VnCoreNLP
v1.2
VNCorenlp est un pipeline d'annotation NLP rapide et précis pour les vietnamiens, fournissant de riches annotations linguistiques via des composantes clés NLP de la segmentation des mots , du marquage POS , de la reconnaissance d'entité nommée (NER) et de l'analyse de dépendance . Les utilisateurs n'ont pas à installer des dépendances externes. Les utilisateurs peuvent exécuter des pipelines de traitement à partir de la ligne de commande ou de l'API. L'architecture générale et les résultats expérimentaux de VNCorenlp peuvent être trouvés dans les articles connexes suivants:
Veuillez citer du papier [1] chaque fois que Vncorenlp est utilisé pour produire des résultats publiés ou incorporés dans d'autres logiciels. Si vous traitez en profondeur avec la segmentation des mots ou le marquage de POS, vous êtes également encouragé à citer du papier [2] ou [3], respectivement.
Si vous recherchez des versions légères, la segmentation des mots et les composants de marquage de POS de Vncorenlp ont également été publiés sous forme de packages indépendants RDRSegmenter [2] et VNMarmot [3], réceptive.
Java 1.8+ (préalable)
Le fichier VnCoreNLP-1.2.jar (27 Mo) et models de dossiers (115 Mo) sont placés dans le même dossier de travail.
Python 3.6+ Si vous utilisez un wrapper Python de Vncorenlp. Pour installer ce wrapper, les utilisateurs doivent exécuter la commande suivante:
$ pip3 install py_vncorenlp
Un merci spécial à Linh le Nguyen pour avoir créé cet emballage!
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local working folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP from the local working folder that contains both `VnCoreNLP-1.2.jar` and `models`
model = py_vncorenlp . VnCoreNLP ( save_dir = '/absolute/path/to/vncorenlp' )
# Equivalent to: model = py_vncorenlp.VnCoreNLP(annotators=["wseg", "pos", "ner", "parse"], save_dir='/absolute/path/to/vncorenlp')
# Annotate a raw corpus
model . annotate_file ( input_file = "/absolute/path/to/input/file" , output_file = "/absolute/path/to/output/file" )
# Annotate a raw text
model . print_out ( model . annotate_text ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))Par défaut, la sortie est formatée avec 6 colonnes représentant l'index de mots, le formulaire de mot, la balise POS, l'étiquette NER, l'index de tête du mot actuel et son type de relation de dépendance:
