NLPGNN
1.0.0
El campo del procesamiento del lenguaje natural está actualmente en tremendos cambios, y se han propuesto muchos modelos excelentes en los últimos años, incluidos Bert, GPT, etc.
Al mismo tiempo, la red neuronal Graph como un diseño exquisito se usa constantemente en el campo del procesamiento del lenguaje natural, como TextGCN y Tensor-Textgcn.
Esta caja de herramientas está dedicada al procesamiento del lenguaje natural y espera implementar modelos de la manera más simple.
Palabras clave: NLP; GNN
Modelos:
Ejemplos (ver pruebas para obtener más detalles):
Todos los experimentos anteriores se probaron en GTX 1080 GPU con memoria 8000MIB.
2020/5/-: Convierta el nombre del proyecto en NLPGNN desde Fennlp.
2020/5/17: Intente convertir la oración al gráfico basado en la matriz de atención de Bert, pero falló. Esta sección proporciona una solución para visualizar la matriz de atención Bert. Para obtener más detalles, puede verificar el diccionario "Bert-GCN".
2020/5/11: agregue TextGCN y TextSage para la clasificación de texto.
2020/5/5: Agregar gin, gráfico para la clases de gráficos.
2020/4/25: Agregar GaN, modelo GIN, basado en métodos de paso de mensajes.
2020/4/23: Agregue el modelo GCN, basado en métodos de paso de mensajes.
2020/4/16: Actualmente centrándose en modelos de GNN en PNL e intentando integrar algunos modelos GNN en FennLP.
2020/4/2: Agregar modelo GPT2, podría utilizar parámetros liberados por OpenAI (base, medio, grande). Diccionario de referencia más detalle "TG/EN/Interactive.py"
2020/3/26: Agregar BilstM+Ejemplo de atención para la clasificación
2020/3/23: Agregue el optimizador Radam.
2020/3/19: Agregar ejemplo de prueba "Albert_ner_train.py" "Albert_ner_test.py"
2020/3/16: Agregue el modelo para la incrustación de la subconma de entrenamiento basada en métodos BPE. La incrustación entrenada se usa en el modelo TextCNN para mejorar su mejora. Consulte "tran_bpe_embeding.py" para obtener más detalles.
2020/3/8: Agregar ejemplo de prueba "run_tucker.py" para Train Tucker en WN18.
2020/3/3: Agregar ejemplo de prueba "Tran_text_cnn.py" para el modelo de textcnn de tren.
2020/3/2: Agregar ejemplo de prueba "Train_bert_classification.py" para la clasificación de texto basada en Bert.
git clone https://github.com/kyzhouhzau/NLPGNN.git
python setup.py install
python bert_ner_train.py
Ponga el tren, válido y de prueba en el diccionario "Entrada".
Formato de datos: datos de referencia en "Pruebas ner input Train"
por ejemplo, "拮 抗 rankl 对 破 骨 细 胞 的 作 用。 oooo b-anatomy i-anatomy i-anatomy e-anatomy oooo"
Para cada línea en el tren contiene dos partes, la primera parte "拮 抗 rankl 对 破 骨 细 胞 的 作 用。" es una oración. La segunda parte "oooo b-anatomy i-anatomy i-anatomy e-anatomy oooo" es la etiqueta para cada palabra en la oración. Ambos usan ' t' para concatenar.
from nlpgnn . models import bert
bert = bert . BERT () python bert_ner_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
=================================================================
Total params: 101,712,430
Trainable params: 101,712,430
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import bert
from nlpgnn . metrics . crf import CrfLogLikelihood
bert = bert . BERT ()
crf = CrfLogLikelihood () python bert_ner_crf_train.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 101677056
_________________________________________________________________
dense (Dense) multiple 35374
_________________________________________________________________
crf (CrfLogLikelihood) multiple 2116
=================================================================
Total params: 101,714,546
Trainable params: 101,714,546
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import albert
bert = albert . ALBERT () python albert_ner_train.py
large
Model: "albert_ner"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
albert (ALBERT) multiple 11092992
_________________________________________________________________
dense (Dense) multiple 6921
=================================================================
Total params: 11,099,913
Trainable params: 11,099,913
Non-trainable params: 0
_________________________________________________________________
Usando los parámetros predeterminados, obtenemos los siguientes resultados en los datos válidos "中文糖尿病标注数据集" y "Conll-2003".
