NLPGNN
1.0.0
自然言語処理の分野は現在、大きな変化を遂げており、近年、Bert、GPTなどを含む多くの優れたモデルが提案されています。
同時に、テキストGCNやテンソルテキストGCNなどの自然言語処理の分野では、絶妙なデザインとしてのグラフニューラルネットワークが常に使用されています。
このツールボックスは、自然言語処理専用であり、最も簡単な方法でモデルを実装することを期待しています。
キーワード:NLP; GNN
モデル:
例(詳細については、テストを参照):
上記のすべての実験は、メモリ8000mibでGTX 1080 GPUでテストされました。
2020/5/ - :プロジェクト名をfennlpからnlpgnnに変換します。
2020/5/17:Bertの注意マトリックスに基づいて、文をグラフに変換してみてくださいが、失敗しました。このセクションでは、Bertの注意マトリックスを視覚化するソリューションを提供します。詳細については、辞書「Bert-GCN」を確認できます。
2020/5/11:テキスト分類のためにTextGCNとテキストを追加します。
2020/5/5:グラフクラスフィケーションのジン、グラフセージを追加します。
2020/4/25:メッセージの通過方法に基づいて、GAN、GINモデルを追加します。
2020/4/23:メッセージの通過方法に基づいて、GCNモデルを追加します。
2020/4/16:現在、NLPのGNNのモデルに焦点を当てており、一部のGNNモデルをFENNLPに統合しようとしています。
2020/4/2:GPT2モデルを追加して、Openai(ベース、中、大)によってリリースされたパラメーターを使用できます。詳細参照辞書「TG/EN/Interactive.py」
2020/3/26:分類のためにBilstm+注意の例を追加します
2020/3/23:ラダムオプティマイザーを追加します。
2020/3/19:テストの例を追加「albert_ner_train.py "" albert_ner_test.py "
2020/3/16:BPEメソッドに基づいてトレーニングサブワード埋め込みのモデルを追加します。訓練された埋め込みは、改善のためにTextCNNモデルで使用されます。詳細については、「tran_bpe_embeding.py」を参照してください。
2020/3/8:WN18の列車タッカーのテスト例「run_tucker.py」を追加します。
2020/3/3:Train TextCNNモデルのテスト例「TRAN_TEXT_CNN.PY」を追加します。
2020/3/2:BERTに基づくテキスト分類のために、テスト例「train_bert_classification.py」を追加します。
git clone https://github.com/kyzhouhzau/NLPGNN.git
python setup.py install
python bert_ner_train.py
「入力」辞書に列車、有効なファイル、テストファイルを置きます。
データ形式:「テスト ner input train」の参照データ
例「ランクlankl」对破骨细细胞作。oooo b-anatomy i-anatomy i-anatomy e-anatomy ooooo」
電車の各線には2つの部分が含まれています。最初の部分「拮抗抗抗对对骨细胞作」は文です。 2番目の部分「oooo b-anatomy i-anatomy i-anatomy e-anatomy ooooo」は、文の各単語のタグです。どちらも「 t」を使用して連結します。
from nlpgnn . models import bert
bert = bert . BERT () python bert_ner_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
=================================================================
Total params: 101,712,430
Trainable params: 101,712,430
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import bert
from nlpgnn . metrics . crf import CrfLogLikelihood
bert = bert . BERT ()
crf = CrfLogLikelihood () python bert_ner_crf_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
_________________________________________________________________
crf (CrfLogLikelihood) multiple 2116
=================================================================
Total params: 101,714,546
Trainable params: 101,714,546
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import albert
bert = albert . ALBERT () python albert_ner_train.py
large
Model: "albert_ner"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
albert (ALBERT) multiple 11092992
_________________________________________________________________
dense (Dense) multiple 6921
=================================================================
Total params: 11,099,913
Trainable params: 11,099,913
Non-trainable params: 0
_________________________________________________________________
デフォルトのパラメーターを使用して、「中文糖尿病标注数据集」および「conll-2003」有効なデータで次の結果が得られます。
| モデル | マクロ-F1 | マクロ-P | マクロ-R | LR | エポック | マクレン | batch_size | データ |
|---|---|---|---|---|---|---|---|---|
| Bert+Base | 0.7005 | 0.7244 | 0.7031 | 2E-5 | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| Bert+Base+CRF | 0.7009 | 0.7237 | 0.7041 | 2e-5(bert)、2e-3(crf) | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| Bert+Base | 0.9128 | 0.9208 | 0.9227 | 2E-5 | 5 | 128 | 8 | CONLL-2003 |
| アルバート+ベース | 0.8512 | 0.8678 | 0.8589 | 1E-4 | 8 | 128 | 16 | CONLL-2003 |
| アルバート+大 | 0.8670 | 0.8778 | 0.8731 | 2E-5 | 10 | 128 | 4 | CONLL-2003 |
「入力」辞書に列車、有効なファイル、テストファイルを置きます。
データ形式:「 tests cls bert(またはalbert) input」の参照データ。
例:「作为」地上上经经强的拳之一、小小小里琴科谈谈己否会2 ""
列車内の各ライン(テスト、有効)には2つの部分が含まれています。最初の部分には「作为地球上曾经最强的拳王之、小小」小克里琴琴谈谈自己己出」は文です。
from nlpgnn . models import bert
bert = bert . BERT () python train_bert_classification.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 102267648
_________________________________________________________________
dense (Dense) multiple 11535
=================================================================
Total params: 102,279,183
Trainable params: 102,279,183
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import TextCNN
model = TextCNN . TextCNN () python train_text_cnn.py
Use "WordPiece embedding" to Initialize word embedding. Train your embeddings.
