NLPGNN
1.0.0
자연 언어 처리 분야는 현재 엄청난 변화를 겪고 있으며 최근 몇 년 동안 Bert, GPT 등을 포함한 많은 우수한 모델이 제안되었습니다.
동시에, 절묘한 설계로서의 그래프 신경망은 TextGCN 및 Tensor-TextGCN과 같은 자연어 처리 분야에서 지속적으로 사용되고 있습니다.
이 도구 상자는 자연어 처리에 전념하며 가장 간단한 방식으로 모델을 구현할 것으로 기대합니다.
키워드 : NLP; Gnn
모델 :
예제 (자세한 내용은 테스트 참조) :
위의 모든 실험을 메모리 8000mib로 GTX 1080 GPU에서 테스트 하였다.
2020/5/-: 프로젝트 이름을 fennlp에서 nlpgnn으로 변환합니다.
2020/5/17 : Bert주의 매트릭스를 기반으로 문장을 그래프로 변환하려고하지만 실패했습니다. 이 섹션에서는 Bert주의 매트릭스를 시각화하는 솔루션을 제공합니다. 자세한 내용은 사전 "Bert-GCN"을 확인할 수 있습니다.
2020/5/11 : 텍스트 분류를 위해 TextGCN 및 TextSage를 추가하십시오.
2020/5/5 : GIN을 추가하고 그래프 클래스 픽션을 위해 그래프를 그래지합니다.
2020/4/25 : 메시지 전달 방법을 기반으로 GAN, GIN 모델을 추가하십시오.
2020/4/23 : 메시지 전달 방법을 기반으로 GCN 모델을 추가하십시오.
2020/4/16 : 현재 NLP의 GNN 모델에 중점을두고 있으며 일부 GNN 모델을 FENNLP에 통합하려고합니다.
2020/4/2 : GPT2 모델 추가, OpenAI (Base, Medium, Large)에서 방출 된 매개 변수를 사용할 수 있습니다. 자세한 내용 참조 사전 "Tg/en/Interactive.py"
2020/3/26 : 분류를 위해 BILSTM+주의 예제를 추가하십시오
2020/3/23 : Radam Optimizer를 추가하십시오.
2020/3/19 : 테스트 예제 "Albert_ner_train.py" "Albert_ner_test.py"
2020/3/16 : BPE 방법을 기반으로 한 하위 단어 임베딩을위한 모델 추가. 훈련 된 임베딩은 개선을 위해 TextCNN 모델에 사용됩니다. 자세한 내용은 "tran_bpe_embeding.py"를 참조하십시오.
2020/3/8 : WN18의 Train Tucker에 대한 "run_tucker.py"테스트 예제를 추가하십시오.
2020/3/3 : Train TextCnn 모델에 대한 "Tran_Text_cnn.py"테스트 예제 추가 예제를 추가하십시오.
2020/3/2 : Bert를 기반으로 텍스트 분류를 위해 "Train_bert_classification.py"테스트 예제를 추가하십시오.
git clone https://github.com/kyzhouhzau/NLPGNN.git
python setup.py install
python bert_ner_train.py
"입력"사전에 열차, 유효한 및 테스트 파일을 넣으십시오.
데이터 형식 : "테스트 ner input train"의 참조 데이터
EG "抗 拮 rankl 对 破 破 骨 细 胞 胞 的 作 作 用。。。 oooo b- 해부학 I- 해부학 I- 해부학 e- 해부학 OOOO"
열차의 각 라인마다 두 부분이 포함되어 있습니다. 첫 번째 부분 "拮 抗 rantl 对 破 骨 细 细 胞 的 作 用。。"부분은 문장입니다. 두 번째 부분 "OOOO B-Anatomy I- 해부학 I- 해부학 E- 해부학 OOOO"는 문장의 각 단어에 대한 태그입니다. 둘 다 ' t'를 사용하여 연결합니다.
from nlpgnn . models import bert
bert = bert . BERT () python bert_ner_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
=================================================================
Total params: 101,712,430
Trainable params: 101,712,430
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import bert
from nlpgnn . metrics . crf import CrfLogLikelihood
bert = bert . BERT ()
crf = CrfLogLikelihood () python bert_ner_crf_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
_________________________________________________________________
crf (CrfLogLikelihood) multiple 2116
=================================================================
Total params: 101,714,546
Trainable params: 101,714,546
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import albert
bert = albert . ALBERT () python albert_ner_train.py
large
Model: "albert_ner"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
albert (ALBERT) multiple 11092992
_________________________________________________________________
dense (Dense) multiple 6921
=================================================================
Total params: 11,099,913
Trainable params: 11,099,913
Non-trainable params: 0
_________________________________________________________________
기본 매개 변수를 사용하면 "中文糖尿病标注数据集"및 "Conll-2003"유효한 데이터에 대한 다음 결과가 나타납니다.