| modelo | macro-F1 | macro-P | macro-R | LR | época | maxlen | lote_size | datos |
|---|---|---|---|---|---|---|---|---|
| Bert+base | 0.7005 | 0.7244 | 0.7031 | 2E-5 | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| Bert+Base+CRF | 0.7009 | 0.7237 | 0.7041 | 2e-5 (Bert), 2e-3 (CRF) | 3 | 128 | 6 | 中文糖尿病标注数据集 |
| Bert+base | 0.9128 | 0.9208 | 0.9227 | 2E-5 | 5 | 128 | 8 | Conll-2003 |
| Albert+base | 0.8512 | 0.8678 | 0.8589 | 1e-4 | 8 | 128 | 16 | Conll-2003 |
| Albert+grande | 0.8670 | 0.8778 | 0.8731 | 2E-5 | 10 | 128 | 4 | Conll-2003 |
Ponga el tren, válido y de prueba en el diccionario "Entrada".
Formato de datos: datos de referencia en " tests cls bert (o albert) input".
por ejemplo, "作 为 地 球 上 曾 经 最 强 的 拳 王 之 一 , 小 克 里 琴 科 谈 自 己 是 否 会 复 出 2"
Para cada línea en tren (prueba, válida) contiene dos partes, la primera parte "作 为 地 球 上 曾 经 最 强 的 拳 王 之 一 一 , 克 里 琴 科 谈 自 己 是 否 会 复 出 出" es la oración, y la segunda parte "2" es la etiqueta.
from nlpgnn . models import bert
bert = bert . BERT () python train_bert_classification.py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert (BERT) multiple 102267648
_________________________________________________________________
dense (Dense) multiple 11535
=================================================================
Total params: 102,279,183
Trainable params: 102,279,183
Non-trainable params: 0
_________________________________________________________________
from nlpgnn . models import TextCNN
model = TextCNN . TextCNN () python train_text_cnn.py
Use "WordPiece embedding" to Initialize word embedding. Train your embeddings.
python train_bpe_embedding.py
Para más detalles de la palabra de referencia
Usando los parámetros predeterminados, obtenemos los siguientes resultados en los datos válidos "新闻标题短文本分类" y SST-2.
| modelo | Accidentista | LR | época | maxlen | lote_size | datos |
|---|---|---|---|---|---|---|
| Bert+base | 0.8899 | 1e-5 | 5 | 50 | 32 | 新闻标题短文本分类 |
| Bert+base | 0.9266 | 2E-5 | 3 | 128 | 8 | SST-2 |
| Albert+base | 0.9186 | 1e-5 | 3 | 128 | 16 | SST-2 |
| Albert+grande | 0.9461 | 1e-6 | 3 | 128 | 4 | SST-2 |
| Bilstm+atención | 0.8269 | 0.01 | 3 | 128 | 64 | SST-2 |
| Textcnn | 0.8233 | 0.01 | 3 | 128 | 64 | SST-2 |
from nlpgnn . models import gpt2
bert = gpt2 . GPT2 () python interactive.py
Model: "gen_gp_t2" base
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gpt2 (GPT2) multiple 124439808
=================================================================
Total params: 124,439,808
Trainable params: 124,439,808
Non-trainable params: 0
_________________________________________________________________
Ejemplo:
Input >>> Stocks continue to fall this week
Output >>> as stocks fall for the second consecutive week as investors flee for safe havens.
"The market is off the charts," said John Schmieding, senior vice president, market strategy at RBC Capital Markets.
"We don't know what the Fed's intent is on, what direction it's going in. We don't know where they plan to go.
We don't know what direction they're going to move into."
