VnCoreNLP
v1.2
VNCORENLP는 베트남을위한 빠르고 정확한 NLP 주석 파이프 라인으로 워드 세분화 의 주요 NLP 구성 요소, POS 태그 , 명명 된 엔티티 인식 (NER) 및 종속성 구문 분석을 통해 풍부한 언어 주석을 제공합니다. 사용자는 외부 종속성을 설치할 필요가 없습니다. 사용자는 명령 줄 또는 API에서 처리 파이프 라인을 실행할 수 있습니다. VNCorenlp의 일반적인 아키텍처 및 실험 결과는 다음과 관련하여 찾을 수 있습니다.
Vncorenlp가 게시 된 결과를 생성하거나 다른 소프트웨어에 통합하는 데 사용될 때마다 논문을 인용 하십시오. 단어 세분화 또는 POS 태깅을 심층적으로 다루고 있다면 종이 [2] 또는 [3]를 각각 인용하는 것이 좋습니다.
가벼운 버전을 찾고 있다면 Vncorenlp의 워드 세분화 및 POS 태깅 구성 요소도 독립적 인 패키지 rdrsegmenter [2] 및 vnmarmot [3], RESEPEBITY로 출시되었습니다.
Java 1.8+ (전제 조건)
파일 VnCoreNLP-1.2.jar (27MB) 및 폴더 models (115MB)은 동일한 작업 폴더에 배치됩니다.
Python 3.6+ vncorenlp의 파이썬 래퍼를 사용하는 경우. 이 래퍼를 설치하려면 사용자는 다음 명령을 실행해야합니다.
$ pip3 install py_vncorenlp
이 래퍼를 만들어 준 Nguyen Linh에게 특별한 감사를드립니다!
import py_vncorenlp
# Automatically download VnCoreNLP components from the original repository
# and save them in some local working folder
py_vncorenlp . download_model ( save_dir = '/absolute/path/to/vncorenlp' )
# Load VnCoreNLP from the local working folder that contains both `VnCoreNLP-1.2.jar` and `models`
model = py_vncorenlp . VnCoreNLP ( save_dir = '/absolute/path/to/vncorenlp' )
# Equivalent to: model = py_vncorenlp.VnCoreNLP(annotators=["wseg", "pos", "ner", "parse"], save_dir='/absolute/path/to/vncorenlp')
# Annotate a raw corpus
model . annotate_file ( input_file = "/absolute/path/to/input/file" , output_file = "/absolute/path/to/output/file" )
# Annotate a raw text
model . print_out ( model . annotate_text ( "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ))기본적으로 출력은 단어 색인, 단어 양식, POS 태그, NER 레이블, 현재 단어의 헤드 인덱스 및 해당 종속성 관계 유형을 나타내는 6 개의 열로 형식화됩니다.
1 Ông Nc O 4 sub
2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
3 đang R O 4 adv
4 làm_việc V O 0 root
5 tại E O 4 loc
6 Đại_học N B-ORG 5 pob
...
단어 세분화에만 vncorenlp를 사용하는 사용자의 경우 :
rdrsegmenter = py_vncorenlp . VnCoreNLP ( annotators = [ "wseg" ], save_dir = '/absolute/path/to/vncorenlp' )
text = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây."
output = rdrsegmenter . word_segment ( text )
print ( output )
# ['Ông Nguyễn_Khắc_Chúc đang làm_việc tại Đại_học Quốc_gia Hà_Nội .', 'Bà Lan , vợ ông Chúc , cũng làm_việc tại đây .'] 다음 명령을 사용하여 vncorenlp를 실행하여 입력 원시 텍스트 코퍼스 (예 : 뉴스 컨텐츠 모음)에 주석을 달 수 있습니다.
