VnCoreNLP
v1.2
VNCORENLP - это быстрый и точный конвейер аннотаций NLP для вьетнамцев, обеспечивающий богатые лингвистические аннотации посредством ключевых компонентов NLP сегментации слов , мечения POS , названного распознавания сущностей (NER) и анализа зависимости . Пользователям не нужно устанавливать внешние зависимости. Пользователи могут запускать трубопроводы обработки из командной строки или API. Общая архитектура и экспериментальные результаты vncorenlp можно найти в следующих связанных документах:
Пожалуйста, цитируйте бумагу [1] всякий раз, когда vncorenlp используется для получения опубликованных результатов или включения в другое программное обеспечение. Если вы подробно справляетесь с сегментацией слов или тегом POS, вам также рекомендуется цитировать Paper [2] или [3], соответственно.
Если вы ищете легкие версии, сегментация Word и POS-компоненты Vncorenlp также были выпущены в виде независимых пакетов Rdrsegmenter [2] и Vnmarmot [3], повторно.
Java 1.8+ (предпосылка)
File VnCoreNLP-1.2.jar (27 МБ) и models (115 МБ) помещаются в одну и ту же рабочую папку.
Python 3.6+ если использует обертку Python vncorenlp. Чтобы установить эту обертку, пользователи должны запустить следующую команду:
$ pip3 install py_vncorenlp
Особая благодарность Линху Нгуен за создание этой обертки!
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local working folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP from the local working folder that contains both `VnCoreNLP-1.2.jar` and `models`
model = py_vncorenlp . VnCoreNLP ( save_dir = '/absolute/path/to/vncorenlp' )
# Equivalent to: model = py_vncorenlp.VnCoreNLP(annotators=["wseg", "pos", "ner", "parse"], save_dir='/absolute/path/to/vncorenlp')
# Annotate a raw corpus
model . annotate_file ( input_file = "/absolute/path/to/input/file" , output_file = "/absolute/path/to/output/file" )
# Annotate a raw text
model . print_out ( model . annotate_text ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))По умолчанию вывод отформатируется с 6 столбцами, представляющими индекс слов, форму слова, тег POS, метка NER, индекс головки текущего слова и тип его зависимости:
1 Ông Nc O 4 sub
2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
3 đang R O 4 adv
