VnCoreNLP
v1.2
VNCORENLP是越南人的快速准确的NLP注释管道,通过单词分割的关键NLP组件, POS标记,命名实体识别(NER)和依赖性解析提供丰富的语言注释。用户不必安装外部依赖项。用户可以从命令行或API运行处理管道。 VNCorenlp的一般体系结构和实验结果可以在以下相关论文中找到:
请引用纸张[1],每当使用VNCORENLP产生已发布的结果或并入其他软件时。如果您深入处理单词分割或pos标记,也建议您分别引用纸张[2]或[3]。
如果您正在寻找轻型版本,则VNCORENLP的单词分割和POS标记组件也已作为独立包装rdrsementer [2]和vnmarmot [3]释放。
Java 1.8+ (先决条件)
文件VnCoreNLP-1.2.jar (27MB)和文件夹models (115MB)放置在同一工作文件夹中。
Python 3.6+如果使用Vncorenlp的Python包装器。要安装此包装器,用户必须运行以下命令:
$ pip3 install py_vncorenlp
特别感谢Nguyen的Linh创建了这个包装纸!
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local working folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP from the local working folder that contains both `VnCoreNLP-1.2.jar` and `models`
model = py_vncorenlp . VnCoreNLP ( save_dir = '/absolute/path/to/vncorenlp' )
# Equivalent to: model = py_vncorenlp.VnCoreNLP(annotators=["wseg", "pos", "ner", "parse"], save_dir='/absolute/path/to/vncorenlp')
# Annotate a raw corpus
model . annotate_file ( input_file = "/absolute/path/to/input/file" , output_file = "/absolute/path/to/output/file" )
# Annotate a raw text
model . print_out ( model . annotate_text ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))默认情况下,输出的格式为6列,代表单词索引,单词形式,pos tag,ner标签,当前单词的头部索引及其依赖关系类型:
1 Ông Nc O 4 sub
2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
3 đang R O 4 adv
4 làm_việc V O 0 root
5 tại E O 4 loc
6 Đại_học N B-ORG 5 pob
...
对于仅使用vncorenlp进行单词分割的用户:
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
text = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây."
output = rdrsegmenter . word_segment ( text )
print ( output )
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .'] 您可以使用以下命令来注释输入原始文本语料库(例如新闻内容的集合):
// To perform word segmentation, POS tagging, NER and then dependency parsing
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt
// To perform word segmentation, POS tagging and then NER
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos,ner
// To perform word segmentation and then POS tagging
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos
// To perform word segmentation
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg
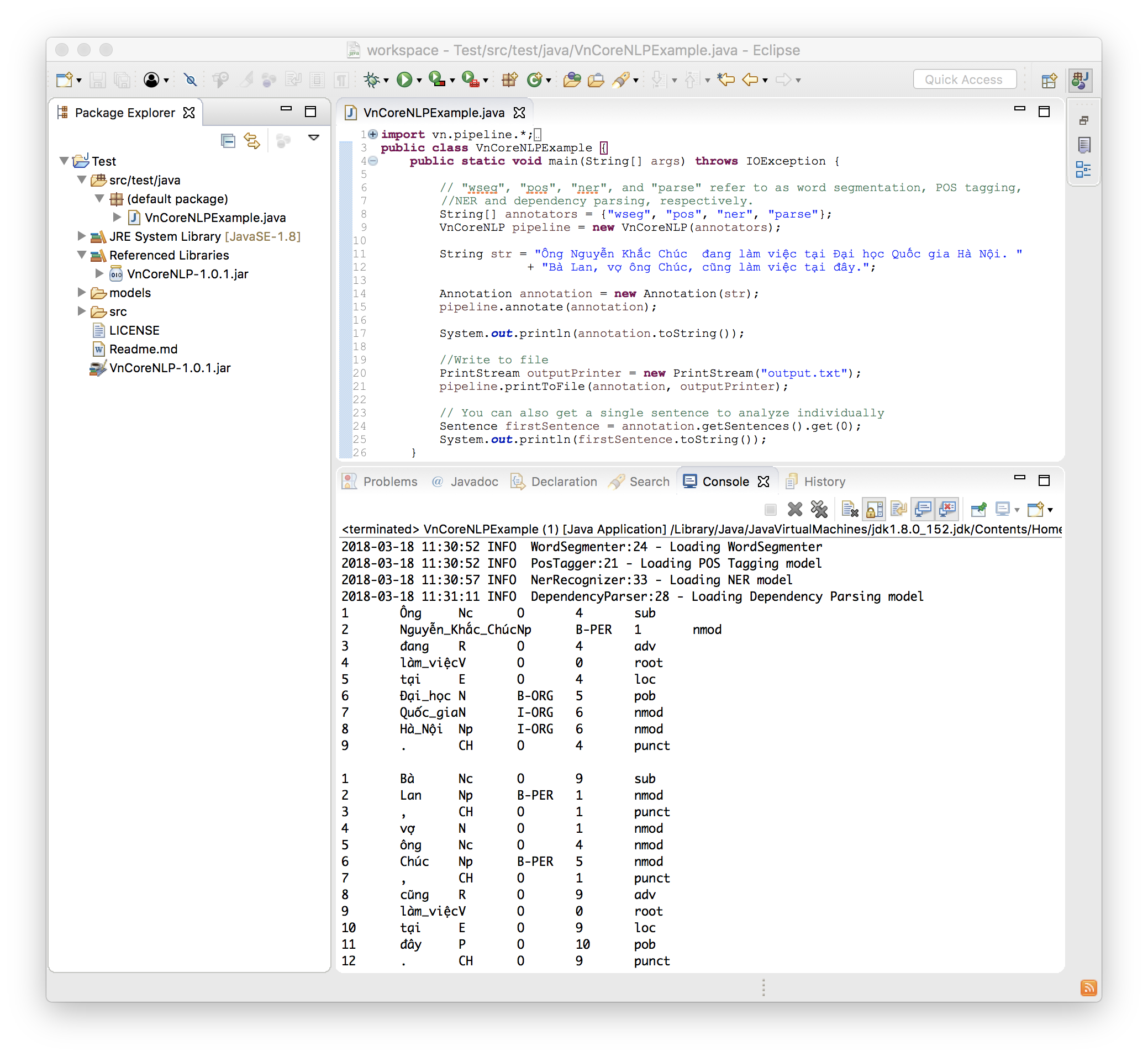
以下代码是一个简单而完整的示例:
import vn . pipeline .*;
import java . io .*;
public class VnCoreNLPExample {
public static void main ( String [] args ) throws IOException {
// "wseg", "pos", "ner", and "parse" refer to as word segmentation, POS tagging, NER and dependency parsing, respectively.
String [] annotators = { "wseg" , "pos" , "ner" , "parse" };
VnCoreNLP pipeline = new VnCoreNLP ( annotators );
String str = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ;
Annotation annotation = new Annotation ( str );
pipeline . annotate ( annotation );
System . out . println ( annotation . toString ());
// 1 Ông Nc O 4 sub
// 2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
// 3 đang R O 4 adv
// 4 làm_việc V O 0 root
// ...
//Write to file
PrintStream outputPrinter = new PrintStream ( "output.txt" );
pipeline . printToFile ( annotation , outputPrinter );
// You can also get a single sentence to analyze individually
Sentence firstSentence = annotation . getSentences (). get ( 0 );
System . out . println ( firstSentence . toString ());
}
}
有关API详细信息,请参见文件夹src中的VNCorenlp的开源。
请参阅上面或NLP-Progress论文[1,2,3]中的详细信息。


