VnCoreNLP
v1.2
VNCORENLP es una tubería de anotación de PNL rápida y precisa para vietnamitas, proporcionando anotaciones lingüísticas ricas a través de componentes clave de PNL de segmentación de palabras , etiquetado POS , reconocimiento de entidad nombrado (NER) y análisis de dependencia . Los usuarios no tienen que instalar dependencias externas. Los usuarios pueden ejecutar tuberías de procesamiento desde la línea de comandos o la API. La arquitectura general y los resultados experimentales de VNCorenLP se pueden encontrar en los siguientes documentos relacionados:
Cite Paper [1] siempre que VNCorenLP se use para producir resultados publicados o incorporados en otro software. Si está tratando en profundidad con la segmentación de palabras o el etiquetado POS, también se le recomienda citar el papel [2] o [3], respectivamente.
Si está buscando versiones de peso ligero, la segmentación de palabras de VNCORENLP y los componentes de etiquetado POS también se han lanzado como paquetes independientes RDRsegmenter [2] y VNMarmot [3], de forma resepectiva.
Java 1.8+ (requisito previo)
El archivo VnCoreNLP-1.2.jar (27MB) y models de carpeta (115MB) se colocan en la misma carpeta de trabajo.
Python 3.6+ si usa un envoltorio de pitón de vncorenlp. Para instalar este envoltorio, los usuarios deben ejecutar el siguiente comando:
$ pip3 install py_vncorenlp
¡Un agradecimiento especial a Linh The Nguyen por crear este envoltorio!
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local working folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP from the local working folder that contains both `VnCoreNLP-1.2.jar` and `models`
model = py_vncorenlp . VnCoreNLP ( save_dir = '/absolute/path/to/vncorenlp' )
# Equivalent to: model = py_vncorenlp.VnCoreNLP(annotators=["wseg", "pos", "ner", "parse"], save_dir='/absolute/path/to/vncorenlp')
# Annotate a raw corpus
model . annotate_file ( input_file = "/absolute/path/to/input/file" , output_file = "/absolute/path/to/output/file" )
# Annotate a raw text
model . print_out ( model . annotate_text ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))Por defecto, la salida está formateada con 6 columnas que representan el índice de palabras, forma de palabra, etiqueta POS, etiqueta ner, índice de cabeza de la palabra actual y su tipo de relación de dependencia:
1 Ông Nc O 4 sub