1 Ông Nc O 4 sub
2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
3 đang R O 4 adv
4 làm_việc V O 0 root
5 tại E O 4 loc
6 Đại_học N B-ORG 5 pob
...
Pour les utilisateurs qui utilisent VNCorenlp uniquement pour la segmentation des mots:
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
text = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây."
output = rdrsegmenter . word_segment ( text )
print ( output )
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .'] Vous pouvez exécuter vncorenlp pour annoter un corpus de texte brut d'entrée (par exemple, une collection de nouvelles de contenu) en utilisant les commandes suivantes:
// To perform word segmentation, POS tagging, NER and then dependency parsing
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt
// To perform word segmentation, POS tagging and then NER
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos,ner
// To perform word segmentation and then POS tagging
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos
// To perform word segmentation
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg
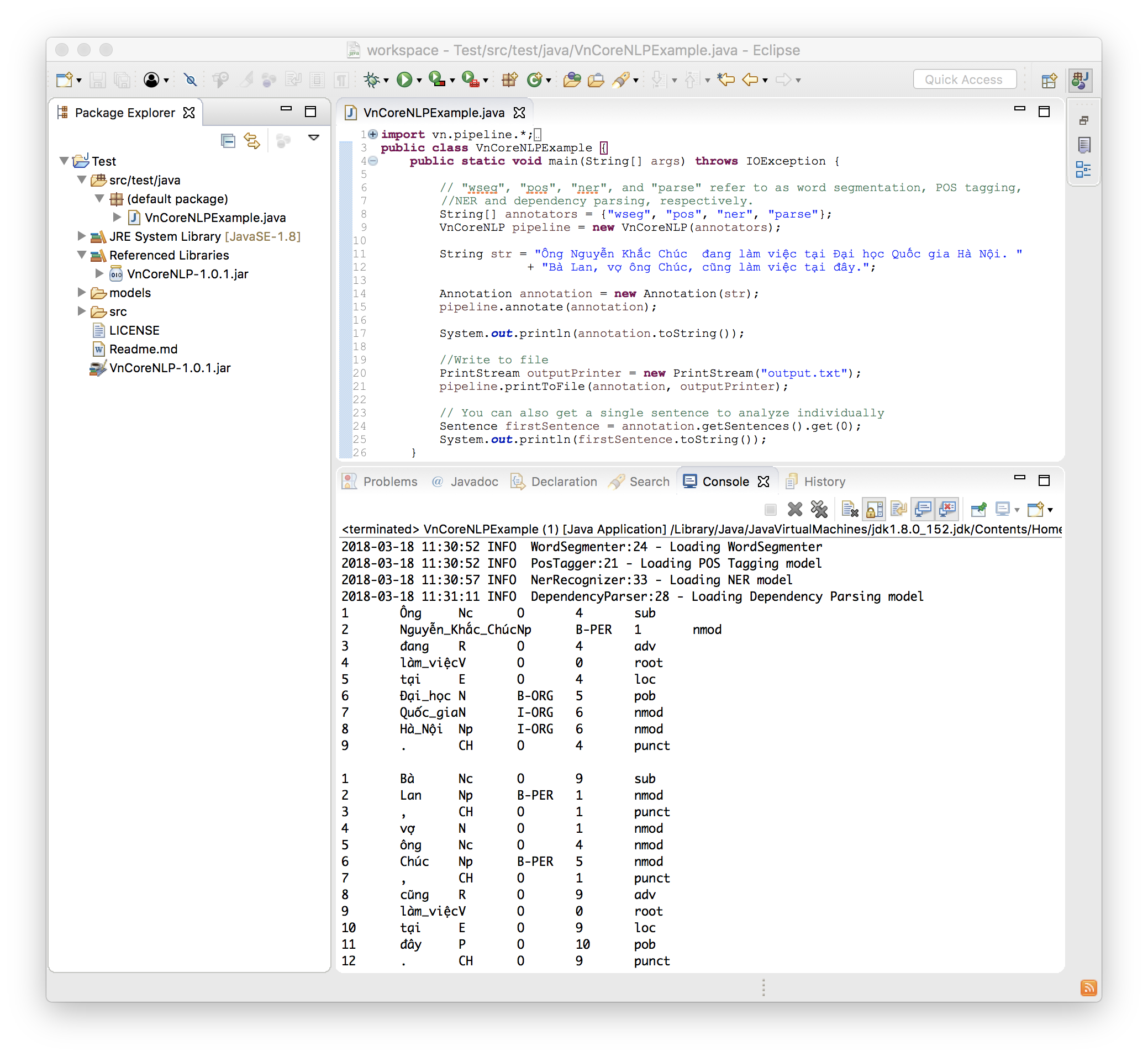
Le code suivant est un exemple simple et complet:
import vn . pipeline .*;
import java . io .*;
public class VnCoreNLPExample {
public static void main ( String [] args ) throws IOException {
// "wseg", "pos", "ner", and "parse" refer to as word segmentation, POS tagging, NER and dependency parsing, respectively.
String [] annotators = { "wseg" , "pos" , "ner" , "parse" };
VnCoreNLP pipeline = new VnCoreNLP ( annotators );
String str = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ;
Annotation annotation = new Annotation ( str );
pipeline . annotate ( annotation );
System . out . println ( annotation . toString ());
// 1 Ông Nc O 4 sub
// 2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
// 3 đang R O 4 adv
// 4 làm_việc V O 0 root
// ...
//Write to file
PrintStream outputPrinter = new PrintStream ( "output.txt" );
pipeline . printToFile ( annotation , outputPrinter );
// You can also get a single sentence to analyze individually
Sentence firstSentence = annotation . getSentences (). get ( 0 );
System . out . println ( firstSentence . toString ());
}
}
Voir VnCorenlp Open-source dans le dossier src pour les détails de l'API.
Voir les détails dans les articles [1,2,3] ci-dessus ou sur PNL-Progress.


