NLPGNN
1.0.0
يمر مجال معالجة اللغة الطبيعية حاليًا بتغييرات هائلة ، وقد تم اقتراح العديد من النماذج الممتازة في السنوات الأخيرة ، بما في ذلك BERT ، GPT ، إلخ.
في الوقت نفسه ، يتم استخدام الشبكة العصبية الرسم البياني كتصميم رائع باستمرار في مجال معالجة اللغة الطبيعية ، مثل TextGCN و Tensor-TextGCN.
تم تخصيص صندوق الأدوات هذا لمعالجة اللغة الطبيعية ويتوقع تنفيذ النماذج بأبسط طريقة.
الكلمات الرئيسية: NLP ؛ GNN
النماذج:
أمثلة (انظر الاختبارات لمزيد من التفاصيل):
تم اختبار جميع التجارب المذكورة أعلاه على GPU GTX 1080 مع الذاكرة 8000MIB.
2020/5/-: تحويل اسم المشروع إلى NLPGNN من Fennlp.
2020/5/17: حاول تحويل الجملة إلى الرسم البياني بناءً على مصفوفة بيرت ، لكنها فشلت. يوفر هذا القسم حلاً لتصور مصفوفة بيرت. لمزيد من التفاصيل ، يمكنك التحقق من القاموس "Bert-GCN".
2020/5/11: أضف TextGcn و Textsage لتصنيف النص.
2020/5/5: إضافة الجن ، GraphSage لصفوف الرسم البياني.
2020/4/25: إضافة GAN ، نموذج الجن ، بناءً على طرق تمرير الرسائل.
2020/4/23: أضف نموذج GCN ، بناءً على طرق تمرير الرسائل.
2020/4/16 : يركز حاليًا على نماذج GNN في NLP ، ومحاولة دمج بعض نماذج GNN في FENNLP.
2020/4/2: إضافة نموذج GPT2 ، يمكن استخدام المعلمات التي صدرها Openai (قاعدة ، متوسطة ، كبيرة). المزيد من القاموس المرجعي التفاصيل "TG/EN/Interactive.py"
2020/3/26: إضافة مثال على الانتباه BILSTM+للتصنيف
2020/3/23: أضف مُحسِّن Radam.
2020/3/19: أضف مثال اختبار "Albert_ner_train.py" "Albert_ner_test.py"
2020/3/16: إضافة نموذج لتدريب الكلمات الفرعية على أساس أساليب BPE. يتم استخدام التضمين المدربين في نموذج TextCnn لتحسين تحسينه. انظر "tran_bpe_embeding.py" لمزيد من التفاصيل.
2020/3/8: أضف مثال اختبار "run_tucker.py" للقطار Tucker على WN18.
2020/3/3: أضف مثال اختبار "tran_text_cnn.py" لنموذج TRAIN TEXTCNN.
2020/3/2: أضف مثال اختبار "Train_bert_classification.py" لتصنيف النص على أساس BERT.
git clone https://github.com/kyzhouhzau/NLPGNN.git
python setup.py install
python bert_ner_train.py
ضع القطار ، صالح واختبار الملف في قاموس "إدخال".
تنسيق البيانات: بيانات مرجعية في "الاختبارات ner input Train"
على سبيل المثال ، 拮 抗 RANKL 对 破 骨 细 胞 作 用。。 oooo b-anatomy i-anatomy i-anatomy anatomy ooooo "
يحتوي كل سطر في القطار على جزأين ، الجزء الأول "拮 抗 RANKL 对 破 骨 胞 胞 的 用。" هو جملة. الجزء الثاني "Oooo b-anatomy i-anatomy i-anatomy e-anatomy ooooo" هو علامة لكل كلمة في الجملة. كلاهما يستخدم " t" للتسلسل.
from nlpgnn . models import bert
bert = bert . BERT () python bert_ner_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
=================================================================
Total params: 101,712,430
Trainable params: 101,712,430
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import bert
from nlpgnn . metrics . crf import CrfLogLikelihood
bert = bert . BERT ()
crf = CrfLogLikelihood () python bert_ner_crf_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
_________________________________________________________________
crf (CrfLogLikelihood) multiple 2116
=================================================================
Total params: 101,714,546
Trainable params: 101,714,546
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import albert
bert = albert . ALBERT () python albert_ner_train.py
large
Model: "albert_ner"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
albert (ALBERT) multiple 11092992
_________________________________________________________________
dense (Dense) multiple 6921
=================================================================
Total params: 11,099,913
Trainable params: 11,099,913
Non-trainable params: 0
_________________________________________________________________
باستخدام المعلمات الافتراضية ، نحصل على النتائج التالية على بيانات "中文糖尿病标注数据集" و "Conll-2003" صالحة.