| 모델 | 매크로 -F1 | 매크로 -P | 매크로 -R | LR | 시대 | Maxlen | batch_size | 데이터 |
|---|---|---|---|---|---|---|---|---|
| 버트+베이스 | 0.7005 | 0.7244 | 0.7031 | 2E-5 | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| 버트+베이스+CRF | 0.7009 | 0.7237 | 0.7041 | 2E-5 (버트), 2E-3 (CRF) | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| 버트+베이스 | 0.9128 | 0.9208 | 0.9227 | 2E-5 | 5 | 128 | 8 | Conll-2003 |
| 앨버트+베이스 | 0.8512 | 0.8678 | 0.8589 | 1E-4 | 8 | 128 | 16 | Conll-2003 |
| 앨버트+큰 | 0.8670 | 0.8778 | 0.8731 | 2E-5 | 10 | 128 | 4 | Conll-2003 |
"입력"사전에 열차, 유효한 및 테스트 파일을 넣으십시오.
데이터 형식 : " tests cls bert (또는 Albert) Input"의 참조 데이터.
예 : "为 作 地 地 球 上 曾 曾 经 最 最 强 强 拳 拳 王 之 一 一 一 一 一 一 里 里 里 琴 科 谈 自 己 是 是 否 会 复 出 2"
열차의 각 라인 (테스트, 유효)에는 두 부분이 포함되어 있습니다. 첫 번째 부분에는 첫 번째 부분 "作 为 地 地 球 上 曾 经 最 最 强 的 拳 王 之 之 一 一 一 一 一 一 一 之 一 之 之 之 否 否 否 否 否 出 出 出"2 "는"2 "는 라벨입니다.
from nlpgnn . models import bert
bert = bert . BERT () python train_bert_classification.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 102267648
_________________________________________________________________
dense (Dense) multiple 11535
=================================================================
Total params: 102,279,183
Trainable params: 102,279,183
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import TextCNN
model = TextCNN . TextCNN () python train_text_cnn.py
Use "WordPiece embedding" to Initialize word embedding. Train your embeddings.
python train_bpe_embedding.py
자세한 내용은 참조 워드 피스
기본 매개 변수를 사용하면 "新闻标题短文本分类"및 SST-2 유효한 데이터에 대한 다음 결과가 나타납니다.
| 모델 | acc | LR | 시대 | Maxlen | batch_size | 데이터 |
|---|---|---|---|---|---|---|
| 버트+베이스 | 0.8899 | 1E-5 | 5 | 50 | 32 | 新闻标题短文本分类 |
| 버트+베이스 | 0.9266 | 2E-5 | 3 | 128 | 8 | SST-2 |
| 앨버트+베이스 | 0.9186 | 1E-5 | 3 | 128 | 16 | SST-2 |
| 앨버트+큰 | 0.9461 | 1E-6 | 3 | 128 | 4 | SST-2 |
| bilstm+주의 | 0.8269 | 0.01 | 3 | 128 | 64 | SST-2 |
| TextCnn | 0.8233 | 0.01 | 3 | 128 | 64 | SST-2 |
from nlpgnn . models import gpt2
bert = gpt2 . GPT2 () python interactive.py
Model: "gen_gp_t2" base
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gpt2 (GPT2) multiple 124439808
=================================================================
Total params: 124,439,808
Trainable params: 124,439,808
Non-trainable params: 0
_________________________________________________________________
예:
Input >>> Stocks continue to fall this week
Output >>> as stocks fall for the second consecutive week as investors flee for safe havens.
"The market is off the charts," said John Schmieding, senior vice president, market strategy at RBC Capital Markets.
"We don't know what the Fed's intent is on, what direction it's going in. We don't know where they plan to go.
We don't know what direction they're going to move into."
Tensorboard는 손실을 시각화하고 지표를 평가하는 데 도움이됩니다.
