NLPGNN
1.0.0
Bidang pemrosesan bahasa alami saat ini sedang mengalami perubahan luar biasa, dan banyak model yang sangat baik telah diusulkan dalam beberapa tahun terakhir, termasuk Bert, GPT, dll.
Pada saat yang sama, grafik jaringan saraf sebagai desain yang indah terus digunakan di bidang pemrosesan bahasa alami, seperti TextGCN dan Tensor-TextGCN.
Kotak alat ini didedikasikan untuk pemrosesan bahasa alami dan mengharapkan untuk mengimplementasikan model dengan cara yang paling sederhana.
Kata kunci: NLP; GNN
Model:
Contoh (lihat tes untuk detail lebih lanjut):
Semua percobaan di atas diuji pada GPU GTX 1080 dengan memori 8000Mib.
2020/5/-: Konversi nama proyek menjadi NLPGNN dari Fennlp.
2020/5/17: Cobalah untuk mengonversi kalimat menjadi grafik berdasarkan matriks perhatian Bert, tetapi gagal. Bagian ini memberikan solusi untuk memvisualisasikan matriks perhatian Bert. Untuk detail lebih lanjut, Anda dapat memeriksa kamus "Bert-GCN".
2020/5/11: Tambahkan TextGCN dan TextSage untuk klasifikasi teks.
2020/5/5: Tambahkan gin, grafik untuk grafik classfication.
2020/4/25: Tambahkan GAN, Model Gin, berdasarkan metode lewat pesan.
2020/4/23: Tambahkan model GCN, berdasarkan metode pengisian pesan.
2020/4/16 : Saat ini berfokus pada model GNN di NLP, dan mencoba mengintegrasikan beberapa model GNN ke dalam Fennlp.
2020/4/2: Tambahkan model GPT2, dapat digunakan parameter yang dilepaskan oleh OpenAi (base, medium, besar). Kamus referensi detail lebih lanjut "tg/en/interaktif.py"
2020/3/26: Tambahkan BILSTM+Contoh Perhatian untuk Klasifikasi
2020/3/23: Tambahkan pengoptimal radam.
2020/3/19: Tambahkan contoh tes "albert_ner_train.py" "albert_ner_test.py"
2020/3/16: Tambahkan model untuk pelatihan sub -kata yang disematkan berdasarkan metode BPE. Embedding terlatih digunakan dalam model TextCnn untuk meningkatkan peningkatannya. Lihat "Tran_Bpe_embeding.py" untuk lebih jelasnya.
2020/3/8: Tambahkan contoh tes "run_tucker.py" untuk kereta tucker di wn18.
2020/3/3: Tambahkan contoh uji "tran_text_cnn.py" untuk model TextCnn kereta.
2020/3/2: Tambahkan contoh tes "train_bert_classification.py" untuk klasifikasi teks berdasarkan Bert.
git clone https://github.com/kyzhouhzau/NLPGNN.git
python setup.py install
python bert_ner_train.py
Letakkan kereta kereta api, valid, dan uji di kamus "input".
Format Data: Data Referensi dalam "Tes ner Input Train"
misalnya "拮 抗 rankl 对 破 骨 细 胞 的 作 用 oooo B-anatomi I-anatomi i-anatomi e-anatomi oooo"
Untuk setiap baris di kereta berisi dua bagian, bagian pertama "拮 抗 rankl 对 破 骨 细 胞 的 作 用。" adalah kalimat. Bagian kedua "Oooo B-Anatomi I-Anatomi I-Anatomi E-Anatomi Oooo" adalah tag untuk setiap kata dalam kalimat. Keduanya menggunakan ' t' untuk menggabungkan.
from nlpgnn . models import bert
bert = bert . BERT () python bert_ner_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
=================================================================
Total params: 101,712,430
Trainable params: 101,712,430
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import bert
from nlpgnn . metrics . crf import CrfLogLikelihood
bert = bert . BERT ()
crf = CrfLogLikelihood () python bert_ner_crf_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
_________________________________________________________________
crf (CrfLogLikelihood) multiple 2116
=================================================================
Total params: 101,714,546
Trainable params: 101,714,546
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import albert
bert = albert . ALBERT () python albert_ner_train.py
large
Model: "albert_ner"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
albert (ALBERT) multiple 11092992
_________________________________________________________________
dense (Dense) multiple 6921
=================================================================
Total params: 11,099,913
Trainable params: 11,099,913
Non-trainable params: 0
_________________________________________________________________
Menggunakan parameter default, kami mendapatkan hasil berikut pada "中文糖尿病标注数据集" dan "conll-2003" data yang valid.
