NLPGNN
1.0.0
O campo do processamento de linguagem natural está atualmente passando por tremendas mudanças, e muitos modelos excelentes foram propostos nos últimos anos, incluindo Bert, GPT, etc.
Ao mesmo tempo, a rede neural gráfica como um design requintada está sendo constantemente usada no campo do processamento de linguagem natural, como textGCN e tensor-textGCN.
Esta caixa de ferramentas é dedicada ao processamento de linguagem natural e espera implementar modelos da maneira mais simples.
Palavras -chave: NLP; Gnn
Modelos:
Exemplos (consulte os testes para obter mais detalhes):
Todas as experiências acima foram testadas na GPU GTX 1080 com memória 8000mib.
2020/5/-: Converta o nome do projeto em NLPGNN de Fennlp.
2020/5/17: tente converter a frase em gráfico com base na matriz de atenção de Bert, mas falhou. Esta seção fornece uma solução para visualizar a matriz de atenção Bert. Para mais detalhes, você pode verificar o dicionário "Bert-GCN".
2020/5/11: Adicione TextGCN e Textsage para classificação de texto.
2020/5/5: adicione gin, gráfico para classificação de gráfico.
2020/4/25: Adicione o modelo GAN, Gin, com base nos métodos de passagem de mensagens.
2020/4/23: Adicione o modelo GCN, com base nos métodos de passagem de mensagens.
2020/4/16: Atualmente, focado nos modelos de GNN no PNL e tentando integrar alguns modelos GNN na FennLP.
2020/4/2: Adicionar modelo GPT2, poderia usar parâmetros lançados pelo OpenAI (base, médio, grande). Mais detalhes de referência detalhados "TG/EN/Interactive.py"
2020/3/26: Adicione BILSTM+Exemplo de atenção para classificação
2020/3/23: Adicione o otimizador Radam.
2020/3/19: Adicionar exemplo de teste "Albert_ner_train.py" "Albert_ner_test.py"
2020/3/16: Adicione o modelo para o treinamento de sub -incorporação de Sub Word com base nos métodos BPE. A incorporação treinada é usada no modelo TextCNN para melhorar sua melhoria. Consulte "TRAN_BPE_EMBEDING.PY" para mais detalhes.
2020/3/8: Adicione Exemplo de teste "run_tucker.py" para o trem Tucker no WN18.
2020/3/3: Adicione Exemplo de teste "TRAN_TEXT_CNN.PY" para o modelo de texto do Trem TextCNN.
2020/3/2: Adicione Exemplo de teste "Train_Bert_Classification.Py" para classificação de texto com base no BERT.
git clone https://github.com/kyzhouhzau/NLPGNN.git
python setup.py install
python bert_ner_train.py
Coloque o trem, válido e o arquivo de teste no dicionário de "entrada".
Formato de dados: dados de referência em "Testes ner input Train"
por exemplo, "拮 抗 抗 rankl 对 骨 骨 细 胞 的 作 用。 oooo b-anatomy i-anatomy i-anatomy e-anatomy oooo"
Para cada linha no trem contém duas partes, a primeira parte "拮 抗 抗 抗 对 破 骨 细 胞 的 作 作。。" é uma frase. A segunda parte "oooo b-anatomy i-anatomy i-anatomy e-anatomy ooooo" é a etiqueta para cada palavra na frase. Ambos usam ' t' para concatenar.
from nlpgnn . models import bert
bert = bert . BERT () python bert_ner_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
=================================================================
Total params: 101,712,430
Trainable params: 101,712,430
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import bert
from nlpgnn . metrics . crf import CrfLogLikelihood
bert = bert . BERT ()
crf = CrfLogLikelihood () python bert_ner_crf_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
_________________________________________________________________
crf (CrfLogLikelihood) multiple 2116
=================================================================
Total params: 101,714,546
Trainable params: 101,714,546
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import albert
bert = albert . ALBERT () python albert_ner_train.py
large
Model: "albert_ner"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
albert (ALBERT) multiple 11092992
_________________________________________________________________
dense (Dense) multiple 6921
=================================================================
Total params: 11,099,913
Trainable params: 11,099,913
Non-trainable params: 0
_________________________________________________________________
Usando os parâmetros padrão, obtemos os seguintes resultados em dados válidos "中文糖尿病标注数据集 中文糖尿病标注数据集" e "Conll-2003".