사용 :
tensorboard --port 6006 --logdir="./tensorboard"
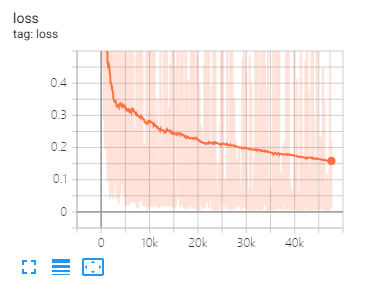
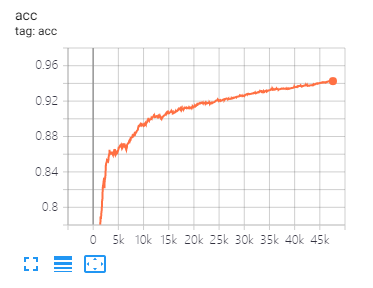
이 백서에서 제안한 것과 동일한 데이터 분할 및 매개 변수 설정
| 모델 | 코라 | PubMed | Citeseer |
|---|---|---|---|
| GCN | 81.80 | 79.50 | 71.20 |
| 간 | 83.00 | 79.00 | 72.30 |
| 가아 | 82.40 | 79.60 | 71.70 |
| 모델 | 돌연변이 | 단백질 | NCI1 |
|---|---|---|---|
| 진 | 87.62 ± 8.76 # | 73.05 ± 1.85 # | 73.13 ± 5.57 # |
| 그래프시 | 86.06 ± 8.26 | 75.11 ± 2.87 | 76.91 ± 3.45 |
참고 : # 부호는 현재 결과가 종이 결과보다 적다는 것을 나타냅니다. 논문에서 저자는이 방법을 사용하여 모델을 평가합니다. 이 방법은 시간이 많이 걸립니다. 그래서 나는 여기서 그렇게하지 않았습니다.
| 모델 | R8 | R52 |
|---|---|---|
| 텍스트 | 96.68 ± 0.42 | 92.80 ± 0.32 |
| TextGCN2019 | 97.108 ± 0.243 | 92.512 ± 0.249 |
1, 영어 작업의 경우 전처리 입력 데이터와 일치하도록 매개 변수 "Caseed"(Fennlp.datas.checkpoint.loadcheckpoint)을 설정하여 토 케이저가 케이스를 올바르게 구별 할 수 있도록 설정해야합니다.
2 ert Bert 또는 Albert를 사용하면 다음 매개 변수가 필요합니다.
param.maxlen
param.label_size
param.batch_size
label_size의 수를 모른다면 스크립트는 처음 열차 코드를 실행할 때 알려줍니다.
3 atch 학습 속도 및 batch_size는 모델 수렴을 결정합니다. 자세한 내용은 링크를 참조하십시오.
4 familiar Bert와 Albert의 Optimizer에 익숙하지 않다면 중요하지 않습니다. 기억해야 할 가장 중요한 것은 "Learning_rate"및 "Decay_steps"(fennlp.optimizers.optim.adamwarmup) 매개 변수가 중요하다는 것입니다. "학습 속도"를 상대적으로 작은 값으로 설정하고 "Decay_steps"를 샘플*epoch/batch_size 또는 거의 더 높게 만들 수 있습니다.
5 the 코드가 느리게 실행된다면 @ tf.function을 사용하고 적절한 모델 쓰기 및 평가 빈도를 설정하려고 시도 할 수 있습니다.
6 can "[email protected]"으로 저를 연결하거나 문제가있는 질문을 할 수 있습니다.
[1] Bert : 언어 이해를위한 깊은 양방향 변압기의 사전 훈련
[2] Albert : 언어 표현에 대한 자기 감독 학습을위한 라이트 버트
[3] 언어 모델은 감독되지 않은 멀티 태스킹 학습자입니다
[4] 양자 화학을위한 신경 메시지
[5] 그래프 컨볼 루션 네트워크를 사용한 반 감독 분류
[6] 그래프주의 네트워크
[7] 그래프 신경망은 얼마나 강력합니까?
[8] 그래프지 : 큰 그래프에서 유도 성 표현 학습
[9] 확산은 그래프 학습을 향상시킨다
[10] 벤치마킹 그래프 신경망
[11] 텍스트 분류를위한 텍스트 레벨 그래프 신경망
[12] 텍스트 분류를위한 그래프 컨볼 루션 네트워크
[13] 텍스트 분류를위한 텐서 그래프 컨볼 루션 네트워크
[14] 반 감독 학습을위한 그래프 컨볼 루션 네트워크에 대한 더 깊은 통찰력


