NLPGNN
1.0.0
自然语言处理的领域目前正在发生巨大变化,近年来已经提出了许多出色的模型,包括Bert,GPT,等。
同时,将图形神经网络作为一种精致的设计不断地用于自然语言处理领域,例如TextGCN和Tensor-TextGCN。
该工具箱专用于自然语言处理,并希望以最简单的方式实现模型。
关键字:NLP; Gnn
型号:
示例(有关更多详细信息,请参见测试):
上述所有实验均在GTX 1080 GPU上测试,并使用存储器8000MIB进行测试。
2020/5/ - :将项目名称转换为FERNLP的NLPGNN。
2020/5/17:尝试根据BERT注意矩阵将句子转换为图形,但失败了。本节提供了可视化BERT注意矩阵的解决方案。有关更多详细信息,您可以检查字典“ bert-gcn”。
2020/5/11:添加文本和文本分类的文本和文本。
2020/5/5:添加杜松子酒,图形分类的图形。
2020/4/25:基于消息传递方法,添加gan,杜松子酒模型。
2020/4/23:基于消息传递方法添加GCN模型。
2020/4/16:目前专注于NLP中的GNN模型,并试图将一些GNN模型集成到FERNLP中。
2020/4/2:添加GPT2模型,可以使用OpenAI(基础,中,大)发布的参数。更详细的参考字典“ tg/en/interactive.py”
2020/3/26:添加Bilstm+分类的注意示例
2020/3/23:添加RADAM优化器。
2020/3/19:添加测试示例“ albert_ner_train.py”“ albert_ner_test.py”
2020/3/16:添加基于BPE方法的训练子单词嵌入的模型。训练有素的嵌入在TextCNN模型中用于改进其改进。有关更多详细信息,请参见“ tran_bpe_embeding.py”。
2020/3/8:添加测试示例“ run_tucker.py”,用于WN18上的火车塔克。
2020/3/3:添加测试示例“ tran_text_cnn.py”,用于火车文本模型。
2020/3/2:基于BERT的文本分类添加测试示例“ Train_bert_classification.py”。
git clone https://github.com/kyzhouhzau/NLPGNN.git
python setup.py install
python bert_ner_train.py
将火车,有效和测试文件放入“输入”字典中。
数据格式:“测试 ner input train”中的参考数据
例如“ rank” rankl对对破骨细细作用用用用。用用用用用。用用。。用用用。。用用
对于火车中的每一行都包含两个部分,第一部分是“ rankl rank”对破胞的作用用。”是一个句子。第二部分是“ oooo b-解剖学i-解剖学i-解剖e-Anatomy oooo”是句子中每个单词的标签。他们俩都使用“ t”来连接。
from nlpgnn . models import bert
bert = bert . BERT () python bert_ner_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
=================================================================
Total params: 101,712,430
Trainable params: 101,712,430
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import bert
from nlpgnn . metrics . crf import CrfLogLikelihood
bert = bert . BERT ()
crf = CrfLogLikelihood () python bert_ner_crf_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
_________________________________________________________________
crf (CrfLogLikelihood) multiple 2116
=================================================================
Total params: 101,714,546
Trainable params: 101,714,546
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import albert
bert = albert . ALBERT () python albert_ner_train.py
large
Model: "albert_ner"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
albert (ALBERT) multiple 11092992
_________________________________________________________________
dense (Dense) multiple 6921
=================================================================
Total params: 11,099,913
Trainable params: 11,099,913
Non-trainable params: 0
_________________________________________________________________
使用默认参数,我们在“中文糖尿病标注数据集”和“ Conll-2003”有效数据上获得以下结果。
| 模型 | 宏F1 | 宏-P | 宏R | LR | 时代 | 麦克斯伦 | batch_size | 数据 |
|---|---|---|---|---|---|---|---|---|
| Bert+基础 | 0.7005 | 0.7244 | 0.7031 | 2E-5 | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| BERT+BASE+CRF | 0.7009 | 0.7237 | 0.7041 | 2E-5(BERT),2E-3(CRF) | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| Bert+基础 | 0.9128 | 0.9208 | 0.9227 | 2E-5 | 5 | 128 | 8 | Conll-2003 |
| 阿尔伯特+基地 | 0.8512 | 0.8678 | 0.8589 | 1E-4 | 8 | 128 | 16 | Conll-2003 |
| 阿尔伯特+大 | 0.8670 | 0.8778 | 0.8731 | 2E-5 | 10 | 128 | 4 | Conll-2003 |
将火车,有效和测试文件放入“输入”字典中。
数据格式:“ tests cls bert(或Albert) Input”中的参考数据。
例如,“作作上曾经强拳王之,小王之之之王王王克里琴琴科科科谈自自己己是否是是否否会会2”
对于火车(测试,有效)中的每一行,第一部分“作为上曾经最拳拳王之王,小小克里琴琴琴谈谈谈己己是是否否否出会复复会会会复复”是句子,第二部分是“ 2”。
from nlpgnn . models import bert
bert = bert . BERT () python train_bert_classification.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 102267648
_________________________________________________________________
dense (Dense) multiple 11535
=================================================================
Total params: 102,279,183
Trainable params: 102,279,183
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import TextCNN
model = TextCNN . TextCNN () python train_text_cnn.py
Use "WordPiece embedding" to Initialize word embedding. Train your embeddings.
