VnCoreNLP
v1.2
vncorenlpは、ベトナム語の高速で正確なNLPアノテーションパイプラインであり、単語セグメンテーション、 POSタグ付け、エンティティ認識(NER)、依存関係解析の主要なNLPコンポーネントを通じて豊富な言語注釈を提供します。ユーザーは外部依存関係をインストールする必要はありません。ユーザーは、コマンドラインまたはAPIのいずれかからパイプラインの処理を実行できます。 Vncorenlpの一般的なアーキテクチャと実験結果は、次の関連する論文に記載されています。
vncorenlpを使用して公開された結果を作成したり、他のソフトウェアに組み込んだりする場合は、紙[1]を引用してください。単語セグメンテーションまたはPOSタグ付けのいずれかを詳細に扱っている場合は、それぞれ紙[2]または[3]を引用することも奨励されています。
Light-Weightバージョンを探している場合、VNCORENLPの単語セグメンテーションとPOSタグ付けコンポーネントは、独立したパッケージRDRSegmenter [2]およびVNMarmot [3]としてリリースされています。
Java 1.8+ (前提条件)
ファイルVnCoreNLP-1.2.jar (27MB)およびフォルダーmodels (115MB)は、同じ作業フォルダーに配置されています。
Python 3.6+ vncorenlpのPythonラッパーを使用する場合。このラッパーをインストールするには、ユーザーは次のコマンドを実行する必要があります。
$ pip3 install py_vncorenlp
このラッパーを作成してくれたNguyenのLinhに感謝します!
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local working folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP from the local working folder that contains both `VnCoreNLP-1.2.jar` and `models`
model = py_vncorenlp . VnCoreNLP ( save_dir = '/absolute/path/to/vncorenlp' )
# Equivalent to: model = py_vncorenlp.VnCoreNLP(annotators=["wseg", "pos", "ner", "parse"], save_dir='/absolute/path/to/vncorenlp')
# Annotate a raw corpus
model . annotate_file ( input_file = "/absolute/path/to/input/file" , output_file = "/absolute/path/to/output/file" )
# Annotate a raw text
model . print_out ( model . annotate_text ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))デフォルトでは、出力は、単語インデックス、ワードフォーム、POSタグ、NERラベル、現在の単語のヘッドインデックス、およびその依存関係タイプを表す6列でフォーマットされます。
1 Ông Nc O 4 sub
2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
3 đang R O 4 adv
4 làm_việc V O 0 root
5 tại E O 4 loc
6 Đại_học N B-ORG 5 pob
...
WordセグメンテーションにのみVNCORENLPを使用するユーザーの場合:
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
text = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây."
