VnCoreNLP
v1.2
Vncorenlp adalah pipa anotasi NLP yang cepat dan akurat untuk orang Vietnam, memberikan anotasi linguistik yang kaya melalui komponen NLP kunci dari segmentasi kata , penandaan POS , pengakuan entitas yang dinamai (NER) dan parsing ketergantungan . Pengguna tidak perlu menginstal dependensi eksternal. Pengguna dapat menjalankan pipa pemrosesan baik dari baris perintah atau API. Arsitektur umum dan hasil eksperimen vncorenlp dapat ditemukan di makalah terkait berikut:
Harap kutip kertas [1] Setiap kali vncorenlp digunakan untuk menghasilkan hasil yang dipublikasikan atau dimasukkan ke dalam perangkat lunak lain. Jika Anda berurusan secara mendalam dengan segmentasi kata atau penandaan POS, Anda juga didorong untuk mengutip kertas [2] atau [3], masing -masing.
Jika Anda mencari versi ringan, komponen kata dan komponen penandaan POS juga telah dirilis sebagai paket independen rdrsmenter [2] dan vnmarmot [3], secara resepektif.
Java 1.8+ (prasyarat)
File VnCoreNLP-1.2.jar (27MB) dan models folder (115MB) ditempatkan di folder kerja yang sama.
Python 3.6+ Jika menggunakan pembungkus python vncorenlp. Untuk menginstal pembungkus ini, pengguna harus menjalankan perintah berikut:
$ pip3 install py_vncorenlp
Terima kasih khusus kepada Linh the Nguyen untuk membuat pembungkus ini!
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local working folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP from the local working folder that contains both `VnCoreNLP-1.2.jar` and `models`
model = py_vncorenlp . VnCoreNLP ( save_dir = '/absolute/path/to/vncorenlp' )
# Equivalent to: model = py_vncorenlp.VnCoreNLP(annotators=["wseg", "pos", "ner", "parse"], save_dir='/absolute/path/to/vncorenlp')
# Annotate a raw corpus
model . annotate_file ( input_file = "/absolute/path/to/input/file" , output_file = "/absolute/path/to/output/file" )
# Annotate a raw text
model . print_out ( model . annotate_text ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))Secara default, output diformat dengan 6 kolom yang mewakili indeks kata, bentuk kata, tag POS, label ner, indeks kepala dari kata saat ini dan jenis hubungan ketergantungannya:
1 Ông Nc O 4 sub
2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