| model | makro-f1 | makro-p | makro-r | lr | masa | Maxlen | Batch_Size | data |
|---|---|---|---|---|---|---|---|---|
| Bert+Base | 0.7005 | 0.7244 | 0.7031 | 2e-5 | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| Bert+Base+CRF | 0.7009 | 0.7237 | 0.7041 | 2E-5 (Bert), 2E-3 (CRF) | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| Bert+Base | 0.9128 | 0.9208 | 0.9227 | 2e-5 | 5 | 128 | 8 | Conll-2003 |
| Albert+Base | 0.8512 | 0.8678 | 0.8589 | 1E-4 | 8 | 128 | 16 | Conll-2003 |
| Albert+Besar | 0.8670 | 0.8778 | 0.8731 | 2e-5 | 10 | 128 | 4 | Conll-2003 |
Letakkan kereta kereta api, valid, dan uji di kamus "input".
Format Data: Data referensi dalam " tes cls Bert (atau Albert) input".
misalnya "作 为 地 球 上 曾 经 最 强 的 拳 王 之 , , 小 克 里 琴 科 谈 自 己 是 否 会 出 出 2"
For each line in train(test,valid) contains two parts, the first part "作 为 地 球 上 曾 经 最 强 的 拳 王 之 一 , 小 克 里 琴 科 谈 自 己 是 否 会 复 出" is the sentence, and second part "2" is the label.
from nlpgnn . models import bert
bert = bert . BERT () python train_bert_classification.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 102267648
_________________________________________________________________
dense (Dense) multiple 11535
=================================================================
Total params: 102,279,183
Trainable params: 102,279,183
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import TextCNN
model = TextCNN . TextCNN () python train_text_cnn.py
Use "WordPiece embedding" to Initialize word embedding. Train your embeddings.
python train_bpe_embedding.py
Untuk wordpiece referensi detail lebih lanjut
Menggunakan parameter default, kami mendapatkan hasil berikut pada "新闻标题短文本分类" dan data valid SST-2.
| model | ACC | lr | masa | Maxlen | Batch_Size | data |
|---|---|---|---|---|---|---|
| Bert+Base | 0.8899 | 1E-5 | 5 | 50 | 32 | 新闻标题短文本分类 |
| Bert+Base | 0.9266 | 2e-5 | 3 | 128 | 8 | SST-2 |
| Albert+Base | 0.9186 | 1E-5 | 3 | 128 | 16 | SST-2 |
| Albert+Besar | 0.9461 | 1E-6 | 3 | 128 | 4 | SST-2 |
| Bilstm+Perhatian | 0.8269 | 0,01 | 3 | 128 | 64 | SST-2 |
| Textcnn | 0.8233 | 0,01 | 3 | 128 | 64 | SST-2 |
from nlpgnn . models import gpt2
bert = gpt2 . GPT2 () python interactive.py
Model: "gen_gp_t2" base
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gpt2 (GPT2) multiple 124439808
=================================================================
Total params: 124,439,808
Trainable params: 124,439,808
Non-trainable params: 0
_________________________________________________________________
Contoh:
Input >>> Stocks continue to fall this week
Output >>> as stocks fall for the second consecutive week as investors flee for safe havens.
"The market is off the charts," said John Schmieding, senior vice president, market strategy at RBC Capital Markets.
"We don't know what the Fed's intent is on, what direction it's going in. We don't know where they plan to go.
We don't know what direction they're going to move into."