// To perform word segmentation, POS tagging, NER and then dependency parsing
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt
// To perform word segmentation, POS tagging and then NER
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos,ner
// To perform word segmentation and then POS tagging
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg,pos
// To perform word segmentation
$ java -Xmx2g -jar VnCoreNLP-1.2.jar -fin input.txt -fout output.txt -annotators wseg
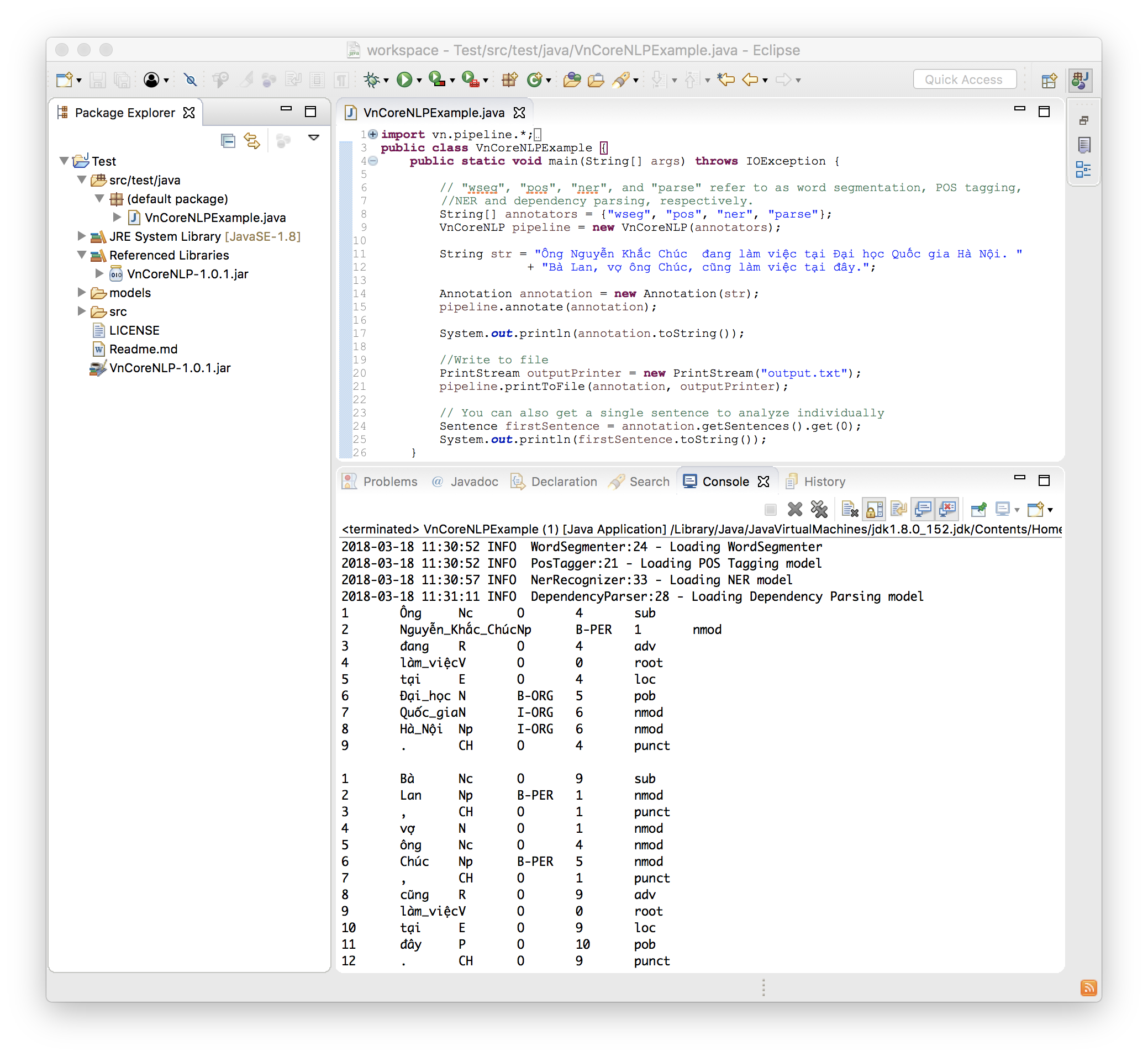
다음 코드는 간단하고 완전한 예입니다.
import vn . pipeline .*;
import java . io .*;
public class VnCoreNLPExample {
public static void main ( String [] args ) throws IOException {
// "wseg", "pos", "ner", and "parse" refer to as word segmentation, POS tagging, NER and dependency parsing, respectively.
String [] annotators = { "wseg" , "pos" , "ner" , "parse" };
VnCoreNLP pipeline = new VnCoreNLP ( annotators );
String str = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây." ;
Annotation annotation = new Annotation ( str );
pipeline . annotate ( annotation );
System . out . println ( annotation . toString ());
// 1 Ông Nc O 4 sub
// 2 Nguyễn_Khắc_Chúc Np B-PER 1 nmod
// 3 đang R O 4 adv
// 4 làm_việc V O 0 root
// ...
//Write to file
PrintStream outputPrinter = new PrintStream ( "output.txt" );
pipeline . printToFile ( annotation , outputPrinter );
// You can also get a single sentence to analyze individually
Sentence firstSentence = annotation . getSentences (). get ( 0 );
System . out . println ( firstSentence . toString ());
}
}
API 세부 사항은 폴더 src 의 vncorenlp의 오픈 소스를 참조하십시오.
위 또는 NLP 프로그램에서 논문 [1,2,3]의 세부 사항을 참조하십시오.


