VnCoreNLP
v1.2
O VncorenLP é um pipeline de anotação de NLP rápido e preciso para vietnamita, fornecendo anotações linguísticas ricas por meio de principais componentes da PNL da segmentação de palavras , marcação de POS , nomeado reconhecimento de entidade (NER) e análise de dependência . Os usuários não precisam instalar dependências externas. Os usuários podem executar pipelines de processamento da linha de comando ou da API. A arquitetura geral e os resultados experimentais do VncorenLP podem ser encontrados nos seguintes artigos relacionados:
Cite o papel [1] sempre que o VncorenLP for usado para produzir resultados publicados ou incorporado em outro software. Se você estiver lidando em profundidade com a segmentação de palavras ou a marcação de POS, também será incentivado a citar o papel [2] ou [3], respectivamente.
Se você estiver procurando por versões leves, os componentes de marcação de palavras do VncorenLP e POS também foram lançados como pacotes independentes RDRSEGEREGERER [2] e VNMARMOT [3], serecectivamente.
Java 1.8+ (pré -requisito)
Arquivo VnCoreNLP-1.2.jar (27 MB) e models de pasta (115 MB) são colocados na mesma pasta de trabalho.
Python 3.6+ se estiver usando um invólucro python de vncorenlp. Para instalar este invólucro, os usuários precisam executar o seguinte comando:
$ pip3 install py_vncorenlp
Um agradecimento especial a Linh the Nguyen por criar este invólucro!
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local working folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP from the local working folder that contains both `VnCoreNLP-1.2.jar` and `models`
model = py_vncorenlp . VnCoreNLP ( save_dir = '/absolute/path/to/vncorenlp' )
# Equivalent to: model = py_vncorenlp.VnCoreNLP(annotators=["wseg", "pos", "ner", "parse"], save_dir='/absolute/path/to/vncorenlp')
# Annotate a raw corpus
model . annotate_file ( input_file = "/absolute/path/to/input/file" , output_file = "/absolute/path/to/output/file" )
# Annotate a raw text
model . print_out ( model . annotate_text ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))Por padrão, a saída é formatada com 6 colunas representando o índice de palavras, formulário de palavras, tag POS, etiqueta ner, índice de cabeça da palavra atual e seu tipo de relação de dependência:
1 Ông Nc O 4 sub
