data-subfold , dataset ditempatkan.checkpoints-subfold , pos pemeriksaan model disimpan.demo_webapp , kita dapat mendemonstrasikan sistem di web, dan menyediakan API.tools , berikan beberapa util offline.File
main.py adalah file Python entri untuk sistem.system.config adalah file konfigurasi untuk semua pengaturan sistem.HandBook.md memberikan beberapa instruksi penggunaan.BiLSTM_CRFs.py adalah model utama.Configer.py parses system.config .DataManager.py mengelola dataset dan penjadwalan.utils.py menyediakan alat terbang. Di bawah langkah berikut:
system.config .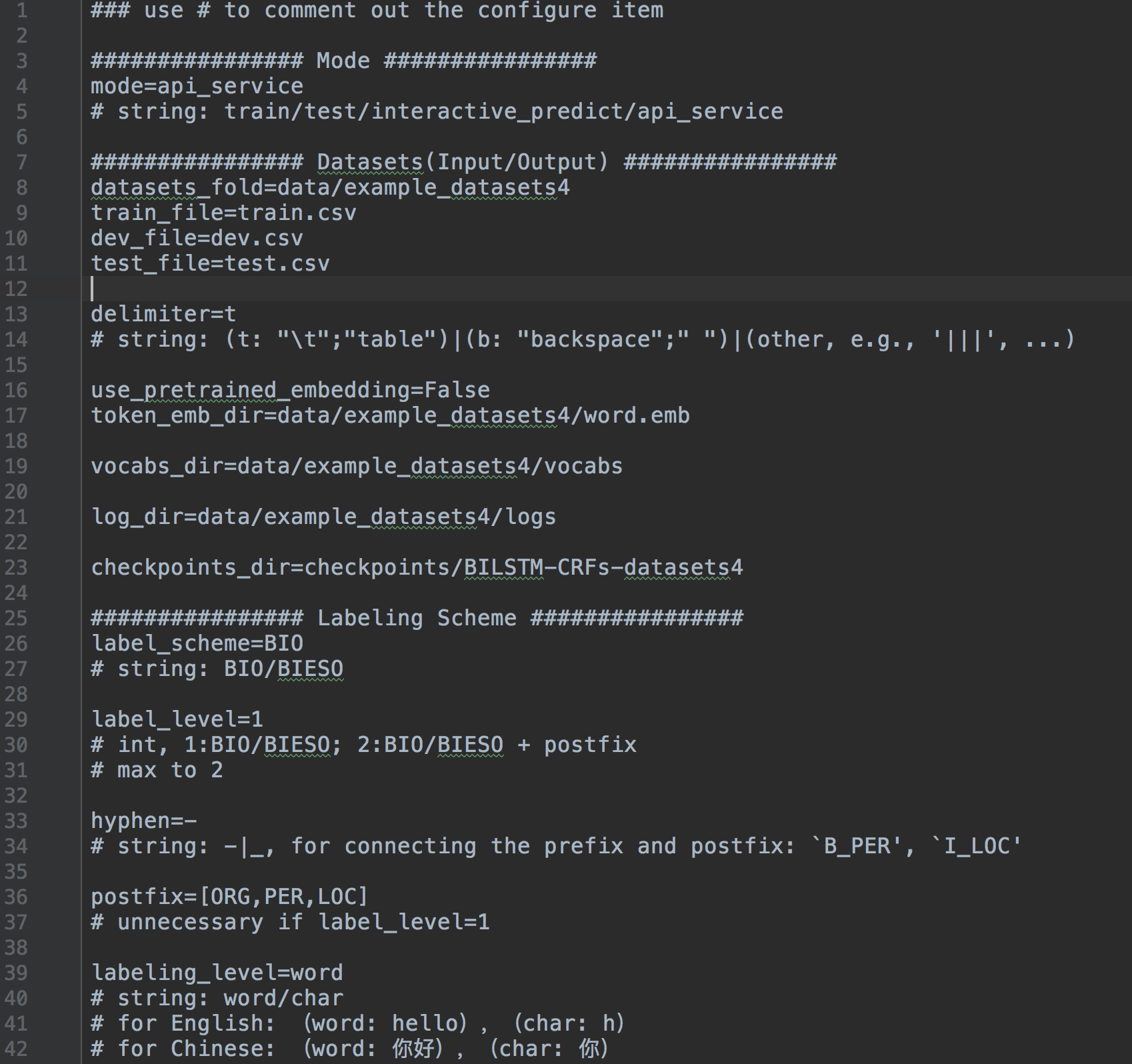
main.py 
main.py main.py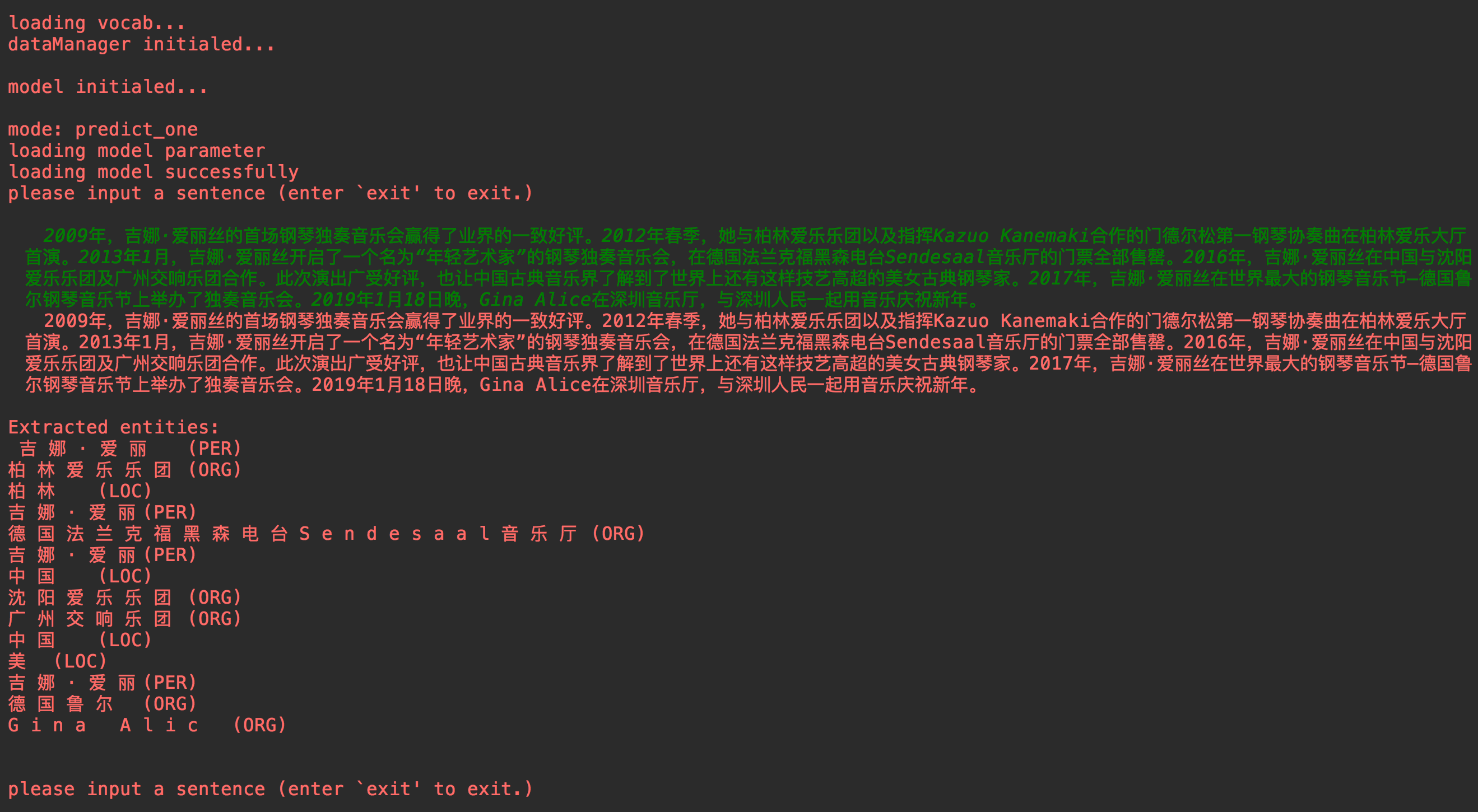
main.py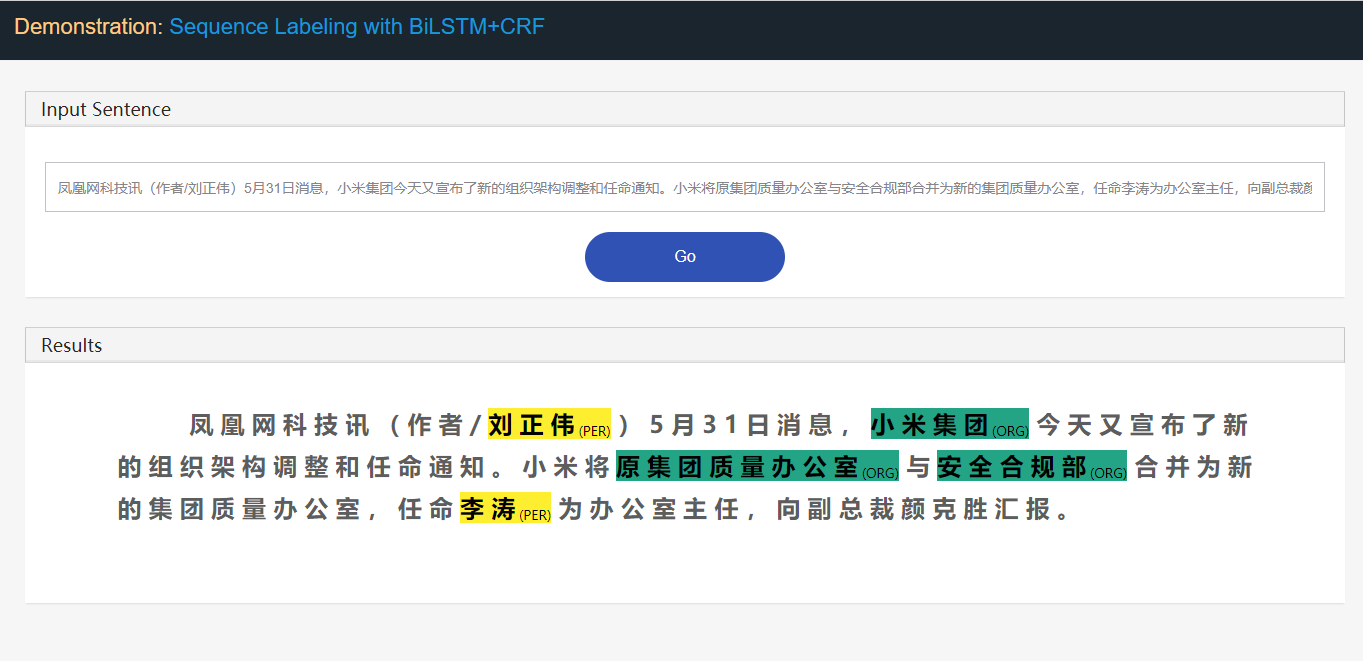
Kumpulan data termasuk Trainset, Testset, Devset diperlukan untuk penggunaan keseluruhan. Namun, apakah Anda hanya ingin melatih model penggunaannya secara offline, hanya trainset yang diperlukan. Setelah pelatihan, Anda dapat membuat inferensi dengan file pos pemeriksaan model yang disimpan. Jika Anda ingin melakukan tes, Anda harus melakukannya
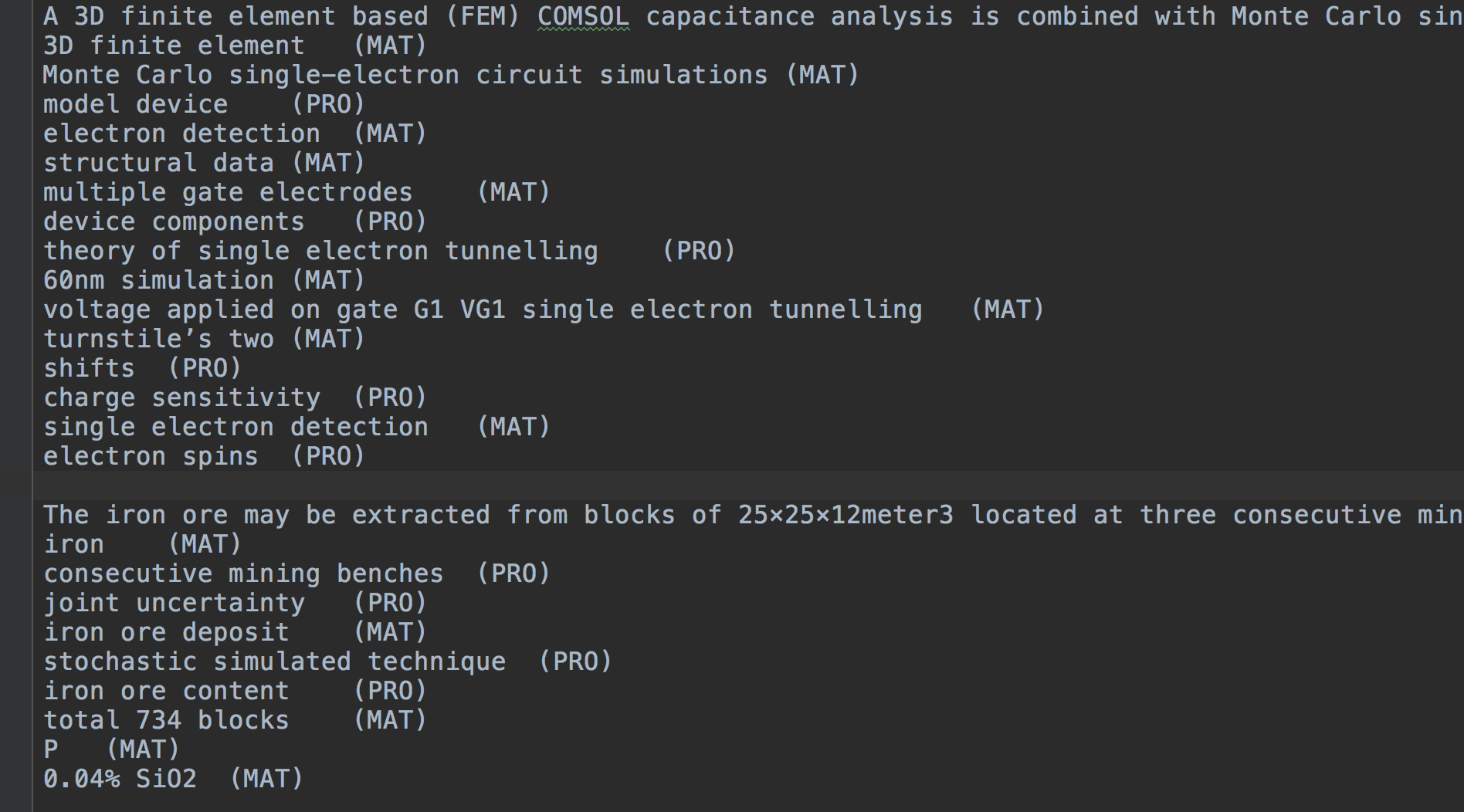
Untuk trainset , testset , devset , format umum adalah sebagai berikut:
