NLPGNN
1.0.0
Le domaine du traitement du langage naturel subit actuellement d'énormes changements, et de nombreux excellents modèles ont été proposés ces dernières années, notamment Bert, GPT, etc.
Dans le même temps, le réseau neuronal graphique en tant que conception exquis est constamment utilisé dans le domaine du traitement du langage naturel, tel que TextGCN et Tensor-TextGCN.
Cette boîte à outils est dédiée au traitement du langage naturel et prévoit d'implémenter des modèles de manière la plus simple.
Mots-clés: NLP; Gnn
Modèles:
Exemples (voir les tests pour plus de détails):
Toutes les expériences ci-dessus ont été testées sur GTX 1080 GPU avec la mémoire 8000MIB.
2020/5 / --:: convertissez le nom du projet en NLPGNN de FennLP.
2020/5/17: Essayez de convertir la phrase en graphique en fonction de la matrice d'attention Bert, mais a échoué. Cette section fournit une solution pour visualiser la matrice d'attention Bert. Pour plus de détails, vous pouvez consulter le dictionnaire "Bert-GCN".
2020/5/11: Ajouter TextGCN et TextSage pour la classification du texte.
2020/5/5: Ajouter du gin, graphique pour graphique Classfication.
2020/4/25: Ajouter Gan, modèle de gin, basé sur des méthodes de passage de messages.
2020/4/23: Ajouter un modèle GCN, en fonction des méthodes de passage de messages.
2020/4/16: se concentrer actuellement sur les modèles de GNN dans NLP et essayer d'intégrer certains modèles GNN dans FennLP.
2020/4/2: Ajouter un modèle GPT2, pourrait utiliser des paramètres publiés par OpenAI (base, moyen, grand). Plus de détails Dictionnaire de référence "tg / en / interactive.py"
2020/3/26: Ajouter un exemple d'attention Bilstm + pour la classification
2020/3/23: Ajouter un Radam Optimizer.
2020/3/19: Ajouter un exemple de test "albert_ner_train.py" "albert_ner_test.py"
2020/3/16: Ajouter un modèle pour la formation de sous-mots de formation basé sur les méthodes BPE. L'intégration formée est utilisée dans le modèle TextCNN pour améliorer son amélioration. Voir "TRAN_BPE_EMBEDING.PY" pour plus de détails.
2020/3/8: Ajoutez un exemple de test "run_tucker.py" pour le train Tucker sur WN18.
2020/3/3: Ajouter un exemple de test "TRAN_TTEXT_CNN.PY" pour le modèle Train TextCNN.
2020/3/2: Ajouter un exemple de test "Train_bert_classification.py" pour la classification du texte basé sur Bert.
git clone https://github.com/kyzhouhzau/NLPGNN.git
python setup.py install
python bert_ner_train.py
Mettez le fichier Train, valide et test dans le dictionnaire "d'entrée".
Format de données: données de référence dans "Tests ner Input Train"
par exemple "拮 抗 rankl 对 破 骨 细 胞 的 作 用。 oooo b-anatomie i-anatomie i-anatomie e-anatomy oooo"
Pour chaque ligne dans le train contient deux parties, la première partie "拮 抗 Rankl 对 破 骨 细 胞 的 作 用 用。。" est une phrase. La deuxième partie "Oooo b-anatomy i-anatomy i-anatomy e-anatomy oooo" est l'étiquette de chaque mot de la phrase. Les deux utilisent « t» pour concaténer.
from nlpgnn . models import bert
bert = bert . BERT () python bert_ner_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
=================================================================
Total params: 101,712,430
Trainable params: 101,712,430
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import bert
from nlpgnn . metrics . crf import CrfLogLikelihood
bert = bert . BERT ()
crf = CrfLogLikelihood () python bert_ner_crf_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
_________________________________________________________________
crf (CrfLogLikelihood) multiple 2116
=================================================================
Total params: 101,714,546
Trainable params: 101,714,546
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import albert
bert = albert . ALBERT () python albert_ner_train.py
large
Model: "albert_ner"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
albert (ALBERT) multiple 11092992
_________________________________________________________________
dense (Dense) multiple 6921
=================================================================
Total params: 11,099,913
Trainable params: 11,099,913
Non-trainable params: 0
_________________________________________________________________
En utilisant les paramètres par défaut, nous obtenons les résultats suivants sur les données valides "中文糖尿病标注数据集" et "CONLL-2003".