2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
3 đang R O 4 adv
4 làm_việc V O 0 root
5 tại E O 4 loc
6 Đại_học N B-ORG 5 pob
...
Para usuários que usam VncorenLP apenas para segmentação de palavras:
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
text = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây."
output = rdrsegmenter . word_segment ( text )
print ( output )
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .'] Você pode executar o VncorenLP para anotar um corpus de texto bruto de entrada (por exemplo, uma coleção de conteúdo de notícias) usando os seguintes comandos:
// To perform word segmentation, POS tagging, NER and then dependency parsing
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt
// To perform word segmentation, POS tagging and then NER
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos,ner
// To perform word segmentation and then POS tagging
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos
// To perform word segmentation
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg
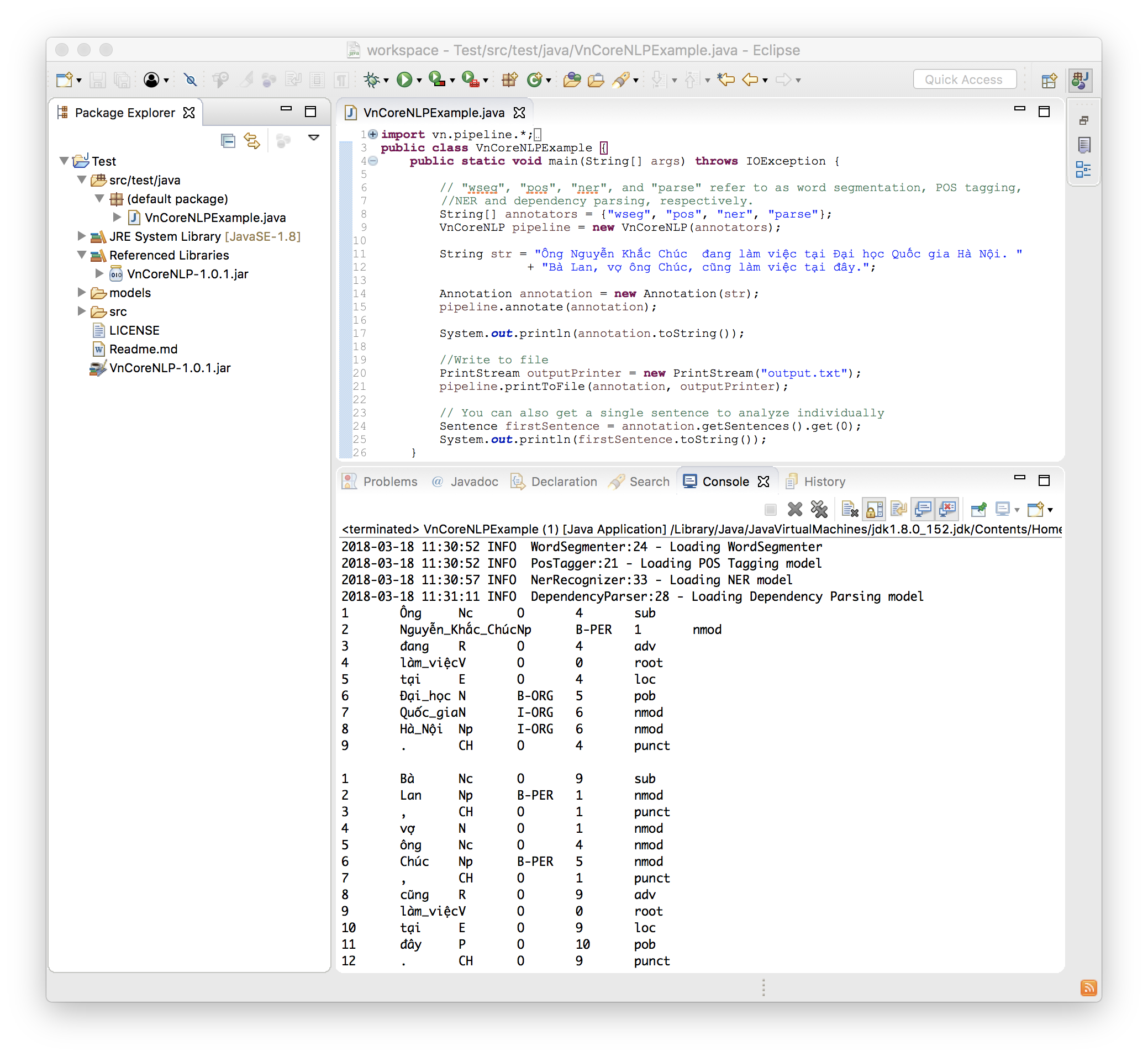
O código a seguir é um exemplo simples e completo:
import vn . pipeline .*;
import java . io .*;
public class VnCoreNLPExample {
public static void main ( String [] args ) throws IOException {
// "wseg", "pos", "ner", and "parse" refer to as word segmentation, POS tagging, NER and dependency parsing, respectively.
String [] annotators = { "wseg" , "pos" , "ner" , "parse" };
VnCoreNLP pipeline = new VnCoreNLP ( annotators );
String str = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ;
Annotation annotation = new Annotation ( str );
pipeline . annotate ( annotation );
System . out . println ( annotation . toString ());
// 1 Ông Nc O 4 sub
// 2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
// 3 đang R O 4 adv
// 4 làm_việc V O 0 root
// ...
//Write to file
PrintStream outputPrinter = new PrintStream ( "output.txt" );
pipeline . printToFile ( annotation , outputPrinter );
// You can also get a single sentence to analyze individually
Sentence firstSentence = annotation . getSentences (). get ( 0 );
System . out . println ( firstSentence . toString ());
}
}
Consulte a fonte aberta do VncorenLP na pasta src para obter detalhes da API.
Veja detalhes em artigos [1,2,3] acima ou no NLP-Progress.