Tensorboard dapat membantu Anda memvisualisasikan kerugian dan mengevaluasi indikator:
Menggunakan:
tensorboard --port 6006 --logdir="./tensorboard"
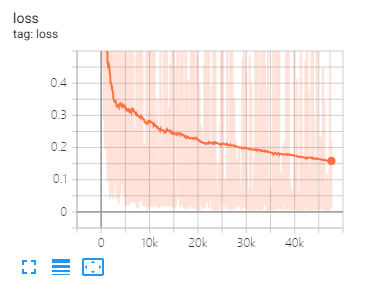
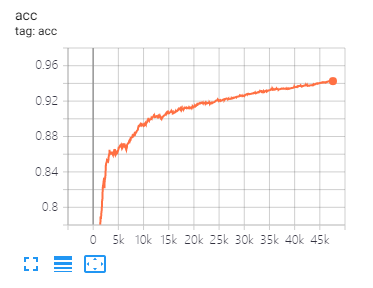
Data split dan parameter yang sama seperti yang diusulkan dalam makalah ini
| model | Cora | PubMed | Citeseer |
|---|---|---|---|
| GCN | 81.80 | 79.50 | 71.20 |
| Gan | 83.00 | 79.00 | 72.30 |
| GAAE | 82.40 | 79.60 | 71.70 |
| model | Mutag | Protein | NCI1 |
|---|---|---|---|
| GIN | 87.62 ± 8.76 # | 73,05 ± 1,85 # | 73.13 ± 5.57 # |
| Grafik | 86.06 ± 8.26 | 75.11 ± 2.87 | 76,91 ± 3,45 |
Catatan: Tanda # menunjukkan bahwa hasil saat ini kurang dari hasil kertas. Dalam makalah, penulis menggunakan metode ini untuk mengevaluasi model. Metode ini mahal waktu. Jadi saya tidak melakukannya seperti itu di sini.
| model | R8 | R52 |
|---|---|---|
| Teks | 96,68 ± 0,42 | 92,80 ± 0,32 |
| TextGCN2019 | 97.108 ± 0,243 | 92.512 ± 0,249 |
1 、 Untuk tugas -tugas bahasa Inggris, Anda perlu mengatur parameter "cased" (di fennlp.datas.checkpoint.loadCheckPoint) agar konsisten dengan data input yang diproses sebelumnya untuk memastikan bahwa tokenizer dapat membedakan kasus dengan benar.
2 、 Saat Anda menggunakan Bert atau Albert, parameter berikut diperlukan:
param.maxlen
param.label_size
param.batch_size
Jika Anda tidak tahu jumlah label_size, skrip akan memberi tahu Anda ketika Anda pertama kali menjalankan kode kereta.
3 、 Tingkat belajar dan Batch_Size akan menentukan konvergensi model, lihat tautan untuk lebih detail.
4 、 Jika Anda tidak terbiasa dengan pengoptimal di Bert dan Albert, itu tidak masalah. Hal terpenting yang perlu Anda ingat adalah bahwa parameter "learning_rate" dan "decay_steps" (di fennlp.optimizers.optim.adamWarmup) penting. Anda dapat mengatur "tingkat pembelajaran" ke nilai yang relatif kecil, dan membiarkan "decay_steps" sama dengan sampel*Epoch/batch_size atau sedikit lebih tinggi.
5 、 Jika Anda menemukan bahwa kode berjalan lebih lambat, Anda dapat mencoba menggunakan @ tf.function dan mengatur frekuensi penulisan dan evaluasi model yang sesuai.
6 、 Masalah lain apa pun yang dapat Anda lakukan dengan "[email protected]" atau mengajukan pertanyaan yang dipermasalahkan.
[1] Bert: Pra-pelatihan transformator dua arah yang dalam untuk pemahaman bahasa
[2] Albert: Lite Bert untuk pembelajaran representasi bahasa sendiri
[3] Model bahasa adalah pelajar multitask tanpa pengawasan
[4] Pesan saraf yang lewat untuk kimia kuantum
[5] Klasifikasi semi-diawasi dengan jaringan konvolusional grafik
[6] Grafik Jaringan Perhatian
[7] Seberapa kuat grafik jaringan saraf?
[8] Grafik: Pembelajaran Representasi Induktif pada Grafik Besar
[9] Difusi meningkatkan pembelajaran grafik
[10] Benchmarking Grafik Jaringan Saraf
[11] Level Teks Grafik Jaringan Saraf untuk Klasifikasi Teks
[12] Grafik Jaringan Konvolusional untuk Klasifikasi Teks
[13] Jaringan konvolusional grafik tensor untuk klasifikasi teks
[14] Wawasan yang lebih dalam tentang jaringan konvolusional grafik untuk pembelajaran semi-diawasi