| modèle | macro-f1 | macro-p | macro-r | LR | époque | maxlen | batch_size | données |
|---|---|---|---|---|---|---|---|---|
| Bert + base | 0,7005 | 0,7244 | 0,7031 | 2E-5 | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| Bert + base + CRF | 0,7009 | 0,7237 | 0,7041 | 2E-5 (Bert), 2E-3 (CRF) | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| Bert + base | 0,9128 | 0.9208 | 0,9227 | 2E-5 | 5 | 128 | 8 | Conll-2003 |
| ALBERT + BASE | 0,8512 | 0,8678 | 0,8589 | 1E-4 | 8 | 128 | 16 | Conll-2003 |
| Albert + grand | 0,8670 | 0,8778 | 0,8731 | 2E-5 | 10 | 128 | 4 | Conll-2003 |
Mettez le fichier Train, valide et test dans le dictionnaire "d'entrée".
Format de données: données de référence dans " tests cls bert (ou albert) entrée".
par exemple "作 为 地 球 上 曾 经 最 强 的 拳 王 之 一 , 小 克 里 琴 科 谈 自 己 是 否 会 复 出 2"
Pour chaque ligne dans le train (test, valide) contient deux parties, la première partie "作 为 地 球 上 曾 经 最 强 的 拳 王 之 一 , 小 克 里 琴 科 谈 自 己 是 否 会 复 出 出 小 克 琴 科 谈 自 己 是 否 会 复 出 出" est la phrase, et la deuxième partie "2" est l'étiquette.
from nlpgnn . models import bert
bert = bert . BERT () python train_bert_classification.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 102267648
_________________________________________________________________
dense (Dense) multiple 11535
=================================================================
Total params: 102,279,183
Trainable params: 102,279,183
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import TextCNN
model = TextCNN . TextCNN () python train_text_cnn.py
Use "WordPiece embedding" to Initialize word embedding. Train your embeddings.
python train_bpe_embedding.py
Pour plus de détails, référence de référence pièce
En utilisant les paramètres par défaut, nous obtenons les résultats suivants sur les données valides "新闻标题短文本分类" et SST-2.
| modèle | Accrocheur | LR | époque | maxlen | batch_size | données |
|---|---|---|---|---|---|---|
| Bert + base | 0,8899 | 1E-5 | 5 | 50 | 32 | 新闻标题短文本分类 |
| Bert + base | 0,9266 | 2E-5 | 3 | 128 | 8 | SST-2 |
| ALBERT + BASE | 0,9186 | 1E-5 | 3 | 128 | 16 | SST-2 |
| Albert + grand | 0,9461 | 1E-6 | 3 | 128 | 4 | SST-2 |
| Bilstm + attention | 0,8269 | 0,01 | 3 | 128 | 64 | SST-2 |
| Textcnn | 0,8233 | 0,01 | 3 | 128 | 64 | SST-2 |
from nlpgnn . models import gpt2
bert = gpt2 . GPT2 () python interactive.py
Model: "gen_gp_t2" base
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gpt2 (GPT2) multiple 124439808
=================================================================
Total params: 124,439,808
Trainable params: 124,439,808
Non-trainable params: 0
_________________________________________________________________
Exemple:
Input >>> Stocks continue to fall this week
Output >>> as stocks fall for the second consecutive week as investors flee for safe havens.
"The market is off the charts," said John Schmieding, senior vice president, market strategy at RBC Capital Markets.
"We don't know what the Fed's intent is on, what direction it's going in. We don't know where they plan to go.
We don't know what direction they're going to move into."