python train_bpe_embedding.py
詳細については、WordPieceを参照してください
デフォルトのパラメーターを使用して、「新闻标题短文本分类」およびSST-2有効なデータで次の結果が得られます。
| モデル | acc | LR | エポック | マクレン | batch_size | データ |
|---|---|---|---|---|---|---|
| Bert+Base | 0.8899 | 1E-5 | 5 | 50 | 32 | 新闻标题短文本分类 |
| Bert+Base | 0.9266 | 2E-5 | 3 | 128 | 8 | SST-2 |
| アルバート+ベース | 0.9186 | 1E-5 | 3 | 128 | 16 | SST-2 |
| アルバート+大 | 0.9461 | 1E-6 | 3 | 128 | 4 | SST-2 |
| bilstm+注意 | 0.8269 | 0.01 | 3 | 128 | 64 | SST-2 |
| textcnn | 0.8233 | 0.01 | 3 | 128 | 64 | SST-2 |
from nlpgnn . models import gpt2
bert = gpt2 . GPT2 () python interactive.py
Model: "gen_gp_t2" base
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gpt2 (GPT2) multiple 124439808
=================================================================
Total params: 124,439,808
Trainable params: 124,439,808
Non-trainable params: 0
_________________________________________________________________
例:
Input >>> Stocks continue to fall this week
Output >>> as stocks fall for the second consecutive week as investors flee for safe havens.
"The market is off the charts," said John Schmieding, senior vice president, market strategy at RBC Capital Markets.
"We don't know what the Fed's intent is on, what direction it's going in. We don't know where they plan to go.
We don't know what direction they're going to move into."
テンソルボードは、損失を視覚化し、インジケーターを評価するのに役立ちます。
ユーザー:
tensorboard --port 6006 --logdir="./tensorboard"
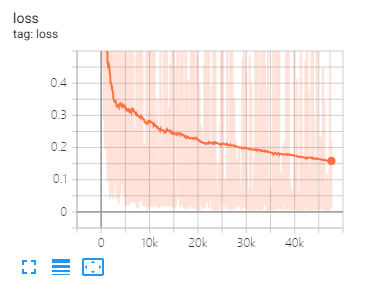
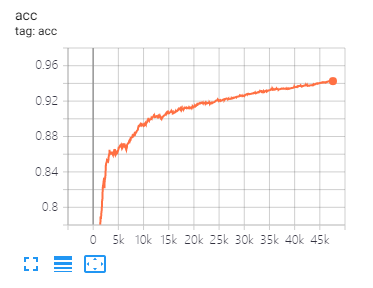
このペーパーで提案されているのと同じデータの分割とパラメーター設定
| モデル | コラ | PubMed | 引用者 |
|---|---|---|---|
| GCN | 81.80 | 79.50 | 71.20 |
| ガン | 83.00 | 79.00 | 72.30 |
| ガエ | 82.40 | 79.60 | 71.70 |
| モデル | ミュータグ | タンパク質 | NCI1 |
|---|---|---|---|
| ジン | 87.62±8.76 # | 73.05±1.85 # | 73.13±5.57 # |
| グラフセージ | 86.06±8.26 | 75.11±2.87 | 76.91±3.45 |
注:#記号は、現在の結果が紙の結果よりも小さいことを示しています。論文では、著者はこの方法を使用してモデルを評価します。この方法は時間がかかります。だから私はここでそのようにそれをしませんでした。
| モデル | R8 | R52 |
|---|---|---|
| テキスト | 96.68±0.42 | 92.80±0.32 |
| textgcn2019 | 97.108±0.243 | 92.512±0.249 |
1 ingling英語のタスクの場合、トークンザーがケースを正しく区別できるように、前処理された入力データと一致するように、パラメーター(fennlp.datas.checkpoint.loadcheckpoint)を設定する必要があります。
2 bert BertまたはAlbertを使用する場合、次のパラメーターが必要です。
param.maxlen
param.label_size
param.batch_size
label_sizeのカウントがわからない場合、スクリプトは、最初に電車のコードを実行したときに教えてくれます。
3、学習率とbatch_sizeはモデルの収束を決定します。詳細については、リンクを参照してください。
4 bertとアルバートのオプティマイザーに慣れていない場合、それは問題ではありません。覚えておくべき最も重要なことは、パラメーター「Learning_rate」と「Decay_Steps」(fennlp.optimizers.optim.adamwarmup)が重要であることです。 「学習率」を比較的小さな値に設定し、「Decay_Steps」をサンプル*Epoch/batch_sizeまたは少し高くすることができます。
5 codeコードが遅くなっていることがわかった場合は、 @ tf.functionを使用して、適切なモデルの書き込みと評価の頻度を設定してください。
6 fury「[email protected]」で私を連結できる他の問題または問題の質問をすることができます。
[1] Bert:言語理解のための深い双方向変圧器の事前訓練
[2]アルバート:言語表現の自己監督の学習のためのライトバート
[3]言語モデルは、教師のないマルチタスク学習者です
[4]量子化学のための神経メッセージの合格
[5]グラフ畳み込みネットワークを使用した半監視分類
[6]注目ネットワークをグラフ
[7]グラフニューラルネットワークはどの程度強力ですか?
[8]グラフセージ:大きなグラフでの誘導表現学習
[9]拡散により、グラフ学習が改善されます
[10]ベンチマークグラフニューラルネットワーク
[11]テキストレベルグラフテキスト分類のためのニューラルネットワーク
[12]テキスト分類のためのグラフ畳み込みネットワーク
[13]テキスト分類のためのテンソルグラフ畳み込みネットワーク
[14]半教師の学習のためのグラフ畳み込みネットワークへのより深い洞察