2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
3 đang R O 4 adv
4 làm_việc V O 0 root
5 tại E O 4 loc
6 Đại_học N B-ORG 5 pob
...
Para los usuarios que usan VNCorenLP solo para la segmentación de palabras:
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
text = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây."
output = rdrsegmenter . word_segment ( text )
print ( output )
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .'] Puede ejecutar vncorenlp para anotar un corpus de texto sin procesar de entrada (por ejemplo, una colección de contenido de noticias) utilizando los siguientes comandos:
// To perform word segmentation, POS tagging, NER and then dependency parsing
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt
// To perform word segmentation, POS tagging and then NER
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos,ner
// To perform word segmentation and then POS tagging
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos
// To perform word segmentation
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg
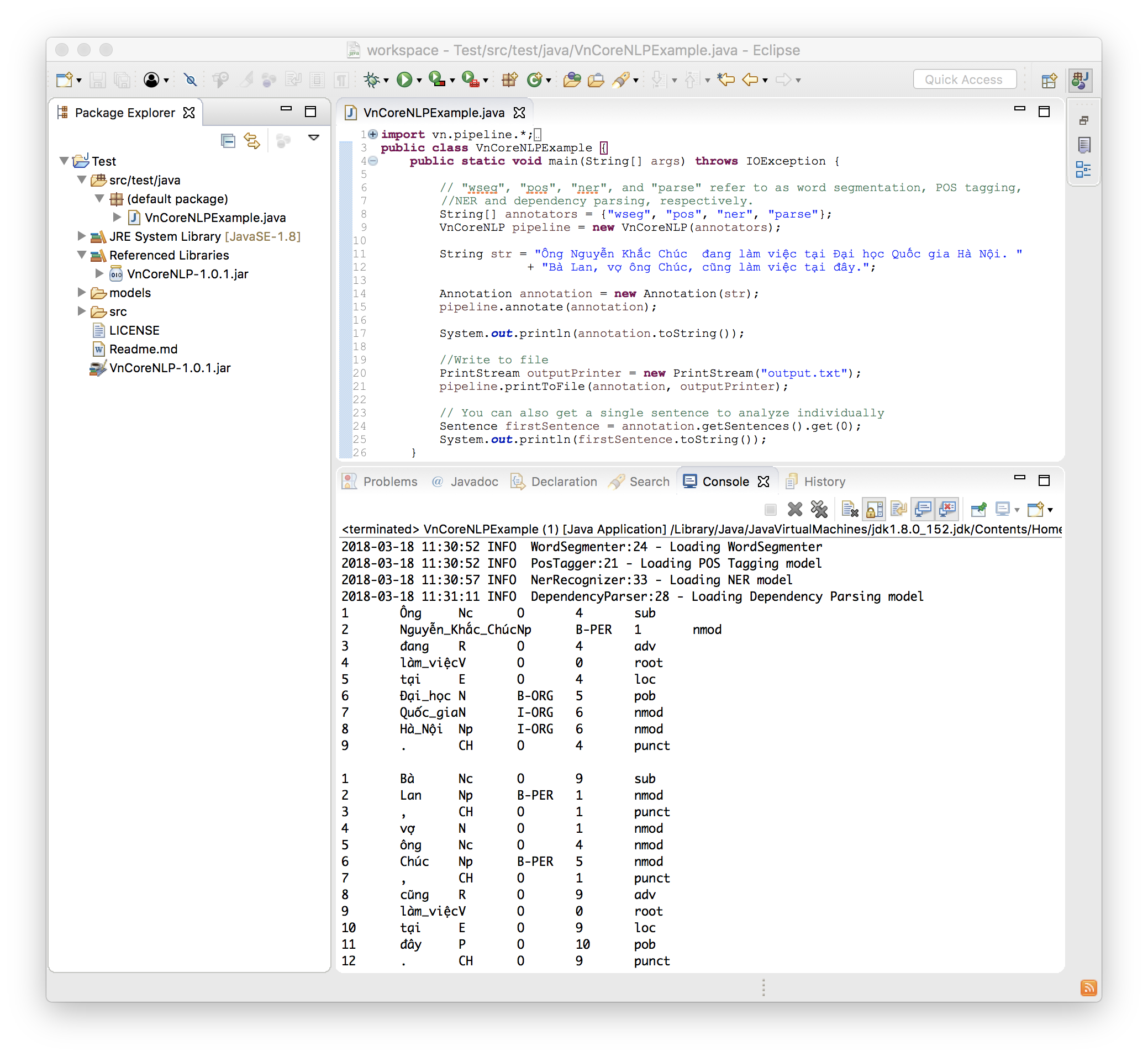
El siguiente código es un ejemplo simple y completo:
import vn . pipeline .*;
import java . io .*;
public class VnCoreNLPExample {
public static void main ( String [] args ) throws IOException {
// "wseg", "pos", "ner", and "parse" refer to as word segmentation, POS tagging, NER and dependency parsing, respectively.
String [] annotators = { "wseg" , "pos" , "ner" , "parse" };
VnCoreNLP pipeline = new VnCoreNLP ( annotators );
String str = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ;
Annotation annotation = new Annotation ( str );
pipeline . annotate ( annotation );
System . out . println ( annotation . toString ());
// 1 Ông Nc O 4 sub
// 2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
// 3 đang R O 4 adv
// 4 làm_việc V O 0 root
// ...
//Write to file
PrintStream outputPrinter = new PrintStream ( "output.txt" );
pipeline . printToFile ( annotation , outputPrinter );
// You can also get a single sentence to analyze individually
Sentence firstSentence = annotation . getSentences (). get ( 0 );
System . out . println ( firstSentence . toString ());
}
}
Consulte la fuente abierta de VNCORENLP en la carpeta src para obtener detalles de la API.
Vea los detalles en los documentos [1,2,3] arriba o en el progreso de PNL.


