NLPGNN
1.0.0
Сфера обработки естественного языка в настоящее время претерпевает огромные изменения, и в последние годы было предложено много превосходных моделей, включая BERT, GPT и т. Д.
В то же время, нейронная сеть графика как изысканный дизайн постоянно используется в области обработки естественного языка, таких как TextGCN и Tensor-TextGCN.
Этот набор инструментов посвящен обработке естественного языка и рассчитывает проще реализовать модели.
Ключевые слова: NLP; Г -н
Модели:
Примеры (см. Тесты для более подробной информации):
Все вышеперечисленные эксперименты были протестированы на графическом процессоре GTX 1080 с памятью 8000 миб.
2020/5/-: конвертировать имя проекта в NLPGNN из Fennlp.
2020/5/17: Попробуйте преобразовать предложение на график на основе матрицы внимания, но не удалось. Этот раздел предоставляет решение для визуализации матрицы внимания BERT. Для получения более подробной информации вы можете проверить словарь «Bert-GCN».
2020/5/11: Добавить TextGCN и текстовые тексты для классификации текста.
2020/5/5: добавить джин, график для графического класса.
2020/4/25: добавить модель Gan, джин, на основе методов передачи сообщений.
2020/4/23: добавить модель GCN, основанную на методах передачи сообщений.
2020/4/16: в настоящее время сосредоточен на моделях GNN в NLP и пытается интегрировать некоторые модели GNN в FennLP.
2020/4/2: добавить модель GPT2, может использовать параметры, высвобождаемые OpenAI (Base, Medium, большой). Более подробная справочная словарь "tg/en/interactive.py"
2020/3/26: Добавить пример Bilstm+внимания для классификации
2020/3/23: Добавить радар оптимизатор.
2020/3/19: добавить пример теста "albert_ner_train.py" "albert_ner_test.py"
2020/3/16: Добавьте модель для обучения внедрения Sub Word на основе методов BPE. Обученное встроение используется в модели TextCnn для улучшения его улучшения. См. «Tran_bpe_embeding.py» для более подробной информации.
2020/3/8: добавьте пример теста "run_tucker.py" для Train Tucker на WN18.
2020/3/3: добавить пример теста "tran_text_cnn.py" для модели Train TextCnn.
2020/3/2: добавьте пример теста "train_bert_classification.py" для классификации текста на основе Bert.
git clone https://github.com/kyzhouhzau/NLPGNN.git
python setup.py install
python bert_ner_train.py
Поместите поезд, допустимый и тестовый файл в словарь «вход».
Формат данных: справочные данные в «Tests ner Input Train»
Например, "拮 抗 rankl 对 骨 细 胞 的 作 用。。 oooo b-anatomy i-anatomy i-anatomy e-anatomy ooooo"
Для каждой строки в поезде содержится две части, первая часть «拮 抗 抗 对 破 骨 细 胞 的 作 用。» является предложением. Вторая часть «Oooo B-Anatomy i-Anatomy i-Anatomy E-Anatomy Oooo» является тегом для каждого слова в предложении. Оба они используют ' t' для объединения.
from nlpgnn . models import bert
bert = bert . BERT () python bert_ner_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
=================================================================
Total params: 101,712,430
Trainable params: 101,712,430
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import bert
from nlpgnn . metrics . crf import CrfLogLikelihood
bert = bert . BERT ()
crf = CrfLogLikelihood () python bert_ner_crf_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
_________________________________________________________________
crf (CrfLogLikelihood) multiple 2116
=================================================================
Total params: 101,714,546
Trainable params: 101,714,546
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import albert
bert = albert . ALBERT () python albert_ner_train.py
large
Model: "albert_ner"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
albert (ALBERT) multiple 11092992
_________________________________________________________________
dense (Dense) multiple 6921
=================================================================
Total params: 11,099,913
Trainable params: 11,099,913
Non-trainable params: 0
_________________________________________________________________
Используя параметры по умолчанию, мы получаем следующие результаты на допустимых данных «中文糖尿病标注数据集» и «conll-2003».
| модель | макро-F1 | макро-п | макро-р | лр | эпоха | Макслен | batch_size | данные |
|---|---|---|---|---|---|---|---|---|
| Берт+База | 0,7005 | 0,7244 | 0,7031 | 2E-5 | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| Bert+Base+CRF | 0,7009 | 0,7237 | 0,7041 | 2e-5 (bert), 2E-3 (CRF) | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| Берт+База | 0,9128 | 0,9208 | 0,9227 | 2E-5 | 5 | 128 | 8 | Conll-2003 |
| Альберт+База | 0,8512 | 0,8678 | 0,8589 | 1E-4 | 8 | 128 | 16 | Conll-2003 |
| Альберт+большой | 0,8670 | 0,8778 | 0,8731 | 2E-5 | 10 | 128 | 4 | Conll-2003 |
Поместите поезд, допустимый и тестовый файл в словарь «вход».
Формат данных: Справочные данные в « tests cls bert (или albert) input».