output = rdrsegmenter . word_segment ( text )
print ( output )
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .'] 次のコマンドを使用して、vncorenlpを実行して、入力生テキストコーパス(たとえば、ニュースコンテンツのコレクション)に注釈を付けます。
// To perform word segmentation, POS tagging, NER and then dependency parsing
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt
// To perform word segmentation, POS tagging and then NER
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos,ner
// To perform word segmentation and then POS tagging
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos
// To perform word segmentation
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg
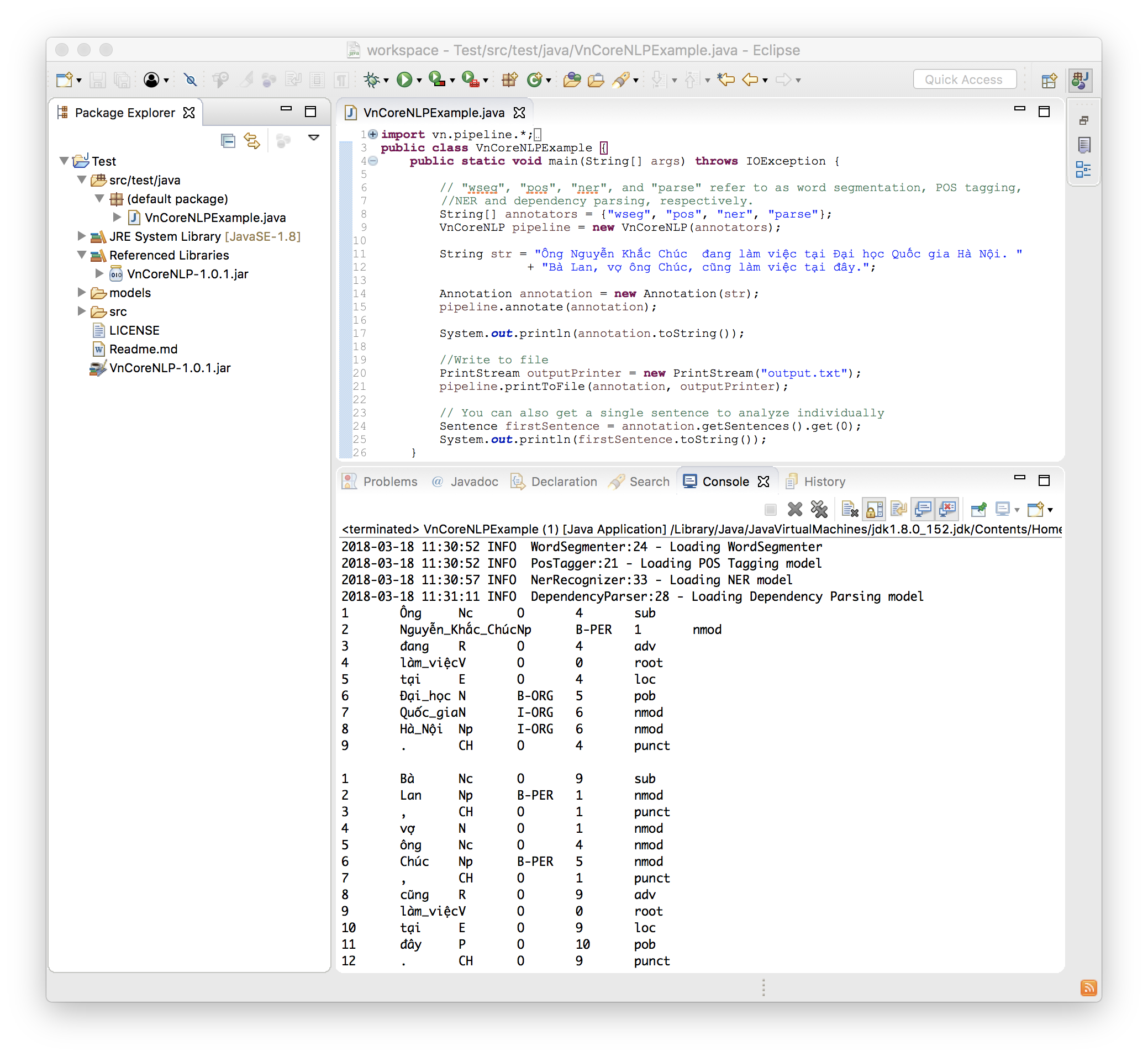
次のコードは、シンプルで完全な例です。
import vn . pipeline .*;
import java . io .*;
public class VnCoreNLPExample {
public static void main ( String [] args ) throws IOException {
// "wseg", "pos", "ner", and "parse" refer to as word segmentation, POS tagging, NER and dependency parsing, respectively.
String [] annotators = { "wseg" , "pos" , "ner" , "parse" };
VnCoreNLP pipeline = new VnCoreNLP ( annotators );
String str = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ;
Annotation annotation = new Annotation ( str );
pipeline . annotate ( annotation );
System . out . println ( annotation . toString ());
// 1 Ông Nc O 4 sub
// 2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
// 3 đang R O 4 adv
// 4 làm_việc V O 0 root
// ...
//Write to file
PrintStream outputPrinter = new PrintStream ( "output.txt" );
pipeline . printToFile ( annotation , outputPrinter );
// You can also get a single sentence to analyze individually
Sentence firstSentence = annotation . getSentences (). get ( 0 );
System . out . println ( firstSentence . toString ());
}
}
APIの詳細については、Vncorenlpのフォルダーsrcのオープンソースを参照してください。
上記の論文[1,2,3]またはNLP-Progressの詳細を参照してください。