4 làm_việc V O 0 root
5 tại E O 4 loc
6 Đại_học N B-ORG 5 pob
...
Для пользователей, которые используют vncorenlp только для сегментации слов:
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
text = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây."
output = rdrsegmenter . word_segment ( text )
print ( output )
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .'] Вы можете запустить vncorenlp для аннотирования входного необработанного текстового корпуса (например, коллекция контента новостей), используя следующие команды:
// To perform word segmentation, POS tagging, NER and then dependency parsing
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt
// To perform word segmentation, POS tagging and then NER
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos,ner
// To perform word segmentation and then POS tagging
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos
// To perform word segmentation
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg
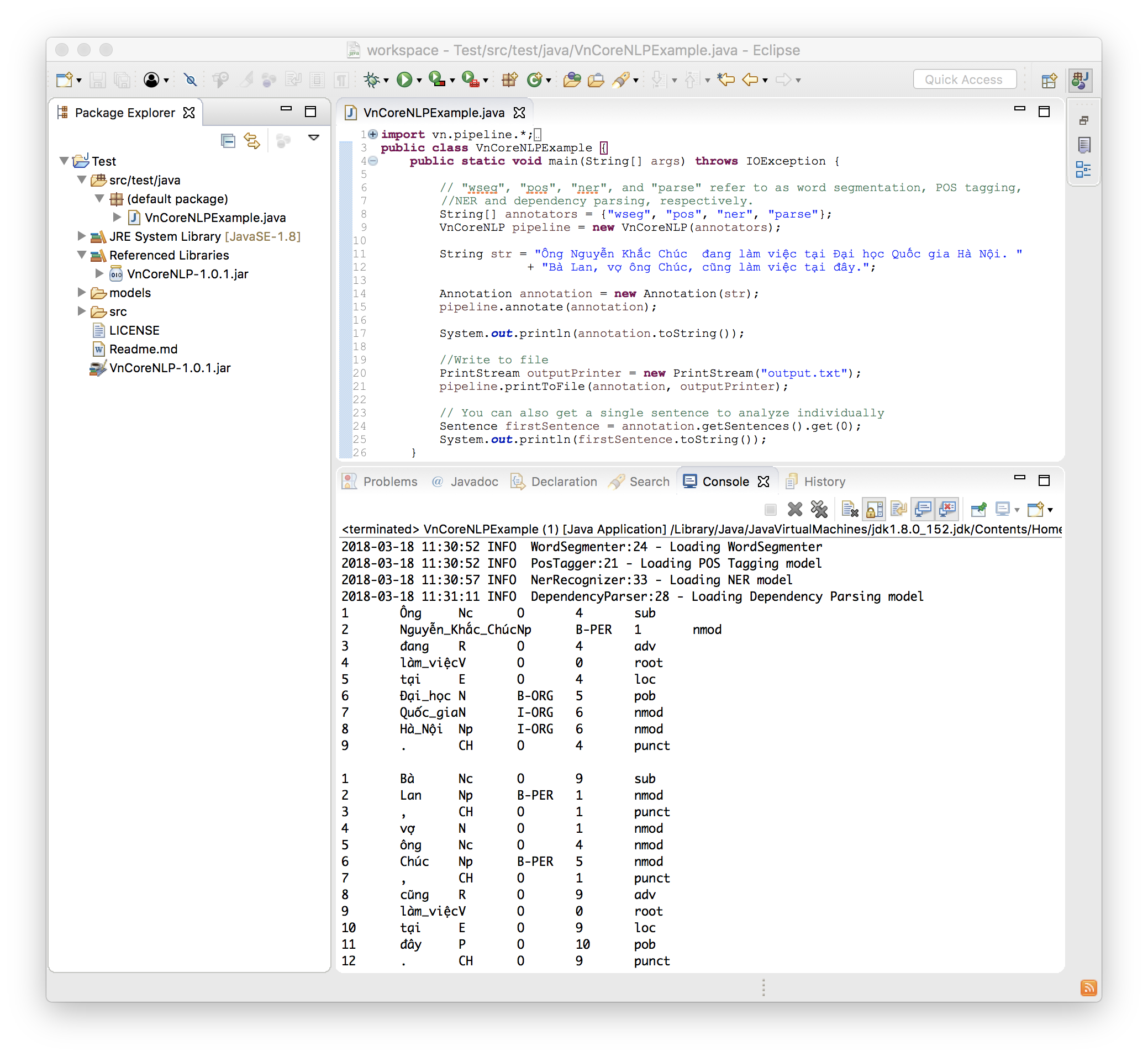
Следующий код является простым и полным примером:
import vn . pipeline .*;
import java . io .*;
public class VnCoreNLPExample {
public static void main ( String [] args ) throws IOException {
// "wseg", "pos", "ner", and "parse" refer to as word segmentation, POS tagging, NER and dependency parsing, respectively.
String [] annotators = { "wseg" , "pos" , "ner" , "parse" };
VnCoreNLP pipeline = new VnCoreNLP ( annotators );
String str = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ;
Annotation annotation = new Annotation ( str );
pipeline . annotate ( annotation );
System . out . println ( annotation . toString ());
// 1 Ông Nc O 4 sub
// 2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
// 3 đang R O 4 adv
// 4 làm_việc V O 0 root
// ...
//Write to file
PrintStream outputPrinter = new PrintStream ( "output.txt" );
pipeline . printToFile ( annotation , outputPrinter );
// You can also get a single sentence to analyze individually
Sentence firstSentence = annotation . getSentences (). get ( 0 );
System . out . println ( firstSentence . toString ());
}
}
См. Открытый источник Vncorenlp в папке src для деталей API.
См. Подробности в документах [1,2,3] выше или в NLP-Progress.