python train_bpe_embedding.py
有关更多详细信息参考文字
使用默认参数,我们在“新闻标题短文本分类”和SST-2有效数据上获得以下结果。
| 模型 | ACC | LR | 时代 | 麦克斯伦 | batch_size | 数据 |
|---|---|---|---|---|---|---|
| Bert+基础 | 0.8899 | 1E-5 | 5 | 50 | 32 | 新闻标题短文本分类 |
| Bert+基础 | 0.9266 | 2E-5 | 3 | 128 | 8 | SST-2 |
| 阿尔伯特+基地 | 0.9186 | 1E-5 | 3 | 128 | 16 | SST-2 |
| 阿尔伯特+大 | 0.9461 | 1E-6 | 3 | 128 | 4 | SST-2 |
| Bilstm+注意 | 0.8269 | 0.01 | 3 | 128 | 64 | SST-2 |
| textcnn | 0.8233 | 0.01 | 3 | 128 | 64 | SST-2 |
from nlpgnn . models import gpt2
bert = gpt2 . GPT2 () python interactive.py
Model: "gen_gp_t2" base
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gpt2 (GPT2) multiple 124439808
=================================================================
Total params: 124,439,808
Trainable params: 124,439,808
Non-trainable params: 0
_________________________________________________________________
例子:
Input >>> Stocks continue to fall this week
Output >>> as stocks fall for the second consecutive week as investors flee for safe havens.
"The market is off the charts," said John Schmieding, senior vice president, market strategy at RBC Capital Markets.
"We don't know what the Fed's intent is on, what direction it's going in. We don't know where they plan to go.
We don't know what direction they're going to move into."
张板可以帮助您可视化损失并评估指标:
USEAGE:
tensorboard --port 6006 --logdir="./tensorboard"
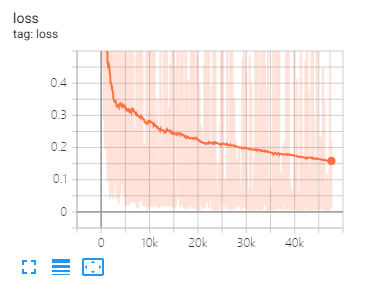
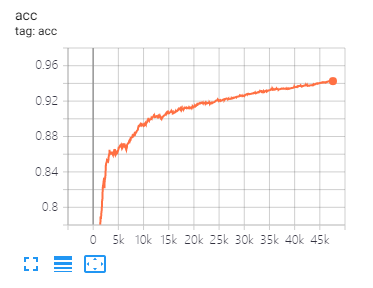
与本文相同的数据拆分和参数设置
| 模型 | 科拉 | PubMed | Citeseer |
|---|---|---|---|
| GCN | 81.80 | 79.50 | 71.20 |
| 甘 | 83.00 | 79.00 | 72.30 |
| 盖 | 82.40 | 79.60 | 71.70 |
| 模型 | Mutag | 蛋白质 | NCI1 |
|---|---|---|---|
| 杜松子酒 | 87.62±8.76 # | 73.05±1.85 # | 73.13±5.57 # |
| 图形 | 86.06±8.26 | 75.11±2.87 | 76.91±3.45 |
注意:#符号表示当前结果小于纸张结果。在本文中,作者使用此方法评估模型。这种方法很昂贵。所以我在这里没有这样做。
| 模型 | R8 | R52 |
|---|---|---|
| 文字 | 96.68±0.42 | 92.80±0.32 |
| TextGCN2019 | 97.108±0.243 | 92.512±0.249 |
1,对于英语任务,您需要设置参数“ cased”(在fennlp.datas.checkpoint.checkpoint.loadcheckpoint中),以与您的预处理输入数据一致,以确保令牌可以正确区分案例。
2,当您使用Bert或Albert时,需要以下参数:
param.maxlen
param.label_size
param.batch_size
如果您不知道Label_size的计数,则脚本将在第一次运行火车代码时告诉您。
3,学习率和batch_size将确定模型收敛,请参见链接以获取更多详细信息。
4,如果您不熟悉Bert和Albert中的优化器,那没关系。您需要记住的最重要的事情是参数“ Learning_rate”和“ Decay_steps”(在Fennlp.optimizers.optim.adamwarmup中)很重要。您可以将“学习率”设置为相对较小的值,让“ decay_steps”等于样本*epoch/batch_size或更高。
5,如果发现代码运行较慢,则可以尝试使用 @ tf.Function并设置适当的模型写作和评估频率。
6,其他任何其他问题,您都可以通过“ [email protected]”来限制我或提出有关问题的问题。
[1] BERT:深层双向变压器的预训练以理解语言
[2]阿尔伯特:一个精简的语言表示学习的精简版
[3]语言模型是无监督的多任务学习者
[4]量子化学的神经信息传递
[5]与图形卷积网络的半监督分类
[6]图形注意网络
[7]图形神经网络有多强大?
[8]图:归纳表示在大图上学习
[9]扩散改善图形学习
[10]基准图形神经网络
[11]用于文本分类的文本级别图形神经网络
[12]用于文本分类的图形卷积网络
[13]用于文本分类的张量图卷积网络
[14]对半监督学习的图形卷积网络的更深入见解