(Token) (Label)
for O
the O
lattice B_TAS
QCD I_TAS
computation I_TAS
of I_TAS
nucleon–nucleon I_TAS
low-energy I_TAS
interactions E_TAS
. O
It O
consists O
in O
simulating B_PRO
...
(Token) (Label)
马 B-LOC
来 I-LOC
西 I-LOC
亚 I-LOC
副 O
总 O
理 O
。 O
他 O
兼 O
任 O
财 B-ORG
政 I-ORG
部 I-ORG
长 O
...
Perhatikan bahwa:
testset hanya dapat ada dengan baris Token . Selama pengujian, model akan menghasilkan entitas yang diprediksi berdasarkan test.csv . File output termasuk dua: test.out , test.entity.out (opsional).
test.out
dengan formasi yang sama seperti test.csv input.csv.
test.entity.out
Sentence
entity1 (Type)
entity2 (Type)
entity3 (Type)
...
Jika Anda ingin mengadaptasi proyek ini dengan tugas pelabelan urutan spesifik Anda sendiri, Anda mungkin memerlukan tips berikut.
Unduh sumber repo.
Skema Pelabelan (Paling Penting)
B_PER', i_loc' Model: Ubah arsitektur model menjadi yang Anda inginkan, di BiLSTM_CRFs.py .
Dataset: Beradaptasi dengan dataset Anda, dalam formasi yang benar.
Pelatihan
Untuk detail penggunaan lebih lanjut, mohon mengacu pada buku pegangan
Anda disambut untuk mengeluarkan sesuatu yang salah.