например, "作 地 球 上 曾 经 最 强 的 拳 王 一 , 小 克 里 琴 科 谈 己 是 否 会 复 出 2"
Для каждой строки в поезде (тест, допустимый) содержит две части: первая часть «作 为 地 上 曾 经 最 强 的 拳 王 之 , , 克 里 琴 科 自 己 是 否 会 复 出» - это предложение, а вторая часть «2» - это метка.
from nlpgnn . models import bert
bert = bert . BERT () python train_bert_classification.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 102267648
_________________________________________________________________
dense (Dense) multiple 11535
=================================================================
Total params: 102,279,183
Trainable params: 102,279,183
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import TextCNN
model = TextCNN . TextCNN () python train_text_cnn.py
Use "WordPiece embedding" to Initialize word embedding. Train your embeddings.
python train_bpe_embedding.py
Для получения более подробной информации о ссылке слов
Используя параметры по умолчанию, мы получаем следующие результаты на «新闻标题短文本分类» и допустимых данных SST-2.
| модель | Акк | лр | эпоха | Макслен | batch_size | данные |
|---|---|---|---|---|---|---|
| Берт+База | 0,8899 | 1e-5 | 5 | 50 | 32 | 新闻标题短文本分类 |
| Берт+База | 0,9266 | 2E-5 | 3 | 128 | 8 | SST-2 |
| Альберт+База | 0,9186 | 1e-5 | 3 | 128 | 16 | SST-2 |
| Альберт+большой | 0,9461 | 1e-6 | 3 | 128 | 4 | SST-2 |
| Bilstm+внимание | 0,8269 | 0,01 | 3 | 128 | 64 | SST-2 |
| TextCnn | 0,8233 | 0,01 | 3 | 128 | 64 | SST-2 |
from nlpgnn . models import gpt2
bert = gpt2 . GPT2 () python interactive.py
Model: "gen_gp_t2" base
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gpt2 (GPT2) multiple 124439808
=================================================================
Total params: 124,439,808
Trainable params: 124,439,808
Non-trainable params: 0
_________________________________________________________________
Пример:
Input >>> Stocks continue to fall this week
Output >>> as stocks fall for the second consecutive week as investors flee for safe havens.
"The market is off the charts," said John Schmieding, senior vice president, market strategy at RBC Capital Markets.
"We don't know what the Fed's intent is on, what direction it's going in. We don't know where they plan to go.
We don't know what direction they're going to move into."
Tensorboard может помочь вам визуализировать потери и оценить индикаторы:
Повышение:
tensorboard --port 6006 --logdir="./tensorboard"
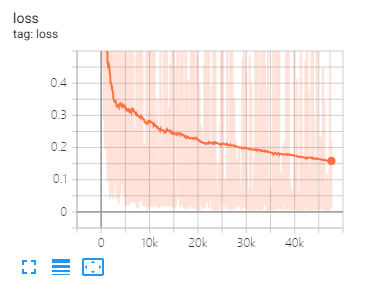
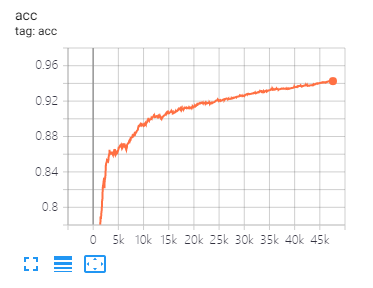
Настройка и то же разделение данных и параметры, как предложено в этой статье
| модель | Кора | PubMed | Citeseer |
|---|---|---|---|
| GCN | 81.80 | 79,50 | 71.20 |
| Ган | 83,00 | 79,00 | 72.30 |
| Газа | 82,40 | 79,60 | 71.70 |
| модель | Мутаг | Белки | NCI1 |
|---|---|---|---|
| ДЖИН | 87,62 ± 8,76 # | 73,05 ± 1,85 # | 73,13 ± 5,57 # |
| График | 86,06 ± 8,26 | 75,11 ± 2,87 | 76,91 ± 3,45 |
Примечание. Знак # указывает, что текущий результат меньше, чем результат бумаги. В статье автор использует этот метод для оценки моделей. Этот метод дорогой. Так что я не делал этого здесь.
| модель | R8 | R52 |
|---|---|---|
| Тексты | 96,68 ± 0,42 | 92,80 ± 0,32 |
| TextGCN2019 | 97,108 ± 0,243 | 92,512 ± 0,249 |
1 、 Для английских задач вам необходимо установить параметр «cassed» (в fennlp.datas.checkpoint.loadcheckpoint), чтобы соответствовать вашим предварительному входным данным, чтобы гарантировать, что токенизатор может правильно отличить.
2 、 Когда вы используете Bert или Albert, необходимы следующие параметры:
param.maxlen
param.label_size
param.batch_size
Если вы не знаете количество label_size, сценарий скажет вам, когда вы впервые запускаете коды поездов.
3 、 Скорость обучения и batch_size определят конвергенцию модели, см. Ссылку для получения более подробной информации.
4 、 Если вы не знакомы с оптимизатором в Берте и Альберте, это не имеет значения. Самое важное, что вам нужно помнить, это то, что параметры «Learning_Rate» и «decay_steps» (в fennlp.optimizers.optim.adamwarmup) важны. Вы можете установить «скорость обучения» на относительно небольшое значение, и позволить «Decay_steps», равным образцам*epoch/batch_size или немного выше.
5 、 Если вы обнаружите, что код работает медленнее, вы можете попытаться использовать @ tf.function и установить соответствующую частоту написания и оценки модели.
6 、 Любая другая проблема, которую вы можете связать со мной по адресу [email protected] »или задать вопросы.
[1] Берт: предварительное обучение глубоких двунаправленных трансформаторов для понимания языка
[2] Альберт: Lite Bert для самоотверженного изучения языковых представлений
[3] Языковые модели - это неконтролируемые многозадачные ученики
[4] Прохождение нейронного сообщения для квантовой химии
[5] Полупроницаемая классификация с графическими сверточными сетями
[6] Графические сети внимания
[7] Насколько мощными графические нейронные сети?
[8] График: индуктивное представление, обучение на больших графиках
[9] Диффузия улучшает графическое обучение
[10] Нейронные сети сравнительного анализа.
[11] Нейронная сеть графика текста для классификации текста для классификации текста
[12] Графические сверточные сети для классификации текста
[13] Спутниковые сети с тензором для классификации текста для классификации текста
[14] Более глубокое понимание графических сверточных сетей для полупрофильного обучения