Tensorboard puede ayudarlo a visualizar las pérdidas y evaluar los indicadores:
usa:
tensorboard --port 6006 --logdir="./tensorboard"
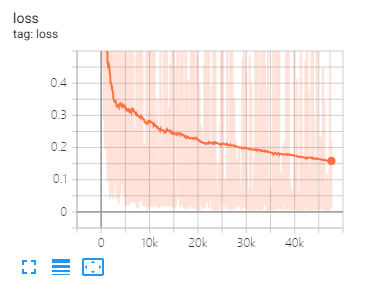
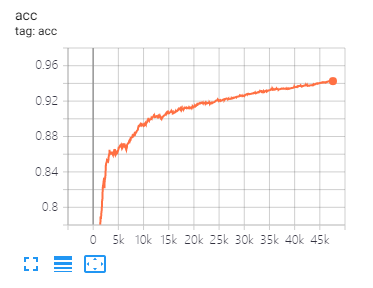
La misma división de datos y configuración de parámetros que se propuso en este documento
| modelo | Cora | Pubmed | Céspero |
|---|---|---|---|
| GCN | 81.80 | 79.50 | 71.20 |
| Ganancia | 83.00 | 79.00 | 72.30 |
| Gaae | 82.40 | 79.60 | 71.70 |
| modelo | Muesca | Proteínas | NCI1 |
|---|---|---|---|
| GINEBRA | 87.62 ± 8.76 # | 73.05 ± 1.85 # | 73.13 ± 5.57 # |
| Gráfico | 86.06 ± 8.26 | 75.11 ± 2.87 | 76.91 ± 3.45 |
Nota: El signo # indica que el resultado actual es menor que el resultado del papel. En el documento, el autor usa este método para evaluar modelos. Este método es costoso. Así que no lo hice así aquí.
| modelo | R8 | R52 |
|---|---|---|
| Paisaje de texto | 96.68 ± 0.42 | 92.80 ± 0.32 |
| TextGCN2019 | 97.108 ± 0.243 | 92.512 ± 0.249 |
1 、 Para tareas en inglés, debe establecer el parámetro "Casado" (en fennlp.datas.eckpoint.loadcheckpoint) para ser consistente con sus datos de entrada preprocesados para garantizar que el tokenizer pueda distinguir correctamente el caso.
2 、 Cuando usa Bert o Albert, los siguientes parámetros son necesarios:
param.maxlen
param.label_size
param.batch_size
Si no conoce el recuento de Label_Size, el script le dirá cuándo ejecuta los códigos de tren por primera vez.
3 、 La tasa de aprendizaje y el lote determinarán la convergencia del modelo, consulte el enlace para obtener más detalles.
4 、 Si no está familiarizado con el optimizador en Bert y Albert, no importa. Lo más importante que debe recordar es que los parámetros "Learning_Rate" y "Decay_steps" (en fennlp.optimizers.optim.adamwarmup) es importante. Puede establecer la "tasa de aprendizaje" en un valor relativamente pequeño, y dejar que "Decay_steps" sea igual a las muestras*Epoch/Batch_Size o poco más.
5 、 Si encuentra que el código se ejecuta más lento, puede intentar usar @ tf.function y establecer la frecuencia de escritura y evaluación de modelo apropiada.
6 、 Cualquier otro problema que pueda concatirme por "[email protected]" o hacer preguntas en cuestión.
[1] Bert: pretruamiento de transformadores bidireccionales profundos para la comprensión del lenguaje
[2] Albert: A Lite Bert para el aprendizaje auto-supervisado de representaciones lingüísticas
[3] Los modelos de idiomas son alumnos de varios tareas no supervisados
[4] Paso de mensajes neuronales para la química cuántica
[5] Clasificación semi-supervisada con redes convolucionales gráficas
[6] Redes de atención de gráficos
[7] ¿Qué tan potentes son las redes neuronales gráficas?
[8] Graphsage: aprendizaje de representación inductiva en gráficos grandes
[9] La difusión mejora el aprendizaje de gráficos
[10] Benchmarking Graph Networks Neural
[11] Nivel de texto Graph Red neuronal para la clasificación de texto
[12] Redes convolucionales gráficas para la clasificación de texto
[13] Redes convolucionales de Tensor Graph para la clasificación de texto
[14] Información más profunda sobre las redes convolucionales gráficas para el aprendizaje semi-supervisado


