VnCoreNLP
v1.2
VncorenLP هو خط أنابيب شرح NLP سريع ودقيق للفيتناميين ، ويوفر التعليقات التوضيحية اللغوية الغنية من خلال مكونات NLP الرئيسية لتجزئة الكلمات ، وعلامة POS ، والتعرف على الكيان المسماة (NER) وحالة تحليل التبعية . لا يتعين على المستخدمين تثبيت تبعيات خارجية. يمكن للمستخدمين تشغيل خطوط أنابيب المعالجة من سطر الأوامر أو واجهة برمجة التطبيقات. يمكن العثور على الهندسة المعمارية العامة والنتائج التجريبية لـ VncorenLP في الأوراق التالية ذات الصلة:
يرجى الاستشهاد بالورق [1] كلما تم استخدام vncorenlp لإنتاج نتائج منشورة أو دمجها في برامج أخرى. إذا كنت تتعامل بتعمق مع تجزئة الكلمات أو وضع علامات POS ، فيتم تشجيعك أيضًا على الاستشهاد بالورق [2] أو [3] ، على التوالي.
إذا كنت تبحث عن إصدارات خفيفة الوزن ، فقد تم إصدار مكونات Word Word الخاصة بـ VncorenLP ومكونات وضع علامات POS كحزم مستقلة Rdrsegmenter [2] و Vnmarmot [3] ، بإعادة الاستغناء عنها.
Java 1.8+ (المتطلب السابق)
يتم وضع ملف VnCoreNLP-1.2.jar (27 ميجابايت) models المجلدات (115 ميجابايت) في نفس المجلد العاملة.
Python 3.6+ إذا كان يستخدم غلاف Python من vncorenlp. لتثبيت هذا الغلاف ، يتعين على المستخدمين تشغيل الأمر التالي:
$ pip3 install py_vncorenlp
شكر خاص إلى لينه نغوين لإنشاء هذا الغلاف!
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local working folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP from the local working folder that contains both `VnCoreNLP-1.2.jar` and `models`
model = py_vncorenlp . VnCoreNLP ( save_dir = '/absolute/path/to/vncorenlp' )
# Equivalent to: model = py_vncorenlp.VnCoreNLP(annotators=["wseg", "pos", "ner", "parse"], save_dir='/absolute/path/to/vncorenlp')
# Annotate a raw corpus
model . annotate_file ( input_file = "/absolute/path/to/input/file" , output_file = "/absolute/path/to/output/file" )
# Annotate a raw text
model . print_out ( model . annotate_text ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))بشكل افتراضي ، يتم تنسيق الإخراج مع 6 أعمدة تمثل فهرس Word ، نموذج Word ، علامة POS ، تسمية ner ، فهرس الرأس للكلمة الحالية ونوع علاقة التبعية:
1 Ông Nc O 4 sub
2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
3 đang R O 4 adv
4 làm_việc V O 0 root
5 tại E O 4 loc
6 Đại_học N B-ORG 5 pob
...
للمستخدمين الذين يستخدمون vncorenlp فقط لتجزئة الكلمات:
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
text = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây."