Tensorboard peut vous aider à visualiser les pertes et à évaluer les indicateurs:
Utilisation:
tensorboard --port 6006 --logdir="./tensorboard"
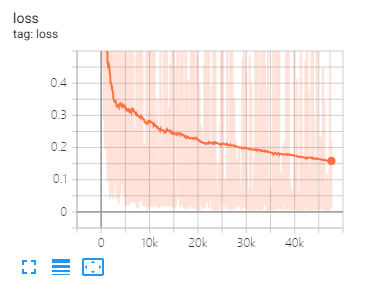
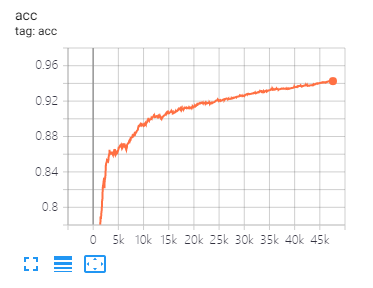
SIGNIFICATION DES DONNÉES ET RÉGLAGE DE PARAMETERS comme proposé dans cet article
| modèle | Cora | Pubment | Ciseuse |
|---|---|---|---|
| GCN | 81.80 | 79.50 | 71.20 |
| Gan | 83,00 | 79.00 | 72.30 |
| Gae | 82.40 | 79.60 | 71.70 |
| modèle | Mutag | Protéines | Nci1 |
|---|---|---|---|
| GIN | 87,62 ± 8,76 # | 73,05 ± 1,85 # | 73,13 ± 5,57 # |
| Graphique | 86,06 ± 8,26 | 75,11 ± 2,87 | 76,91 ± 3,45 |
Remarque: le signe # indique que le résultat actuel est inférieur au résultat du papier. Dans l'article, l'auteur utilise cette méthode pour évaluer les modèles. Cette méthode est du temps coûteuse. Je ne l'ai donc pas fait comme ça ici.
| modèle | R8 | R52 |
|---|---|---|
| Texto | 96,68 ± 0,42 | 92,80 ± 0,32 |
| TextGCN2019 | 97,108 ± 0,243 | 92,512 ± 0,249 |
1 、 Pour les tâches anglaises, vous devez définir le paramètre "Basé" (dans Fennlp.Datas.Checkpoint.Loadcheckpoint) pour être cohérent avec vos données d'entrée prétraitées pour vous assurer que le tokenzer peut distinguer correctement le cas.
2 、 Lorsque vous utilisez Bert ou Albert, les paramètres suivants sont nécessaires:
param.maxlen
param.label_size
param.batch_size
Si vous ne connaissez pas le nombre de label_size, le script vous dira quand vous exécutez les codes de train pour la première fois.
3 、 Le taux d'apprentissage et Batch_Size détermineront la convergence du modèle, voir le lien pour plus de détails.
4 、 Si vous n'êtes pas familier avec l'optimiseur de Bert et Albert, cela n'a pas d'importance. La chose la plus importante dont vous devez vous souvenir est que les paramètres "Learning_rate" et "Decay_steps" (dans Fennlp.optimizers.optim.adamwarmUp) est important. Vous pouvez définir le "taux d'apprentissage" sur une valeur relativement petite et laisser "Decay_Steps" égal aux échantillons * Epoch / Batch_Size ou peu plus.
5 、 Si vous constatez que le code s'exécute plus lent, vous pouvez essayer d'utiliser @ tf.function et définir la fréquence d'écriture et d'évaluation du modèle approprié.
6 、 Tout autre problème que vous pouvez me concater par "[email protected]" ou poser des questions en problème.
[1] Bert: pré-formation des transformateurs bidirectionnels profonds pour la compréhension du langage
[2] Albert: A Lite Bert pour l'apprentissage auto-supervisé des représentations de la langue
[3] Les modèles linguistiques sont des apprenants multiples non surveillés
[4] Message neuronal passant pour la chimie quantique
[5] Classification semi-supervisée avec des réseaux convolutionnels graphiques
[6] Graphiques réseaux d'attention
[7] Quelle est la puissance des réseaux de neurones graphiques?
[8] Graphique: Représentation inductive Apprentissage sur de gros graphiques
[9] La diffusion améliore l'apprentissage du graphique
[10] Réseaux de neurones graphiques d'analyse comparative
[11] Réseau neuronal du graphique de niveau de texte pour la classification du texte
[12] Réseaux convolutionnels graphiques pour la classification du texte
[13] Réseaux de convolution des graphiques du tenseur pour la classification du texte
[14] Des informations plus approfondies sur les réseaux de convolution des graphiques pour l'apprentissage semi-supervisé