| نموذج | ماكرو-F1 | الماكرو | ماكرو آر | LR | عصر | ماكلين | batch_size | بيانات |
|---|---|---|---|---|---|---|---|---|
| BERT+قاعدة | 0.7005 | 0.7244 | 0.7031 | 2E-5 | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| BERT+BASE+CRF | 0.7009 | 0.7237 | 0.7041 | 2E-5 (BERT) ، 2E-3 (CRF) | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| BERT+قاعدة | 0.9128 | 0.9208 | 0.9227 | 2E-5 | 5 | 128 | 8 | Conll-2003 |
| ألبرت+قاعدة | 0.8512 | 0.8678 | 0.8589 | 1E-4 | 8 | 128 | 16 | Conll-2003 |
| ألبرت+كبير | 0.8670 | 0.8778 | 0.8731 | 2E-5 | 10 | 128 | 4 | Conll-2003 |
ضع القطار ، صالح واختبار الملف في قاموس "إدخال".
تنسيق البيانات: بيانات مرجعية في " Tests Cls Bert (أو Albert) Input".
مثل "作 为 地 球 上 经 最 最 的 拳 王 王 之 , 小 小 克 科 科 谈 己 是 否 会 出 出 2"
لكل سطر في القطار (اختبار ، صالح) يحتوي على جزأين ، الجزء الأول "作 为 球 上 曾 最 强 强 拳 王 之 之 , , 小 克 里 琴 科 谈 自 自 己 是 否 会 会 一 , , 小 小 里 琴 琴 科 谈 自 自 是 否 复 复" ، والجزء الثاني "2" هو العلامة.
from nlpgnn . models import bert
bert = bert . BERT () python train_bert_classification.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 102267648
_________________________________________________________________
dense (Dense) multiple 11535
=================================================================
Total params: 102,279,183
Trainable params: 102,279,183
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import TextCNN
model = TextCNN . TextCNN () python train_text_cnn.py
Use "WordPiece embedding" to Initialize word embedding. Train your embeddings.
python train_bpe_embedding.py
لمزيد من التفاصيل المرجعية وورد
باستخدام المعلمات الافتراضية ، نحصل على النتائج التالية على البيانات "新闻标题短文本分类" و SST-2 صالحة.
| نموذج | ACC | LR | عصر | ماكلين | batch_size | بيانات |
|---|---|---|---|---|---|---|
| BERT+قاعدة | 0.8899 | 1E-5 | 5 | 50 | 32 | 新闻标题短文本分类 |
| BERT+قاعدة | 0.9266 | 2E-5 | 3 | 128 | 8 | SST-2 |
| ألبرت+قاعدة | 0.9186 | 1E-5 | 3 | 128 | 16 | SST-2 |
| ألبرت+كبير | 0.9461 | 1E-6 | 3 | 128 | 4 | SST-2 |
| BILSTM+الانتباه | 0.8269 | 0.01 | 3 | 128 | 64 | SST-2 |
| TextCnn | 0.8233 | 0.01 | 3 | 128 | 64 | SST-2 |
from nlpgnn . models import gpt2
bert = gpt2 . GPT2 () python interactive.py
Model: "gen_gp_t2" base
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gpt2 (GPT2) multiple 124439808
=================================================================
Total params: 124,439,808
Trainable params: 124,439,808
Non-trainable params: 0
_________________________________________________________________
مثال:
Input >>> Stocks continue to fall this week
Output >>> as stocks fall for the second consecutive week as investors flee for safe havens.
"The market is off the charts," said John Schmieding, senior vice president, market strategy at RBC Capital Markets.
"We don't know what the Fed's intent is on, what direction it's going in. We don't know where they plan to go.
We don't know what direction they're going to move into."