3 đang R O 4 adv
4 làm_việc V O 0 root
5 tại E O 4 loc
6 Đại_học N B-ORG 5 pob
...
Untuk pengguna yang menggunakan VNCorenLP hanya untuk segmentasi kata:
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
text = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây."
output = rdrsegmenter . word_segment ( text )
print ( output )
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .'] Anda dapat menjalankan vncorenlp untuk membuat anotasi input corpus teks mentah (misalnya kumpulan konten berita) dengan menggunakan perintah berikut:
// To perform word segmentation, POS tagging, NER and then dependency parsing
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt
// To perform word segmentation, POS tagging and then NER
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos,ner
// To perform word segmentation and then POS tagging
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos
// To perform word segmentation
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg
Kode berikut adalah contoh sederhana dan lengkap:
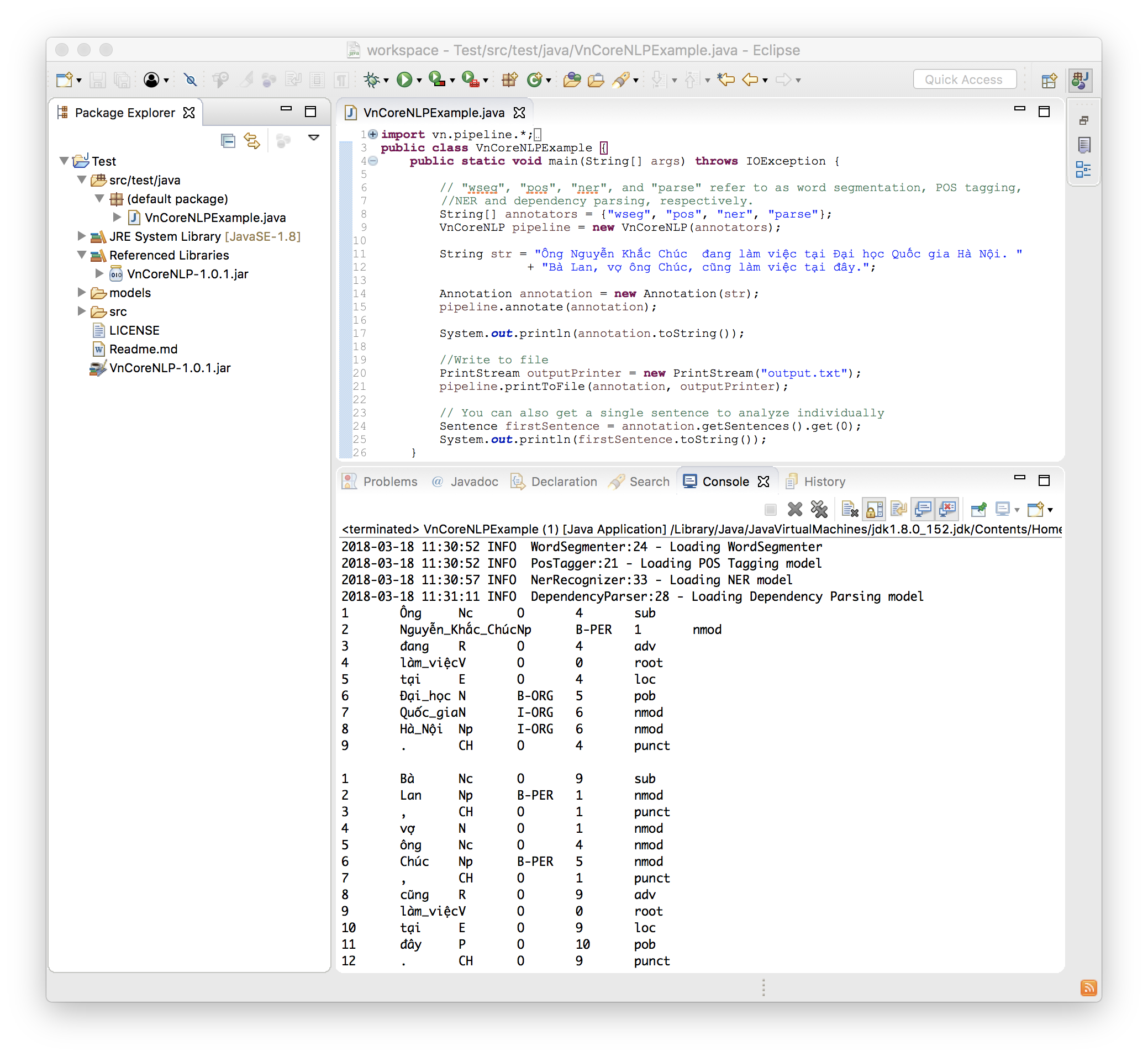
import vn . pipeline .*;
import java . io .*;
public class VnCoreNLPExample {
public static void main ( String [] args ) throws IOException {
// "wseg", "pos", "ner", and "parse" refer to as word segmentation, POS tagging, NER and dependency parsing, respectively.
String [] annotators = { "wseg" , "pos" , "ner" , "parse" };
VnCoreNLP pipeline = new VnCoreNLP ( annotators );
String str = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ;
Annotation annotation = new Annotation ( str );
pipeline . annotate ( annotation );
System . out . println ( annotation . toString ());
// 1 Ông Nc O 4 sub
// 2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
// 3 đang R O 4 adv
// 4 làm_việc V O 0 root
// ...
//Write to file
PrintStream outputPrinter = new PrintStream ( "output.txt" );
pipeline . printToFile ( annotation , outputPrinter );
// You can also get a single sentence to analyze individually
Sentence firstSentence = annotation . getSentences (). get ( 0 );
System . out . println ( firstSentence . toString ());
}
}
Lihat Sumber Terbuka VnCorenlp di folder src untuk detail API.
Lihat detail dalam makalah [1,2,3] di atas atau di NLP-progress.