| modelo | macro-f1 | macro-p | macro-r | lr | época | Maxlen | batch_size | dados |
|---|---|---|---|---|---|---|---|---|
| BERT+base | 0,7005 | 0,7244 | 0,7031 | 2E-5 | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| BERT+Base+CRF | 0.7009 | 0,7237 | 0,7041 | 2E-5 (Bert), 2E-3 (CRF) | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| BERT+base | 0,9128 | 0,9208 | 0,9227 | 2E-5 | 5 | 128 | 8 | CONLL-2003 |
| Albert+base | 0,8512 | 0,8678 | 0,8589 | 1e-4 | 8 | 128 | 16 | CONLL-2003 |
| Albert+grande | 0,8670 | 0,8778 | 0,8731 | 2E-5 | 10 | 128 | 4 | CONLL-2003 |
Coloque o trem, válido e o arquivo de teste no dicionário de "entrada".
Formato de dados: dados de referência em " tests cls bert (ou albert) entrada".
por exemplo, "作 为 地 上 曾 经 最 强 的 拳 王 之 , , 小 里 里 琴 科 谈 自 己 是 否 复 出 2"
Para cada linha no trem (teste, válido) contém duas partes, a primeira parte "作 地 球 上 曾 经 最 强 的 拳 王 之 , , 小 里 里 琴 科 谈 谈 己 是 否 否 复 复" é a sentença e a segunda parte "2" é a etiqueta.
from nlpgnn . models import bert
bert = bert . BERT () python train_bert_classification.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 102267648
_________________________________________________________________
dense (Dense) multiple 11535
=================================================================
Total params: 102,279,183
Trainable params: 102,279,183
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import TextCNN
model = TextCNN . TextCNN () python train_text_cnn.py
Use "WordPiece embedding" to Initialize word embedding. Train your embeddings.
python train_bpe_embedding.py
Para mais detalhes, peça de palavra de referência
Usando os parâmetros padrão, obtemos os seguintes resultados em dados válidos "新闻标题短文本分类" e SST-2.
| modelo | Acc | lr | época | Maxlen | batch_size | dados |
|---|---|---|---|---|---|---|
| BERT+base | 0,8899 | 1e-5 | 5 | 50 | 32 | 新闻标题短文本分类 |
| BERT+base | 0,9266 | 2E-5 | 3 | 128 | 8 | SST-2 |
| Albert+base | 0,9186 | 1e-5 | 3 | 128 | 16 | SST-2 |
| Albert+grande | 0,9461 | 1e-6 | 3 | 128 | 4 | SST-2 |
| Bilstm+atenção | 0,8269 | 0,01 | 3 | 128 | 64 | SST-2 |
| Textcnn | 0,8233 | 0,01 | 3 | 128 | 64 | SST-2 |
from nlpgnn . models import gpt2
bert = gpt2 . GPT2 () python interactive.py
Model: "gen_gp_t2" base
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gpt2 (GPT2) multiple 124439808
=================================================================
Total params: 124,439,808
Trainable params: 124,439,808
Non-trainable params: 0
_________________________________________________________________
Exemplo:
Input >>> Stocks continue to fall this week
Output >>> as stocks fall for the second consecutive week as investors flee for safe havens.
"The market is off the charts," said John Schmieding, senior vice president, market strategy at RBC Capital Markets.
"We don't know what the Fed's intent is on, what direction it's going in. We don't know where they plan to go.
We don't know what direction they're going to move into."