يمكن أن تساعدك Tensorboard في تصور الخسائر وتقييم المؤشرات:
useage:
tensorboard --port 6006 --logdir="./tensorboard"
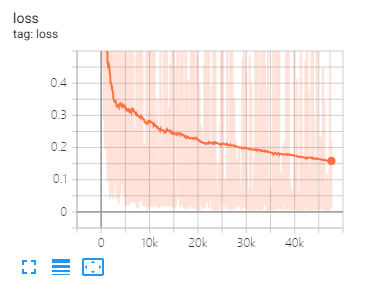
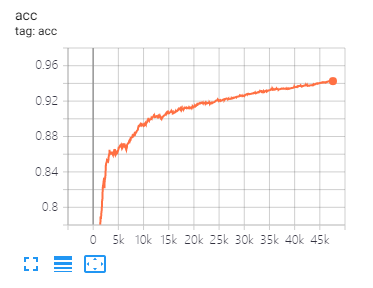
تقسيم البيانات والمعلمات نفسها كما هو مقترح في هذه الورقة
| نموذج | كورا | PubMed | سيتير |
|---|---|---|---|
| GCN | 81.80 | 79.50 | 71.20 |
| جان | 83.00 | 79.00 | 72.30 |
| Gaae | 82.40 | 79.60 | 71.70 |
| نموذج | موتاج | البروتينات | NCI1 |
|---|---|---|---|
| شرك | 87.62 ± 8.76 # | 73.05 ± 1.85 # | 73.13 ± 5.57 # |
| رسم بياني | 86.06 ± 8.26 | 75.11 ± 2.87 | 76.91 ± 3.45 |
ملاحظة: تشير علامة # إلى أن النتيجة الحالية أقل من النتيجة الورقية. في الورقة ، يستخدم المؤلف هذه الطريقة لتقييم النماذج. هذه الطريقة باهظة الثمن. لذلك لم أفعل ذلك هكذا هنا.
| نموذج | R8 | R52 |
|---|---|---|
| Textsage | 96.68 ± 0.42 | 92.80 ± 0.32 |
| TextGCN2019 | 97.108 ± 0.243 | 92.512 ± 0.249 |
1 、 بالنسبة للمهام الإنجليزية ، تحتاج إلى تعيين المعلمة "غلاف" (في fennlp.datas.checkpoint.loadCheckPoint) لتكون متسقة مع بيانات الإدخال المعالجة مسبقًا للتأكد من أن المميز يمكنه التمييز بشكل صحيح عن الحالة.
2 、 عند استخدام Bert أو Albert ، تكون المعلمات التالية ضرورية:
param.maxlen
param.label_size
param.batch_size
إذا كنت لا تعرف عدد label_size ، فسيخبرك البرنامج النصي عند تشغيل رموز القطار لأول مرة.
3 、 معدل التعلم و Batch_size سيحددان تقارب النموذج ، راجع الرابط لمزيد من التفاصيل.
4 、 إذا لم تكن على دراية بالمحسّنة في بيرت وألبرت ، فلا يهم. أهم شيء تحتاج إلى تذكره هو أن المعلمات "Learning_Rate" و "Decay_Steps" (في fennlp.optimizers.optim.adamwarmup) مهمة. يمكنك تعيين "معدل التعلم" على قيمة صغيرة نسبيًا ، والسماح "DECAY_STEPS" بمساواة للعينات*Epoch/Batch_size أو أعلى قليلاً.
5 、 إذا وجدت أن الكود يعمل أبطأ ، فيمكنك محاولة استخدام @ tf.function وتعيين تردد الكتابة والتقييم المناسب.
6 、 أي مشكلة أخرى يمكنك أن تسلسني من خلال "[email protected]" أو طرح الأسئلة المعروضة.
[1] بيرت: ما قبل التدريب من محولات ثنائية الاتجاه العميقة لفهم اللغة
[2] ألبرت: بيرت لايت للتعلم الخاضع للإشراف ذاتيا
[3] نماذج اللغة متعلمين غير خاضعين للإشراف على المهام المتعددة
[4] رسالة عصبية تمرير كيمياء الكم
[5] تصنيف شبه خاضع للإشراف مع شبكات تلافيفية الرسم البياني
[6] شبكات انتباه الرسم البياني
[7] ما مدى قوة الشبكات العصبية الرسم البياني؟
[8] Graphsage: تمثيل استقرائي تعلم على الرسوم البيانية الكبيرة
[9] الانتشار يحسن تعلم الرسم البياني
[10] قياس الرسم البياني الشبكات العصبية
[11] الشبكة العصبية الرسم البياني على مستوى النص لتصنيف النص
[12] الرسم البياني الشبكات التلافيفية لتصنيف النص
[13] توتر الرسم البياني الشبكات التلافيفية لتصنيف النص
[14] رؤى أعمق في الشبكات التلافيفية الرسم البياني للتعلم شبه الخاضع للإشراف