output = rdrsegmenter . word_segment ( text )
print ( output )
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .'] يمكنك تشغيل vncorenlp للتعليق على إدخال نص RAW Text Corpus (على سبيل المثال مجموعة من محتوى الأخبار) باستخدام الأوامر التالية:
// To perform word segmentation, POS tagging, NER and then dependency parsing
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt
// To perform word segmentation, POS tagging and then NER
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos,ner
// To perform word segmentation and then POS tagging
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos
// To perform word segmentation
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg
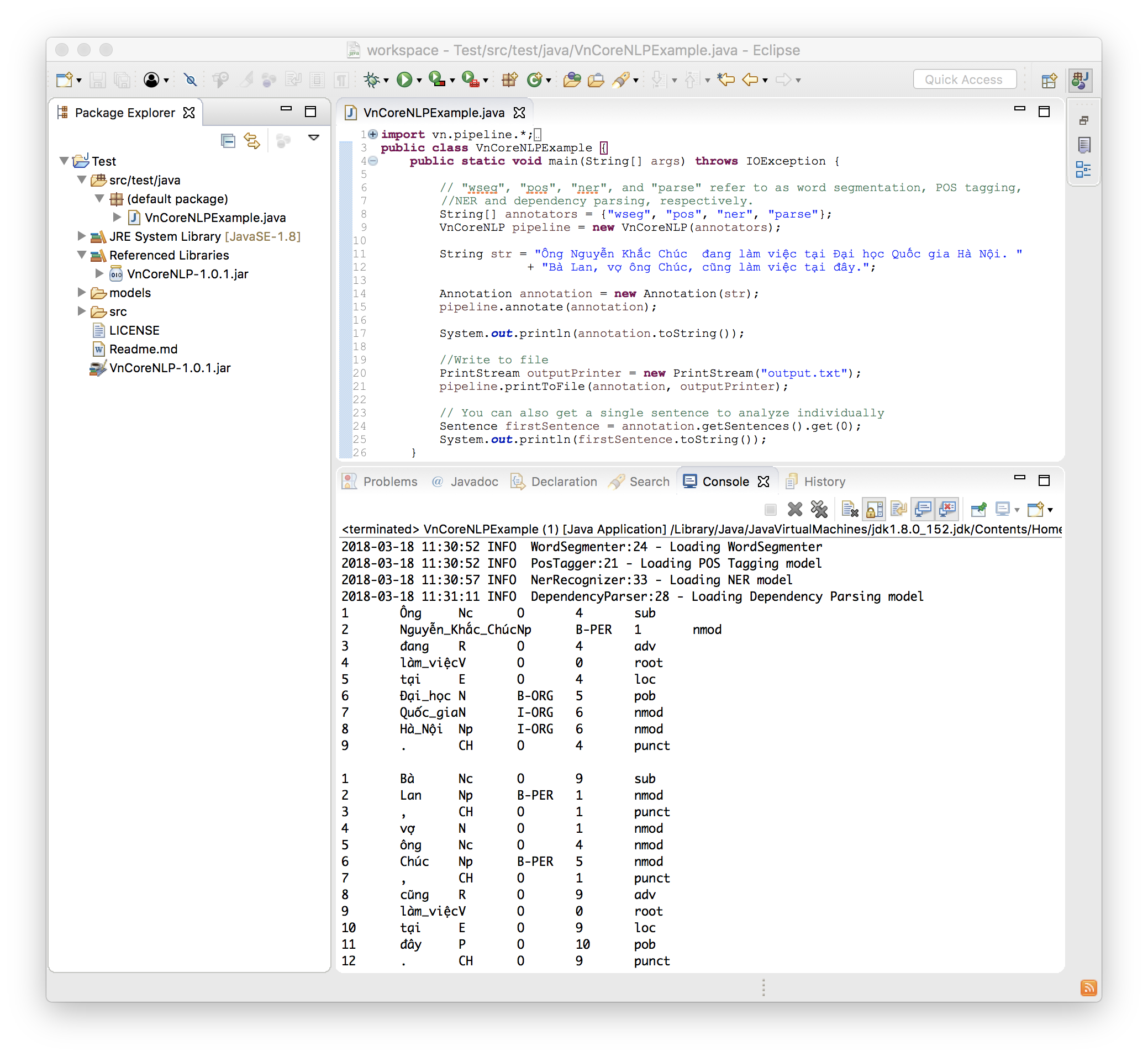
الرمز التالي هو مثال بسيط وكامل:
import vn . pipeline .*;
import java . io .*;
public class VnCoreNLPExample {
public static void main ( String [] args ) throws IOException {
// "wseg", "pos", "ner", and "parse" refer to as word segmentation, POS tagging, NER and dependency parsing, respectively.
String [] annotators = { "wseg" , "pos" , "ner" , "parse" };
VnCoreNLP pipeline = new VnCoreNLP ( annotators );
String str = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ;
Annotation annotation = new Annotation ( str );
pipeline . annotate ( annotation );
System . out . println ( annotation . toString ());
// 1 Ông Nc O 4 sub
// 2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
// 3 đang R O 4 adv
// 4 làm_việc V O 0 root
// ...
//Write to file
PrintStream outputPrinter = new PrintStream ( "output.txt" );
pipeline . printToFile ( annotation , outputPrinter );
// You can also get a single sentence to analyze individually
Sentence firstSentence = annotation . getSentences (). get ( 0 );
System . out . println ( firstSentence . toString ());
}
}
راجع المصدر المفتوح لـ Vncorenlp في المجلد src للحصول على تفاصيل API.
انظر التفاصيل في الأوراق [1،2،3] أعلاه أو في NLP-Progress.