O Tensorboard pode ajudá -lo a visualizar perdas e avaliar indicadores:
USEAGE:
tensorboard --port 6006 --logdir="./tensorboard"
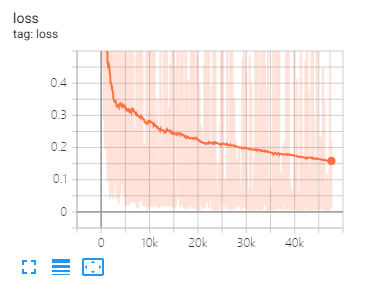
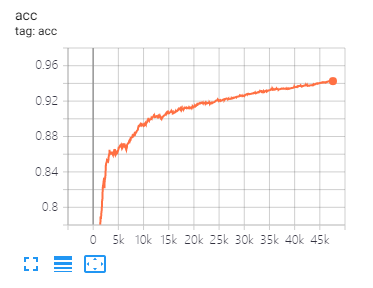
As mesmas divisões de dados e parâmetros de configuração, conforme proposto neste artigo
| modelo | Cora | PubMed | Citeseer |
|---|---|---|---|
| Gcn | 81,80 | 79.50 | 71.20 |
| Gan | 83,00 | 79,00 | 72.30 |
| Gaae | 82.40 | 79.60 | 71.70 |
| modelo | Mutag | Proteínas | Nci1 |
|---|---|---|---|
| GIN | 87,62 ± 8,76 # | 73,05 ± 1,85 # | 73,13 ± 5,57 # |
| GraphSage | 86,06 ± 8,26 | 75.11 ± 2,87 | 76,91 ± 3,45 |
Nota: O sinal # indica que o resultado atual é menor que o resultado do papel. No artigo, o autor usa esse método para avaliar modelos. Este método é tempo caro. Então, eu não fiz assim aqui.
| modelo | R8 | R52 |
|---|---|---|
| Textos | 96,68 ± 0,42 | 92,80 ± 0,32 |
| TextGCN2019 | 97.108 ± 0,243 | 92.512 ± 0,249 |
1 、 Para tarefas em inglês, você precisa definir o parâmetro "CASED" (em fennlp.datas.checkpoint.loadcheckpoint) como consistente com seus dados de entrada pré -processados para garantir que o tokenizador possa distinguir corretamente o caso.
2 、 Quando você usa Bert ou Albert, os seguintes parâmetros são necessários:
param.maxlen
param.label_size
param.batch_size
Se você não conhece a contagem de LABEL_SIZE, o script informará quando você executar os códigos de trem pela primeira vez.
3 、 Taxa de aprendizado e Batch_size determinarão a convergência do modelo, consulte o link para obter mais detalhes.
4 、 Se você não estiver familiarizado com o otimizador em Bert e Albert, isso não importa. A coisa mais importante que você precisa lembrar é que os parâmetros "Learning_rate" e "Decay_Steps" (em Fennlp.optimizers.optim.adamwarmup) é importante. Você pode definir a "taxa de aprendizado" como um valor relativamente pequeno e deixar "decay_steps" igual a amostras*epoch/batch_size ou um pouco mais alto.
5 、 Se você achar que o código é mais lento, tente usar @ tf.function e definir a frequência apropriada de escrita e avaliação do modelo.
6 、 Qualquer outro problema que você possa me concatar por "[email protected]" ou fazer perguntas em questão.
[1] Bert: pré-treinamento de transformadores bidirecionais profundos para entendimento de idiomas
[2] Albert: Um Lite Bert para aprender auto-supervisionado sobre representações de idiomas
[3] Modelos de idiomas são aprendizes multitarefa sem supervisão
[4] Mensagem neural Passando para química quântica
[5] Classificação semi-supervisionada com redes convolucionais de gráfico
[6] Redes de atenção do gráfico
[7] Quão poderosas são redes neurais gráficas?
[8] GraphSage: Aprendizagem de representação indutiva em gráficos grandes
[9] A difusão melhora o aprendizado de gráficos
[10] Redes neurais de gráfico de benchmarking
[11] Rede neural do gráfico no nível de texto para classificação de texto
[12] Redes convolucionais de gráfico para classificação de texto
[13] Redes convolucionais de gráfico de tensores para classificação de texto
[14] idéias mais profundas sobre redes convolucionais de gráficos para aprendizado semi-supervisionado


